腾讯大数据平台纵览
腾讯业务产品线众多,拥有海量的活跃用户,每天线上产生的数据超乎想象,必然会成为数据大户。特别是随着传统业务增长放缓,以及移动互联网时代的精细化运营,对于大数据分析和挖掘的重视程度高于以往任何时候,如何从大数据中获取高价值,已经成为大家关心的焦点问题。在这样的大背景下,为了公司各业务产品能够使用更丰富优质的数据服务,近年腾讯大数据平台得到迅猛发展。
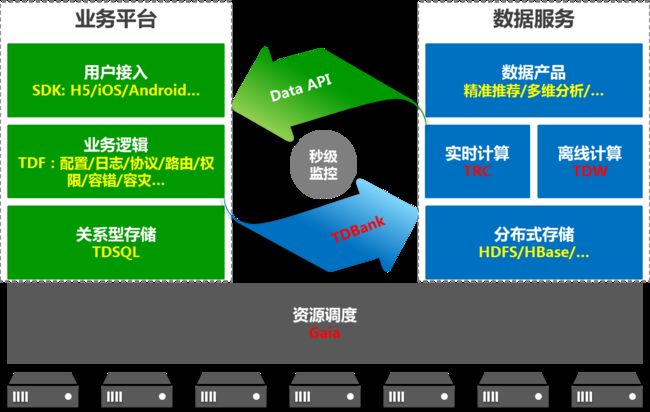
从上图可以看出,腾讯大数据平台有如下核心模块:TDW、TRC、TDBank和Gaia。简单来说,TDW用来做批量的离线计算,TRC负责做流式的实时计算,TDBank则作为统一的数据采集入口,而底层的Gaia则负责整个集群的资源调度和管理。接下来,本文会针对这四块内容进行整体介绍。
TDW(Tencent distributed Data Warehouse):腾讯分布式数据仓库。它支持百PB级数据的离线存储和计算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。目前,TDW集群总设备8400台,单集群最大规模5600台 ,总存储数据超过100PB,日均计算量超过5PB,日均Job数达到100万个。
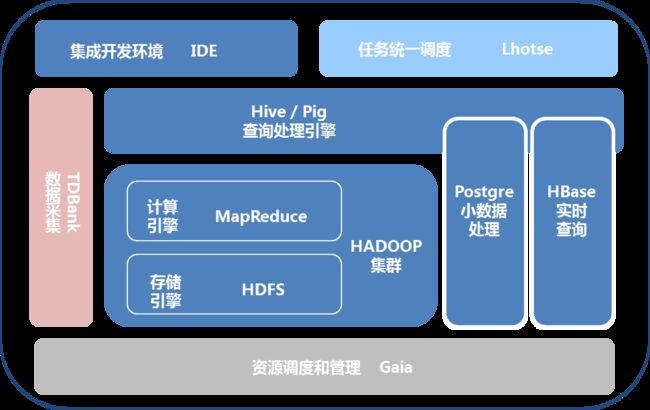
为了降低用户从传统商业数据库迁移门槛,TDW基于开源Hive进行了大量定制开发。在功能扩充方面,SQL语法兼容Oracle,实现了基于角色的权限管理、分区功能、窗口函数、多维分析功能、公用表表达式-CTE、DML-update/delete、入库数据校验等。在易用性方面,增加了基于Python的过程语言接口,以及命令行工具PLClient,并提供可视化的IDE集成开发环境,使得开发效率大幅度提升。另外,在性能优化方面也做了大量工作,包括Hash Join、按行split、Order by limit优化、查询计划并行优化等,特别是针对Hive元数据的重构,去掉了低效的JDO层,并实现元数据集群化,使系统扩展性提升明显。
为了尽可能促进数据共享和提升计算资源利用率,实施构建高效稳定的大集群战略,TDW针对Hadoop原有架构进行了深度改造。首先,通过JobTracker/NameNode分散化和容灾,解决了Master单点问题,使得集群的可扩展性和稳定性得到大幅度提升。其次,优化公平资源调度策略,以支撑上千并发job(现网3k+)同时运行,并且归属不同业务的任务之间不会互相影响。同时,根据数据使用频率实施差异化压缩策略,比如热数据lzo、温数据gz、冷数据gz+hdfs raid,总压缩率相对文本可以达到10-20倍。
另外,为了弥补Hadoop天然在update/delete操作上的不足,TDW引入PostgreSQL作为辅助,适用于较小数据集的高效分析。当前,TDW正在向着实时化发展,通过引入HBase提供了千亿级实时查询服务,并开始投入Spark研发为大数据分析加速。
TDBank(Tencent Data Bank):数据实时收集与分发平台。构建数据源和数据处理系统间的桥梁,将数据处理系统同数据源解耦,为离线计算TDW和在线计算TRC平台提供数据支持。

从架构上来看,TBank可以划分为前端采集、消息接入、消息存储和消息分拣等模块。前端模块主要针对各种数据形式(普通文件,DB增量/全量,Socket消息,共享内存等)提供实时采集组件,提供了主动且实时的数据获取方式。中间模块则是具备日接入量万亿级的基于“发布-订阅”模型的分布式消息中间件,它起到了很好的缓存和缓冲作用,避免了因后端系统繁忙或故障从而导致的处理阻塞或消息丢失。针对不同应用场景,TDBank提供数据的主动订阅模式,以及不同的数据分发支持(分发到TDW数据仓库,文件,DB,HBase,Socket等)。整个数据通路透明化,只需简单配置,即可实现一点接入,整个大数据平台可用。
另外,为了减少大量数据进行跨城网络传输,TDBank在数据传输的过程中进行数据压缩,并提供公网/内网自动识别模式,极大的降低了专线带宽成本。为了保障数据的完整性,TDBank提供定制化的失败重发和滤重机制,保障在复杂网络情况下数据的高可用。TDBank基于流式的数据处理过程,保障了数据的实时性,为TRC实时计算平台提供实时的数据支持。目前,TDBank实时采集的数据超过150+TB/日(约5000+亿条/日),这个数字一直在持续增长中,预计年底将超过2万亿条/日。
TRC(Tencent Real-time Computing):腾讯实时计算平台。作为海量数据处理的另一利器,专门为对时间延敏感的业务提供海量数据实时处理服务。通过海量数据的实时采集、实时计算,实时感知外界变化,从事件发生、到感知变化、到输出计算结果,整个过程中秒级完成。

TRC是基于开源的Storm深度定制的流式处理引擎,用Java重写了Storm的核心代码。为了解决了资源利用率和集群规模的问题,重构了底层调度模块,实现了任务级别的权限管理、资源分配、资源隔离,通过和Gaia这样的资源管理框架相结合,做到了根据线上业务实际利用资源的状况,动态扩容&缩容,单集群轻松超过1000台规模。为了提高平台的易用性和可运维性,提供了类SQL和Pig Latin这样的过程化语言扩展,方便用户提交业务,提升接入效率,同时提供系统级的指标度量,支持用户代码对其扩展,实时监控整个系统运营环节。另外将TRC的功能服务化,通过REST API提供PaaS级别的开放,用户无需了解底层实现细节就能方便的申请权限,资源和提交任务。
目前,TRC日计算次数超过2万亿次,在腾讯已经有很多业务正在使用TRC提供的实时数据处理服务。比如,对于广点通广告推荐而言,用户在互联网上的行为能实时的影响其广告推送内容,在用户下一次刷新页面时,就提供给用户精准的广告;对于在线视频,新闻而言,用户的每一次收藏、点击、浏览行为,都能被快速的归入他的个人模型中,立刻修正视频和新闻推荐。
Gaia:统一资源调度平台。Gaia,希腊神话中的大地之神,是众神之母,取名寓意各种业务类型和计算框架都能植根于“大地”之上。它能够让应用开发者像使用一台超级计算机一样使用整个集群,极大地简化了开发者的资源管理逻辑。Gaia提供高并发任务调度和资源管理,实现集群资源共享,具有很高的可伸缩性和可靠性,它不仅支持MR等离线业务,还可以支持实时计算,甚至在线service业务。

为了支撑单集群8800台甚至更大规模,Gaia基于开源社区Yarn之上自研Sfair (Scalable fair scheduler)调度器,优化调度逻辑,提供更好的可扩展性,并进一步增强调度的公平性,提升可定制化,将调度吞吐提升10倍以上。为了满足上层多样化的计算框架稳定运行,Gaia除了CPU、Mem的资源管理之外,新增了Network IO,Disk space,Disk IO等资源管理维度,提高了隔离性,为业务提供了更好的资源保证和隔离。同时,Gaia开发了自己的内核版本,调整和优化CPU、Mem资源管理策略,在兼容线程监控的前提下,利用cgroups,实现了hardlimit+softlimit结合的方式,充分利用整机资源,将container oom kill机率大幅降低。另外,丰富的API也为业务提供了更便捷的容灾、扩容、缩容、升级等方式。
基于以上几大基础平台的组合联动,可以打造出了很多的数据产品及服务,如上面提到的精准推荐就是其中之一,另外还有诸如实时多维分析、秒级监控、腾讯分析、信鸽等等。除了一些相对成熟的平台之外,我们还在进行不断的尝试,针对新的需求进行更合理的技术探索,如更快速的交互式分析、针对复杂关系链的图式计算。此外,腾讯大数据平台的各种能力及服务,还将通过TOD(Tencent Open Data)产品开放给外部第三方开发者。
作者简介
刘煜宏(ehomeliu):拥有10年以上的电信行业及互联网行业的从业经验,现就职于腾讯数据平台部,是腾讯实时数据接入平台(TDBank)及实时计算平台(TRC)的负责人,在大数据接入、计算及分析等方面有丰富经验。