mysql中的联合查询
为了方便明显的看出效果,我们先建立一张新闻表(news),表的结构如下:
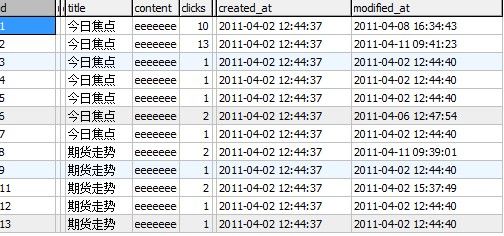
现在我要去对这批数据进行排序,排序规则如下
1)点击率最高且title为今日焦点的放在最上面。
2)其余的按照更新时间排序
一、第一个想到的就是用unoin进行联合查询:
select * from news where title=“今日焦点” order by click desc
unoin all
select * from news order by modified_at desc
结果提示:
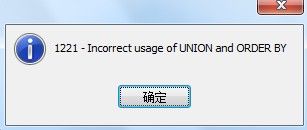
原来 为了对单个SELECT 使用ORDER BY 或LIMIT ,应把子句放入圆括号中。于是把语句改为
(select * from news where title=“今日焦点” order by click desc)
unoin all
(select * from news order by modified_at desc)
二、查询之后发现有重复的数据 ,因为第二个查询查询的是所有的记录,第一个查询是部分记录。
1)在第二个select 查询中做限定,查出title不为sql的所有语句
2)或者吧unoin all换成unoin。因为unoin会将联合查询后的结果集得重复记录去掉
三、你发现结果集并不像你想象的那样排序
你想要的排序结果是(2、1、6、3、4、5、7、11、9、12、13、8)
但是查询出来的排序结果是(1、2、3、4、5、6、7、8、9、11、12、13)
她貌似对结果集按照id进行了重新排序,原因是: 圆括号中用于单个SELECT 语句的ORDER BY 只有当与LIMIT 结合后,才起作用。否则,ORDER BY 被优化去除。
(select * from news where title=“今日焦点” order by click desc limit 100)
unoin all
(select * from news order by modified_at desc limit 100)
这样就可以获取到你要的结果集了。
但是问题是我的limit值到底要设置为多大了,有一点可以肯定的,根据开头说的需求,这个limit的值最好是比数据库中记录的条数大,不然查询出来的数据会不完整。这样也就限制了整个sql语句的灵活性。但是根据官方文档的描述,如果选用unoin联合查询的话,必须要这样做了。其他方法我一时间还想不出来。