GIS+=地理信息+云计算技术——SPARK for IntelliJ IDEA 开发环境部署
--------------------------------------------------------------------------------------
版权所有:超图研究所(www.supermap.com)
Blog: http://blog.csdn.net/chinagissoft
QQ群:16403743
宗旨:专注于"GIS+"前沿技术的研究与交流,将云计算技术、大数据技术、容器技术、物联网与GIS进行深度融合,探讨"GIS+"技术和行业解决方案
转载说明:文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
--------------------------------------------------------------------------------------
SPARK开发环境部署
前言
在之前的文章中《Spark集群部署》中已经在OpenStack虚拟机环境下部署了由三个虚拟主机组成的Spark集群。在此基础上支持通过Spark Shell、Spark Submit、pyspark等命令执行Spark自带的示范程序。为了更方便的熟悉OpenStack的开发,并通过代码调试来测试Spark的功能,我们在进一步探究Spark功能之前,首先对Spark的开发环境进行了部署,下面将部署开发环境的过程做一介绍。
开发环境部署
以往的Java开发,我们习惯于在Windows上开发或者编译,然后把程序编译的工程或者Jar包拷贝到Linux主机上,在Linux环境下部署并运行。因此在初学Spark开发的时候也考虑采用这种方式,但经过一段时间的实践,虽然也找到了一些在windows环境下搭建开发环境的方法(有兴趣可以参考:http://ju.outofmemory.cn/entry/94851),但最终还是放弃了,主要原因是为了能更方便部署和调试,毕竟Windows和Linux系统的环境配置、文件目录以及各个节点之间的访问都不是很方便,而将最终的环境是建立在之前部署的三个节点的Spark集群的基础上,额外配置了一个带有图形界面的Ubuntu虚拟机,作为开发和调试的节点。系统部署结构如下:
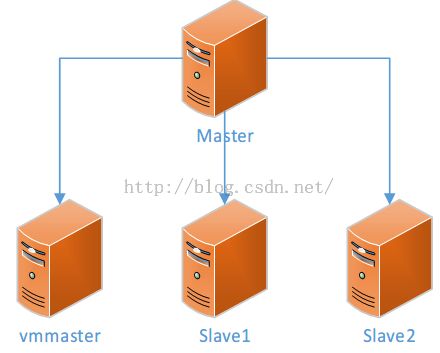
Master,Slave1,Slave2是在之前博客《Spark集群部署》介绍过的Spark集群节点。这三台节点是部署在OpenStack虚拟机环境中的,物理硬件是高性能服务器。vmmaster是用于自己开发的虚拟机,部署在VMware 10上,物理硬件是个人的笔记本电脑。四个节点都统一使用Ubuntu,并通过局域网相互链接。
确定了部署结构之后,就可以专注开发环境的搭建了,开发节点vmmaster上安装的软件主要是IntelliJ IDEA。
下载地址:https://download.jetbrains.com/idea/ideaIU-15.0.3.tar.gz
破解方法网上有很多就不介绍了。
具体操作:
1.安装JDK7
2.安装Scala2.10.x(目前推荐2.10,先不要用2.11,最后解释)
3.下载解压并破解IDEA
4.运行IDEA,并安装插件,依次选择“Configure”–>“Plugins”–>“Browse repositories”,输入scala,然后安装即可


这里已经安装过了,否则会提示install的选项。
5.配置开发环境
在intelliJ IDEA中创建scala project,名称为test。
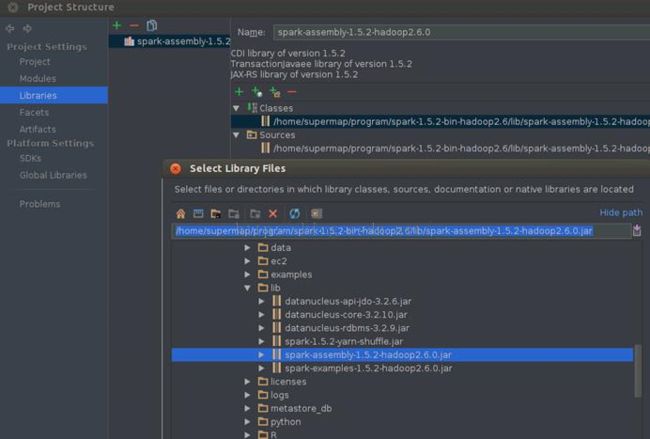
并依次选择“File”–>“project structure” –>“Libraries”,选择“+”,将spark-hadoop对应的包导入,比如导入spark-assembly-1.5.2-hadoop2.6.0.jar(只需导入该jar包,其他不需要)。
如果IDE没有识别scala库,则需要以同样方式将scala库导入。同时还要确认jdk的配置是否正确,可以在以下界面中查看jdk和scala的配置。
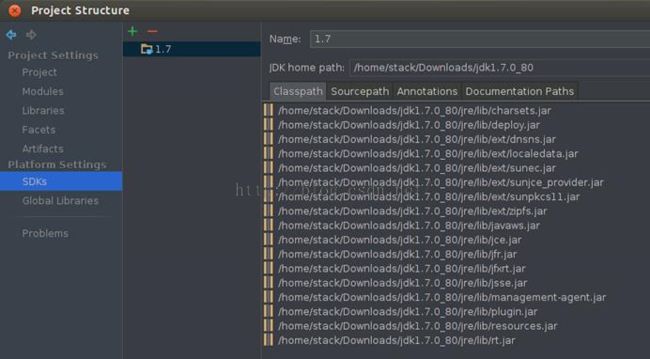
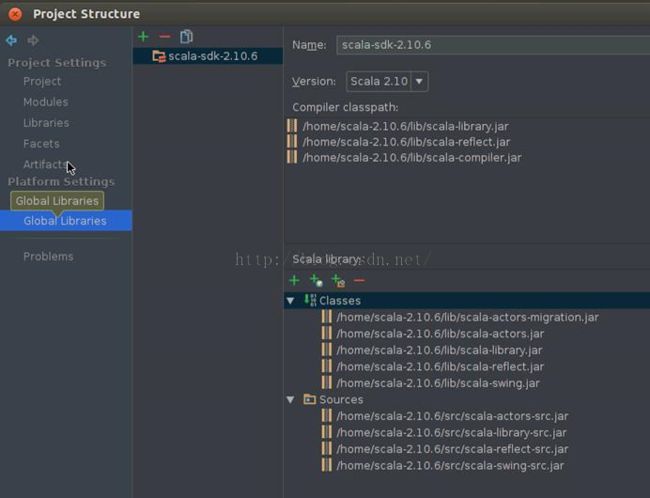
6.开发
下面开始开发,这里就不用helloworld做事示范了,而是直接使用示范程序。
直接将spark的示范程序SprkPi.scala和RDDRelation.scala文件拷贝到工程目录src下。
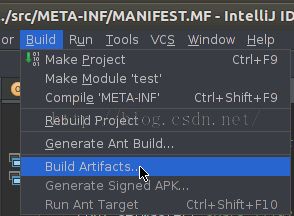
为了测试程序在Spark集群环境下的分布式计算的效果,需要把程序打成jar包,才能运行在spark集群中,可以按照以下步骤操作:依次选择“File”–>“ProjectStructure” –> “Artifact”,选择“+”–>“Jar”–>“From Modules with dependencies”,选择main函数,并在弹出框中选择输出jar位置,并选择“OK”。


最后依次选择“Build”–>“Build Artifact”编译生成jar包。具体如下图所示。
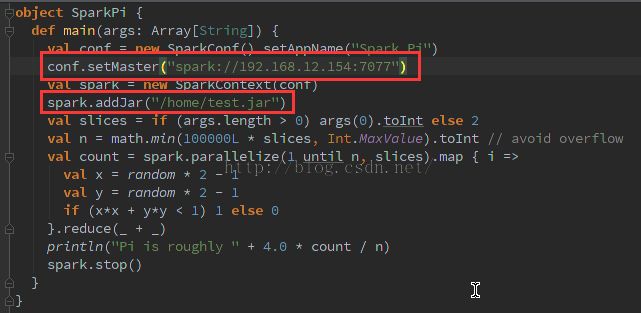
修改代码,注意要加入红框中的两行代码才能使程序在集群环境中运行。因为示范程序默认是本地执行,只有设置下面两行代码才能让程序运行在集群环境中,并通过addJar方法可以让worker找到依赖的.jar文件。
运行并查看结果

总结
由于开发环境是笔记本的虚拟机,网络为普通办公网络,编译生成的test.jar有180m,在执行过程中可能会产生比较大的网络io导致性能有所影响。同样的环境下在master上直接运行SparkPi.scala时间在3s。所以后面会实际物理环境中测试来体现Spark在分布式多节点状态下的性能优势,在此大家只要了解如何部署开发环境和进行代码运行调试的过程就可以了。
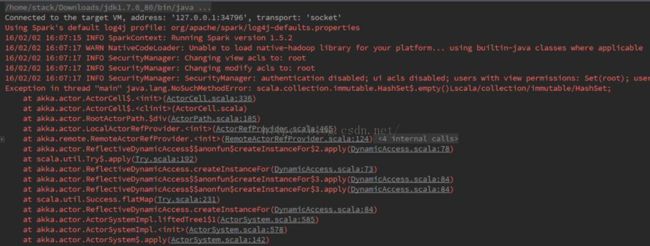
另外,对于前面所说的scala版本的问题,由于已经下载使用了Spark 1.5.2,而在下载Scala时选择了最新的2.11。在开发运行过程中会出现以下错误。通过研究发现是scala版本兼容问题,解决办法是重新下载scala2.10,然后删除scala 2.11目录,修改环境配置以及scala工程中对scala版本的引用,重新编译运行之后问题解决了。Spark 1.5支持scala 2.11但需要用户自己下载Spark源码再基于Scala 2.11重新编译,由于这里测试使用的是预编译版本,所以会造成版本不一致导致的问题。