Spark Streaming初探
Spark Streaming初探
Spark Streaming是一个基于Spark核心的流式计算的扩展。
主要有以下两个特点:
1. 高吞吐量
2. 容错能力强
1.原理:
Spark Streaming支持多种数据源的输入,向Flume,Kafka,HDFS,ZeroMQ,Twitter以及原始的TCP sockets。
数据可以使用Spark的RDD的Transformation,也可以应用很多Spark内置的机器学习算法,还有图计算。
以下是Spark官方截图:

1.1主要实现原理
Spark Streaming会接收线上的数据流,然后将数据流分成独立的批次。
然后Spark Streaming Engine就会分别处理这些独立的批数据,最后生成分批的结果。

Spark Streaming 提出了一种高度的抽象叫 DStream(discretized stream)离散流,代表了一段持续的数据流。
创建DStream可以从文件创建,也可以从Kafka或者Flume,代表了一个RDD的序列。
2.WorkCount流式计算实例
摘自官方例子的代码:
package org.apache.spark.streaming.examples
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevel
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage: NetworkWordCount <master> <hostname> <port>\n" +
"In local mode, <master> should be 'local[n]' with n > 1")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1),
System.getenv("SPARK_HOME"), StreamingContext.jarOfClass(this.getClass))
// Create a NetworkInputDStream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
首先我们需要建立一个发送数据的端口连接:
nc -lk 9999进程会阻塞,当我们输入数据的时候,会向9999这个端口发送我们的数据。
首先我们先创建一个Spark Streaming engine
现在我们需要Spark Streaming Engine来监听这个端口。
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1),
System.getenv("SPARK_HOME"), StreamingContext.jarOfClass(this.getClass))
这里args(1)就是ip, args(2)就是port
我们看到这里实践是创建了一个socketTextStream,其实还有很多选择。
StorageLevel是Memory_only,很明显,创建的是一个RDD
val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY_SER)
WordCount的逻辑很简单,这里不赘述。
最后要启动Spark Streaming要使用这句:
ssc.start() ssc.awaitTermination()
运行结果:
1.在终端输入
# nc -lk 9999 what is your name ? my name is sheng li ~ haha
------------------------------------------- Time: 1397470893000 ms ------------------------------------------- (is,1) (what,1) (your,1) (?,1) (name,1) ------------------------------------------- Time: 1397470894000 ms
------------------------------------------- Time: 1397470962000 ms ------------------------------------------- (haha,1) (my,1) (is,1) (~,1) (li,1) (sheng,1) (name,1)
大致流程:
1.Spark Streaming Engine 监听9999这个端口发送的信息,当作数据源,其实是一个RDD。
2.这里会有一个lines是一个DStream,是一个不可变的分布式弹性数据集。
lines实际上是带一个带版本的RDD,每一个时刻它代表的是不同的数据,比如第一个输入的是what is your name,那么这个时刻Lines代表的是这句话。
第二次输入的是my name is shengli ~ haha 这是另一个时刻的Lines。
3.DStream可以应用和RDD一样的API,其中Transformation变形成其它的RDD。
这里会变成Words DStream。
4.最后计算完成,输出wordCounts.print()。
总结:
实际上每次的input都是一个RDD@time N
每个RDD@time N 都可以被transform成其它的RDD进行处理。
看起来相当简单。
再来看下官方的解释图,会很好的理解:

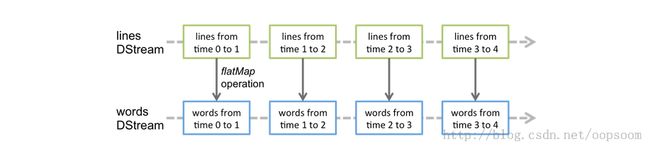
参考文献:http://spark.apache.org/docs/0.9.1/streaming-programming-guide.html
原创文章,转载注明出处http://blog.csdn.net/oopsoom/article/details/23692079