Python简单实现基于VSM的余弦相似度计算
这篇文章主要是先叙述VSM和余弦相似度相关理论知识,然后引用阮一峰大神的例子进行解释,最后通过Python简单实现百度百科和互动百科Infobox的余弦相似度计算。
一. 基础知识
第一部分参考我的文章: 基于VSM的命名实体识别、歧义消解和指代消解
第一步,向量空间模型VSM
向量空间模型(Vector Space Model,简称VSM)表示通过向量的方式来表征文本。一个文档(Document)被描述为一系列关键词(Term)的向量。
简言之,判断一篇文章是否是你喜欢的文章,即将文章抽象成一个向量,该向量由n个词Term组成,每个词都有一个权重(Term Weight),不同的词根据自己在文档中的权重来影响文档相关性的重要程度。
Document = { term1, term2, …… , termN }
Document Vector = { weight1, weight2, …… , weightN }
选取特征词时,需要降维处理选出有代表性的特征词,包括人工选择或自动选择。
第二步,TF-IDF
特征抽取完后,因为每个词语对实体的贡献度不同,所以需要对这些词语赋予不同的权重。计算词项在向量中的权重方法——TF-IDF。
它表示TF(词频)和IDF(倒文档频率)的乘积:


由于“是”“的”“这”等词经常会出现,故需要IDF值来降低其权值。所谓降维,就是降低维度。具体到文档相似度计算,就是减少词语的数量。常见的可用于降维的词以功能词和停用词为主(如:"的","这"等),事实上,采取降维的策略在很多情况下不仅可以提高效率,还可以提高精度。
最后TF-IDF计算权重越大表示该词条对这个文本的重要性越大。
第三步,余弦相似度计算
这样,就需要一群你喜欢的文章,才可以计算IDF值。依次计算得到你喜欢的文章D=(w1, w2, ..., wn)共n个关键词的权重。当你给出一篇文章E时,采用相同的方法计算出E=(q1, q2, ..., qn),然后计算D和E的相似度。
计算两篇文章间的相似度就通过两个向量的余弦夹角cos来描述。文本D1和D2的相似性公式如下:
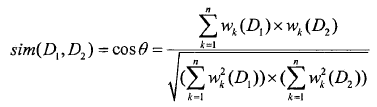
计算过后,就可以得到相似度了。我们也可以人工的选择两个相似度高的文档,计算其相似度,然后定义其阈值。同样,一篇文章和你喜欢的一类文章,可以取平均值或寻找一类文章向量的中心来计算。主要是将语言问题转换为数学问题进行解决。
缺点:计算量太大、添加新文本需要重新训练词的权值、词之间的关联性没考虑等。其中余弦定理为什么能表示文章相似度间参考资料。
二. 实例解释
第二部分主要参考阮一峰大神的个人博客,举例解释VSM实现余弦相似度计算,强烈推荐大家去阅读阮神的博客:TF-IDF与余弦相似性的应用
此部分为转载,阮神举了一个简单的例子(后面第三部分是相对复杂的例子):
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
第二步,列出所有的词。
我,喜欢,看,电视,电影,不,也。
第三步,计算词频。
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
第四步,写出词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到这里,问题就变成了如何计算这两个向量的相似程度。
使用余弦这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
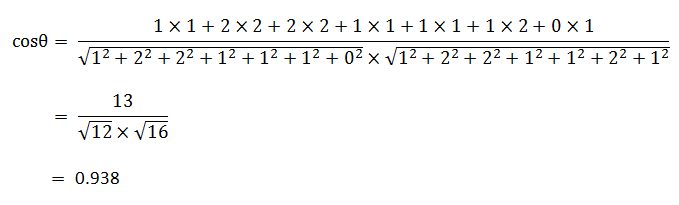
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可用它。
PS:这部分内容完全照搬阮神的博客,因为真的讲得通俗易懂,我都有点爱不释手了。如果觉得版权不妥之处,我可以删除,同时推荐大家阅读他的更多文章。阮一峰个人博客链接:http://www.ruanyifeng.com/home.html
三. 代码实现
最后就简单讲解我的Python实现百度百科和互动百科关于消息盒InfoBox的相似度计算。其中爬虫部分参考我的博客:
[Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒

我已经通过Selenium爬取了所有“国家5A级景区”的InfoBox消息盒,并使用开源分词工具进行了分词处理,“故宫”数据如下所示:

1.分别统计两个文档的关键词,读取txt文件,CountKey()函数统计
2.两篇文章的关键词合并成一个集合MergeKey()函数,相同的合并,不同的添加
3.计算每篇文章对于这个集合的词的词频 TF-IDF算法计算权重,此处仅词频
4.生成两篇文章各自的词频向量
5.计算两个向量的余弦相似度,值越大表示越相似
# -*- coding: utf-8 -*-
import time
import re
import os
import string
import sys
import math
''' ------------------------------------------------------- '''
#统计关键词及个数
def CountKey(fileName, resultName):
try:
#计算文件行数
lineNums = len(open(fileName,'rU').readlines())
print u'文件行数: ' + str(lineNums)
#统计格式 格式<Key:Value> <属性:出现个数>
i = 0
table = {}
source = open(fileName,"r")
result = open(resultName,"w")
while i < lineNums:
line = source.readline()
line = line.rstrip('\n')
print line
words = line.split(" ") #空格分隔
print str(words).decode('string_escape') #list显示中文
#字典插入与赋值
for word in words:
if word!="" and table.has_key(word): #如果存在次数加1
num = table[word]
table[word] = num + 1
elif word!="": #否则初值为1
table[word] = 1
i = i + 1
#键值从大到小排序 函数原型:sorted(dic,value,reverse)
dic = sorted(table.iteritems(), key = lambda asd:asd[1], reverse = True)
for i in range(len(dic)):
#print 'key=%s, value=%s' % (dic[i][0],dic[i][1])
result.write("<"+dic[i][0]+":"+str(dic[i][1])+">\n")
return dic
except Exception,e:
print 'Error:',e
finally:
source.close()
result.close()
print 'END\n\n'
''' ------------------------------------------------------- '''
#统计关键词及个数 并计算相似度
def MergeKeys(dic1,dic2):
#合并关键词 采用三个数组实现
arrayKey = []
for i in range(len(dic1)):
arrayKey.append(dic1[i][0]) #向数组中添加元素
for i in range(len(dic2)):
if dic2[i][0] in arrayKey:
print 'has_key',dic2[i][0]
else: #合并
arrayKey.append(dic2[i][0])
else:
print '\n\n'
test = str(arrayKey).decode('string_escape') #字符转换
print test
#计算词频 infobox可忽略TF-IDF
arrayNum1 = [0]*len(arrayKey)
arrayNum2 = [0]*len(arrayKey)
#赋值arrayNum1
for i in range(len(dic1)):
key = dic1[i][0]
value = dic1[i][1]
j = 0
while j < len(arrayKey):
if key == arrayKey[j]:
arrayNum1[j] = value
break
else:
j = j + 1
#赋值arrayNum2
for i in range(len(dic2)):
key = dic2[i][0]
value = dic2[i][1]
j = 0
while j < len(arrayKey):
if key == arrayKey[j]:
arrayNum2[j] = value
break
else:
j = j + 1
print arrayNum1
print arrayNum2
print len(arrayNum1),len(arrayNum2),len(arrayKey)
#计算两个向量的点积
x = 0
i = 0
while i < len(arrayKey):
x = x + arrayNum1[i] * arrayNum2[i]
i = i + 1
print x
#计算两个向量的模
i = 0
sq1 = 0
while i < len(arrayKey):
sq1 = sq1 + arrayNum1[i] * arrayNum1[i] #pow(a,2)
i = i + 1
print sq1
i = 0
sq2 = 0
while i < len(arrayKey):
sq2 = sq2 + arrayNum2[i] * arrayNum2[i]
i = i + 1
print sq2
result = float(x) / ( math.sqrt(sq1) * math.sqrt(sq2) )
return result
''' -------------------------------------------------------
基本步骤:
1.分别统计两个文档的关键词
2.两篇文章的关键词合并成一个集合,相同的合并,不同的添加
3.计算每篇文章对于这个集合的词的词频 TF-IDF算法计算权重
4.生成两篇文章各自的词频向量
5.计算两个向量的余弦相似度,值越大表示越相似
------------------------------------------------------- '''
#主函数
def main():
#计算文档1-百度的关键词及个数
fileName1 = "BaiduSpider.txt"
resultName1 = "Result_Key_BD.txt"
dic1 = CountKey(fileName1, resultName1)
#计算文档2-互动的关键词及个数
fileName2 = "HudongSpider\\001.txt"
resultName2 = "HudongSpider\\Result_Key_001.txt"
dic2 = CountKey(fileName2, resultName2)
#合并两篇文章的关键词及相似度计算
result = MergeKeys(dic1, dic2)
print result
if __name__ == '__main__':
main()
其中由于只需要计算InfoBox消息盒的相似度,不会存在一些故不需要计算TF-IDF值,通过词频就可以表示权重,在代码中简单添加循环后,可以计算百度百科的“故宫”与互动百科不同实体的相似度,运行结果如下所示,可以发现“北京故宫”和“故宫”相似度最高。这也是简单的实体对齐。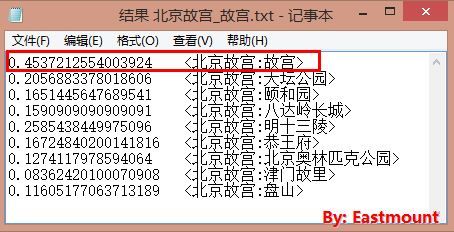
最后是参考和推荐一些相关的文章关于VSM和余弦相似度计算:
TF-IDF与余弦相似性的应用(一):自动提取关键词 - 阮一峰
TF-IDF与余弦相似性的应用(二):找出相似文章 - 阮一峰
Lucene学习之计算相似度模型VSM(Vector Space Model)
VSM向量空间模型对文本的分类以及简单实现 - java
话说正确率、召回率和F值 - silence1214
向量空间模型(VSM) - wyy_820211网易博客
向量空间模型(VSM)的余弦定理公式(cos) - live41
向量空间模型文档相似度计算实现(C#)- felomeng
向量空间模型(VSM)在文档相似度计算上的简单介绍 - felomeng
隐马尔科夫模型学习总结.pdf - a123456ei
向量空间模型VSM - ljiabin
(By:Eastmount 2015-11-18 深夜5点 http://blog.csdn.net/eastmount/)