区位码、国标码与机内码
在用UltraEdit分析文件的时候,突然对汉字的16进制形式感起了兴趣,于是便摸索着整理了这样一篇文章。从各种百科整理来的,加入了我自己的一些理解。希望能为大家提供一些帮助。
1980年,为了使每个汉字有一个全国统一的代码,我国颁布了汉字编码的国家标准:GB 2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础。收录了6763个汉字。
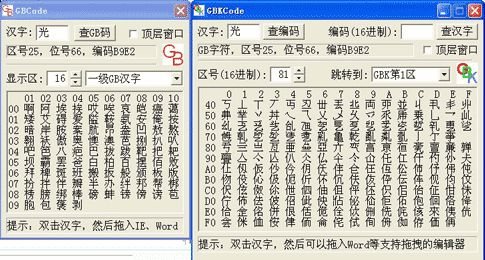
国标码,是指国家汉字标准代码。所有的国标汉字与符号组成一个94×94的矩阵。在此方阵中,每一行称为一个“区”,每一列称为一个“位”,因此,这个方阵实际上组成了一个有94个区(区号分别为01到94)、每个区内有94个位(位号分别为01到94)的汉字字符集。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。
在汉字的区位码中,高两位为区号,低两位为位号(前两位叫区码,后两位叫位码)。
信息交换用汉字编码字符集和汉字输入编码之间的关系是:根据不同的汉字输入方法,通过必要的设备向计算机输入汉字的编码,计算机接收之后,先转换成信息交换用汉字编码字符,这时计算机就可以识别并进行处理;汉字输出是先把机内码转成汉字编码,再发送到输出设备。
百度百科:国家标准代码、信息交换用汉字编码字符集、内码、机内码、汉字的编码与存储……
较常见的国家汉字标准代码列表
国家标准强制标准冠以“GB”。推荐标准冠以“GB/T”。国家推荐标准以 "/T" 来表示并非强制执行。
- GB 2312 - 80:信息交换用汉字编码字符集 基本集(又称为GB0)
- GB 13000 - 93:信息技术 通用多八位编码字符集(UCS)第一部分
- GB 18030 - 2000:信息技术 信息交换用汉字编码字符集 基本集的扩充
由于GB 2312-80只收录了6763个汉字,未能覆盖繁体中文字、部分人名、方言、古汉语等方面出现的罕用字,所以后来发布了许多辅助集。中华人民共和国国家标准总局于2000年推出强制性的GB 18030-2000标准,总共收录70244字(包括繁体字等等)。于2001年8月31日后发布或出厂的产品,必须符合GB 18030-2000的相关要求。
为什么要有“内码”?
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,如“保”字,国标码为31H和23H,而西文字符“1”和“#”的ASCII也为31H和23H,现假如内存中有两个字节为31H和23H,这到底是一个汉字,还是两个西文字符“1”和“#”于是就出现了二义性,显然,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,如:由上面我们知道,“保”字的国标码为3123H,前字节为00110001B,后字节为00100011B,高位改1为10110001B和10100011B 即为B1A3H,因此,“保”字的机内码就是B1A3H。显然,汉字机内码的每个字节都大于128,这就解决了与西文字符的ASCII码冲突的问题。
区位码、国标码、机内码的转换
区位码的区码和位码均采用从01到94的十进制,国标码采用十六进制的21H到73H(数字后加H表示其为十六进制数);把换算成十六进制的区位码加上2020H(十六进制数20即十进制数32),就得到国标码。国标码加上8080H(十六进制数80即十进制数128),就得到常用的计算机机内码。注意这里的“加”不是简单相加,而是区码和位码分开相加,看下面的例子:
“大”字的区位码为2083,区号为20,位号为83。
- 将区位号2083转换为十六进制表示为1453H(十进制20变成十六进制14,十进制83变成十六进制53)
- 1453H+2020H=3473H,得到国标码3473H(14+20得34,53+20得73)
- 3473H+8080H=B4F3H,得到计算机机内码为B4F3H(34+80得B4,73+80得F3)
这样,区位码2083便转换为了机内码B4F3。在UltraEdit中测试了下,的确是这样(废话)
既然是得到机内码,其实也可以一次性得到。像这样:
- 将“大”字的区码20和位码83分别加上160(即前面提到的十进制数32+128=160)
- 将得到的180和243分别转换为十六进制B4和F3,得到机内码B4F3H