写这篇文章的起因是看到何登成博士发的一个微博问题,如下:
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第1张图片](http://img.e-com-net.com/image/info5/90db37ff64e94a2c9ace2f2989705b4d.jpg)
自己想不太明白,顺下找了他以前分享的一些资料和其他人的博客阅读,在这里做个笔记,内容主要来自何博的ppt。关于微博问题的讨论最后再说。
实际上问题所涉及到的知识点非常多,我也有很多还没理解,这里尽量省去细枝末节,更详细的内容请参考附录链接。
一. Cache Coherence
1. What is a cache? cache line ?
cache : Small, fast storage used to improve average access time to slow memory.
cache line : The minimum amount of cache which can be loaded or stored to memory
2. Cache Write Policy
– Write Back
•脏数据,写出到Cache;
– Write Through
•脏数据,写穿到Memory;
– Write Invalidate(大部分系统采用)
Write时,同时发出Invalidate消息,使得所有其他CPU L1/L2 Cache中同一Cache Line失效
– Write Update
•Write时,同时更新其他CPU L1/L2 Cache中同一Cache Line;
3.
Cache Coherence
在多核处理器上,由于每个核都有自己的cache,如果有多层cache,如L3往往是多核共享的。所以会存在Cache Coherence 问题,
False cache line sharing:When one processor modifies a value in its cache, other processors cannot use the old value anymore.
That memory location will be invalidated in all of the caches. Furthermore, since caches operate on the granularity of cache lines and
not individual bytes, the entire cache line will be invalidated in all caches!
Cache Coherence Protocol (MESI, MOESI),作用于CPU Cache与Memory层面,若操作的数据在Register,或者是Register与L1
Cache之间(下面会提到的Store Buffer,Load Buffer),则这些数据不会参与Cache Coherence协议。
二、Atomic Operation
•An operation acting on shared memory is atomic if it completes in a single step relative to other threads. When an atomic store is performed on a shared variable, no other thread can observe the modification half-complete. When an atomic load is performed on a shared variable, it reads the entire value as it appeared at a single moment in time.
1. 高级语言与汇编指令的映射
高级语言(如:C/C++),被编译为汇编语言,才能够被执行。因此,高级语言与汇编语言之间,存在着几种简单的映射关系。
•Simple Write
– Write to Memory

– Atomic
•Simple Read
–Read from Memory
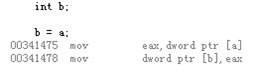
–Atomic (
注:实际上这里是指将a 读取到寄存器eax是atomic的,赋值语句b=a 包括两条汇编命令,不是atomic的)
•Read-Modify-Write(RMW)
– Read from Memory
– Modify

– Write to Memory
– Non-Atomic
•Read/Write 64 Bits on 32 Bits Systems
– Write:Non-Atomic
– Read:Non-Atomic
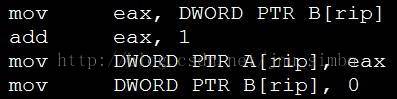
2. Non-Atomic 的危害(在32位机上读写64位数如上图)
•Half Write
– mov dword ptr [c], 2 执行后,会短暂出现c的half write现象;
•Half Read
–若c 出现half write,则读取c 会出现half read现象;
•Composite Write
– 两个线程同时write c,一个完成,一个half write,则c的值,来自线程1,2两个write操作的组合;
•危害
– 出现Half Read,会导致程序判断逻辑出错;出现Composite Write,会导致数据出错
3. 如何消除Non-Atomic Read/Write?
•Intel/AMD CPU 平台方面 (参考各CPU白皮书)
– Aligned 2-,4-Byte Simple Read/Write -> Atomic
– Aligned 8-Byte,CPU型号判断-> 一般为Atomic
– Unaligned 2-, 4-, 8-Byte,CPU型号判断 -> 尽量少用
•RMW Operation
尽量使用系统自带的,或者是提供的原子操作函数;这些函数,对不同CPU类型,做了较好的封装,更加易用;
– Windows Synchronization Functions
– Linux Built-in Functions for Atomic Memory Access
– C++ 11 Atomic Operations Library
4. Atomic Instructions and Lock
•Atomic Instructions
– 常见指令:CMPXCHG,XCHG,XADD,...
– CMPXCHG(compare-and-exchange)

•将Operand1(Reg/Mem)中的内容与EAX比较,若相等,则拷贝Operand2(Reg)中的内容至Operand1;若不等,
则将Operand2中的数据写入EAX;
•一个Atomic RMW操作,若Operand1为Memory,则CMPXCHG指令还需要Lock指令配合 (Lock prefix);
•Lock Instruction
– Lock指令是一个前缀,可以用在很多指令之前,代表当前指令
所操作的内存(Memory),在指令执行期间,只能被当前CPU所用;
– Intel’s Description about Lock Instruction
– Lock with CMPXCHG
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第3张图片](http://img.e-com-net.com/image/info5/e513275983094478b3e518d2547c50a7.jpg)
- x++可以用汇编来写 : __asm LOCK inc dword ptr[x]
三、Memory Ordering(Reordering)
1.Reordering
Reads and writes do not always happen in the order that you have written them in your code.
用户程序,无论是在编译期间,还是在执行期间,都会产生Reordering;
•Why Reordering
– Performance
•Reordering Principle
– In single threaded programs from the programmer's point of view, all operations appear to have been executed in the order specified, with all inconsistencies hidden by hardware.
–- 一段程序,在Reordering前,与Reordering后,拥有相同的执行效果(Single Thread)
2.Reordering type
•Examples
– Example1
•经过编译优化,A, B 赋值操作被Reorder;出现在编译期间的Reordering,称之为
Compiler Reordering;
-- Example 2
load 操作被提前; 出现在执行期间的Reordering,称之为
CPU Memory Reordering;
•假设X,Y初始化为0; 根据p1和p2的运行顺序不同,按常规不乱序执行来说,r1, r2 的值可能为0,1(p1 first); 1,0;(p2 first) 1,1(concurrent); 但一定不会出现0,0;的状态,实际上测试运行多次,会出现0,0;的状态,因为cpu在运行指令时将load 操作提前了。测试代码 点这。 (where blank lines have been inserted to highlight the apparent order of operations)
3. CPU Memory Ordering/Reordering
The term memory ordering refers to the order in which the processor issues reads(loads) and writes(stores) through the system bus to system memory. (From Intel System Programming Guide 8.2)
– 为什么需要reordering?
•: L1 Latency 4 clks; L2 10 clks; L3 20 clks; Memory 200 clks -> Huge Latency
•: 考虑指令执行时,read与write的优先级;(CPU设计时,重点考虑)
•CPU Memory Reordering Types
–LoadLoad(读读乱序)、LoadStore(读写乱序)、StoreLoad(写读乱序)、StoreStore(写写乱序)
•CPU如何实现Memory Reordering?
– Load/Store Buffer;LineFill Buffer/Write Combining Buffer;Invalidate Message Queue;...
4. CPU Memory Models
Memory consistency models describe how threads may interact through shared memory consistently.
There are many types of memory reordering, and not all types of reordering occur equally often. It all depends on processor you’re targeting and/or the tool chain you’re using for development.
•主要的CPU Memory Models
–Programming Order -> Stronger Memory Model
–Sequential Consistency
–Strict Consistency
–Data Dependency Order -> Weaker Memory Model
–...
5. Intel X86/64 Memory Model
•In a single-processor system for memory regions defined as write-back cacheable.
– Reads are not reordered with other reads.
– Writes are not reordered with older reads.
– Writes to memory are not reordered with other writes.
–
Reads
may be reordered
with
older writes
to
different locations
but not with older writes to the same location
.
•In a multiple-processor system
– Individual processors use the same ordering principles as in a single-processor system.
–
Writes by a single processor are observed
in the same order by all processors.
– Writes from an individual processor are NOT ordered with respect to the writes from other processors.
– Memory ordering obeys causality (memory ordering respects transitive visibility).
–
Any two stores are seen in a
consistent order by processors other than those performing the stores.
•解读
– 普通内存操作,只可能存在StoreLoad Reordering;
– LoadLoad、LoadStore、StoreStore均不可能Reordering;
– 一个Processor的Writes操作,其他Processor看到的顺序是一致的;
– 不同Processors的Writes操作,是没有顺序保证的;
•StoreLoad Reordering Problem
– Failure of Dekker’s algorithm
– Memory Reordering Caught in the Act
四、Memory Barrier
A memory barrier, is a type of
barrier instruction which causes a
central processing unit (
CPU
) or
compiler to enforce an
ordering constraint on memory operations issued before and after the barrier instruction. This typically means that certain operations are guaranteed to be performed before the barrier, and others after.
1. Compiler Memory Barrier
Compiler Reordering 能够提高程序的运行效率。但有时候 (尤其是针对Parallel Programming),我们并不想让Compiler将我们的程序进行Reordering。此时,就需要有一种机制,能够告诉Compiler,不要进行Reordering,这个机制,就是Compiler Memory Barrier。
顾名思义,Complier Memory Barrier就是阻止Compiler进行Reordering的Barrier Instruction;
•Compiler Memory Barrier Instructions
– GNU
•asm volatile(""::: "memory");
•__asm__ __volatile__ ("" :::"memory");
•使用Compiler Memory Barrier后,即使-O2 编译优化,也不会乱序。
•注意:
– Compiler Memory Barrier只是一个通知的标识,告诉Compiler在看到此指令时,不要对此指令的上下部分做Reordering。
– 在编译后的汇编中,Compiler Memory Barrier消失,CPU不能感知到Compiler Memory Barrier的存在,这点与后面提到的CPU Memory Barrier有所不同;
2. Cpu Memory Barrier
顾名思义,Compiler Memory Barrier既然是用来告诉Compiler在编译阶段不要进行指令乱排,那么CPU Memory Barrier就是用来告诉CPU,在执行阶段不要交互两条操作内存的指令的顺序;
注意:由于CPU在执行时,必须感知到CPU Memory Barrier的存在,因此
CPU Memory Barrier是一条真正的指令,存在于编译后的汇编代码中;
(1)、4种基本的CPU Memory Barriers
– LoadLoad Barrier
– LoadStore Barrier
– StoreLoad Barrier
– StoreStore Barrier
(2)、更为复杂的CPU Memory Barriers
–
Store Barrier (Write Barrier)
•所有在Store Barrier前的Store操作,必须在Store Barrier指令前执行完毕;而所有Store Barrier指令后的Store操作,必须在Store指令执行结束后才能开始;
•Store Barrier只针对Store(Write)操作,对Load无任何影响;
–
Load Barrier (Read Barrier)
•将Store Barrier的功能,全部换为针对Load操作即可;
–Full Barrier
•Load+ Store Barrier,Full Barrier两边的任何操作,均不可交换顺序;
(3)、Memory Barrier Instructions in CPU
•x86, x86-64, amd64
– lfence: Load Barrier
– sfence: Store Barrier
– mfence: Full Barrier
•PowerPC
– sync: Full Barrier
•MIPS
– sync: Full Barrier
•Itanium
– mf: Full Barrier
•ARMv7
– dmb
– dsb
– isb
3.Use CPU Memory Barrier Instructions(x86)
•Only CPU Memory Barrier
– asm volatile(“mfence”);
•CPU + Compiler Memory Barrier
– asm volatile(“mfence” ::: ”memory”);
•Use Memory Barrier in C/C++
4. Use Lock Instruction to Implement a Memory Barrier
Reads or writes
cannot be reordered with I/O instructions,
locked instructions, or serializing instructions.
既然read/write不能穿越locked instructions进行reordering,那么所有带有lock prefix的指令,都构成了一个天然的Full Memory Barrier;
•lock addl
– asm volatile("lock; addl $0,0(%%esp)" ::: "memory")
addl $0,0(%%esp) -> do nothing
lock; -> to be a cpu memory barrier
“memory” -> to be a compiler memory barrier
•xchg
– asm volatile(“xchgl (%0),%0” ::: “memory”)
Question: why xchg don’t need lock prefix?
Answer: The LOCK prefix is automatically assumed for XCHG instruction.
•lock cmpxchg
5.Memory Barriers in Compiler & OS
•Linux(x86,x86-64)
– smp_rmb()
– smp_wmb()
– smp_mb()
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第9张图片](http://img.e-com-net.com/image/info5/ee41e7f3ee364b44894606b1acf1335a.jpg)
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第10张图片](http://img.e-com-net.com/image/info5/21eb215ec36c426393c30b69024652c5.jpg)
•Windows(x86,x86-64)
– MemoryBarrier()
6. X86 Memory Ordering with Memory Barrier
•In a single-processor system for memory regions defined as write-back cacheable.
– 注:新增部分
– Reads or writes cannot be reordered with I/O instructions,
locked instructions, or serializing instructions.
–
Reads cannot pass earlier
LFENCE and
MFENCE instructions.
–
Writes cannot pass earlier LFENCE, SFENCE, and MFENCE instructions.
– LFENCE instructions cannot pass earlier reads.
– SFENCE instructions cannot pass earlier writes.
– MFENCE instructions cannot pass earlier reads or writes.
•In a multiple-processor system
– 注:新增部分
–
Locked instructions have a total order.
五、Read Acquire vs Write Release
1.Read Acquire and Write Release

–Two Special Memory Barriers.

– Definition
•A read-acquire executes before all reads and writes by the same thread that follow it in program order.
•A write-release executes after all reads and writes by the same thread that precede it in program order.
2.Read Acquire and Write Release 的作用
•Read Acquire and Write Release Barriers
– Read Acquire
•LoadLoad + LoadStore Barrier
– Write Release
•LoadStore + StoreStore Barrier
•解读
– Read Acquire + Write Release语义,是所有锁实现的基础(Spinlock, Mutex, RWLock, ...),所有被[Read Acquire, Write Release]包含的区域,即构成了一个临界区,临界区内的指令,确保不会在临界区外运行。因此,Read Acquire又称为
Lock Acquire,Write Release又称为
Unlock Release;
3.How to Implement Read Acquire/Write Release?
•Intel X86, X86-64
– Full Memory Barrier
•mfence
•locked instruction
•Compiler and OS
– Linux
•smp_mb()
– Windows
•Functions with Acquire/Release Semantics
•InterlockedIncrementAcquire ()...
4. Extension:StoreLoad Reorder
•Question
–为什么Intel CPU在LoadLoad,LoadStore,StoreLoad,StoreStore乱序中,仅仅保持了StoreLoad乱序?
–为什么LoadLoad/LoadStore/StoreStore Barrier 乱序被称之为 lightweight Barrier? 而StoreLoad Barrier 则为 Expensive Barrier?
•on PowerPC, the lwsync (short for “lightweight sync”)instruction acts as all three #LoadLoad, #LoadStore and #StoreStore barriers
at the same time, yet is less expensive than the sync instruction,which includes a #StoreLoad barrier.
•Answer
– Store Buffer;
– Store异步不影响指令执行;
– Load只能同步;
•注意
– Intel CPU,Load自带Acquire Semantics;Store自带Release Semantics;
六、Volatile:C/C++ vs Java
•Volatile
– 易失的,不稳定的...
•Volatile in C/C++
The volatile keyword is used on variables that may be modified simultaneously by other threads. This warns the compiler to fetch them fresh each time, rather than caching them in registers. (read/write actually happens)
– No reordering occurs between different volatile reads/writes. (only volatile variables guarantee no reordering)
• Volatile in Java
– (The Same as C/C++),Plus
– Volatile reads and writes establish a happens-before relationship, much like acquiring and releasing a mutex. (no reordering takes place)
• Read Volatile:Acquire Semantics;Write Volatile:Release Semantics;
– Writes and reads of volatile long and double values are always atomic.
• The Java Language Specification Java SE 7 Edition:Chapter 17.7
•Examples
– int answer = 0;
– bool volatile ready;
•Question
– Thread2 的answer 会输出什么结果?
– C/C++
• answer= 42 or 0,均有可能;
– Java
• answer= 42,只有唯一的结果;
–Why?
•Java’s Volatile:Write Release Semantics -> ready(true)一定在answer(42)之后执行;
上述讨论表明:C/C++ Volatile变量,与非Volatile变量之间的操作,是可能被编译器优化交换顺序的。但即使把answer也设置为volatile,虽然能够避免被编译器优化而reorer,但不能确保在不同平台cpu上会不会产生指令执行的乱序,所以一定要小心使用,如下所述。
• C/C++ and "volatile"
When writing single-threaded code, declaring a variable “volatile” can be very useful. The compiler will not omit or reorder accesses to volatile locations. Combine that with the sequential consistency provided by the hardware, and you’re guaranteed that the loads and stores will appear to happen in the expected order.
However, accesses to volatile storage may be reordered with non-volatile accesses, so you have to be careful in multi-threaded uniprocessor environments (explicit compiler reorder barriers may be required). There are no atomicity guarantees, and no memory barrier provisions, so “volatile” doesn’t help you at all in multi-threaded SMP environments. The C and C++ language standards are being updated to address this with built-in atomic operations.
If you think you need to declare something “volatile”, that is a strong indicator that you should be using one of the atomic operations instead.
七、微博问题讨论
测试代码如下:
C++ Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
|
// g++ -o reorder -O3 reorder.c -lpthread
// Run in X86 CPU (Intel/AMD)
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
#define N
100000
sem_t sem_ac, sem_bc, sem_fin;
static
volatile
int A;
static
volatile
int B;
static
volatile
int C;
void *setAC(
void *args)
{
for (;;)
{
sem_wait(&sem_ac);
A =
1;
__sync_synchronize();
C = B;
sem_post(&sem_fin);
}
}
void *setBC(
void *args)
{
for (;;)
{
sem_wait(&sem_bc);
B =
1;
__sync_synchronize();
C = A;
sem_post(&sem_fin);
}
}
int main(
int argc,
char *argv[])
{
pthread_t t1, t2;
int got =
0, iters =
0;
sem_init(&sem_ac,
0,
0);
sem_init(&sem_bc,
0,
0);
sem_init(&sem_fin,
0,
0);
pthread_create(&t1,
NULL, setAC,
NULL);
pthread_create(&t2,
NULL, setBC,
NULL);
for (;; iters++)
{
A = B = C =
0;
sem_post(&sem_ac);
sem_post(&sem_bc);
sem_wait(&sem_fin);
sem_wait(&sem_fin);
if (C ==
0)
{
printf(
"got %d reorders after %d iterations\n", ++got, iters);
}
}
return
0;
}
|
注:__sync_synchronize() 是gcc 提供的一个 full memory barrier.
在多核处理器上不管加不加内存屏障都可能会输出C==0的情况。
如果不加,有两个原因,一个是指令执行乱序如(A=1 与 C=B 交换),另一个是线程调度在多个核上跑的时候。每个核心的寄存器都是独立的,而C=B 是两条汇编指令,出现 c==0 的情况跟下面单核类似,不赘述。
如果加了,就只剩下线程跑在多核上的影响了。
在单核处理器上(或者通过绑定到一个核上运行),即使加了内存屏障还是可以输出c=0的情况,虽然概率小很多。
ASM Code
|
1
2
3
4
5
6
|
|
A =
1
;
80486d4: c7
05 3c a0
04
08
01 movl $0x1,0x804a03c
C = B
;
80486ea: a1
38 a0
04
08
mov 0x804a038,%eax
80486ef: a3
34 a0
04
08
mov %eax,0x804a034
|
ASM Code
|
1
2
3
4
5
6
|
|
B =
1
;
8048694: c7
05
38 a0
04
08
01 movl $0x1,0x804a038
C = A
;
80486aa: a1 3c a0
04
08
mov 0x804a03c,%eax
80486af: a3
34 a0
04
08
mov %eax,0x804a034
|
假设先运行线程1一直到mov 0x804a038,%eax 完,此时线程1的eax为0,然后切换到线程2运行一直到一个循环结束,此时c=1,接着切换回线程1
运行 mov %eax,0x804a034, c又被覆盖成0了。但在这么短的时间内一般不会发生context switching,所以c==0 出现的概率很小。
附录链接:
CPU cache and memory ordering.pptx http://vdisk.weibo.com/s/JFrnp
SMP primer for android http://developer.android.com/training/articles/smp.html
C/C++ Volatile关键词深度剖析 http://hedengcheng.com/?p=725
并发编程系列之一:锁的意义 http://hedengcheng.com/?p=803
多线程程序中操作的原子性 http://www.parallellabs.com/2010/04/15/atomic-operation-in-multithreaded-application/
Gallery of Processor Cache Effects http://igoro.com/archive/gallery-of-processor-cache-effects/
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第2张图片](http://img.e-com-net.com/image/info5/50c76a9f5d2f4fee98049eda7100cc85.jpg)

![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第4张图片](http://img.e-com-net.com/image/info5/fb5002fcea384602b2037ab4b70d8b97.jpg)



![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第5张图片](http://img.e-com-net.com/image/info5/f964f362f6574fb8b41095aa4f3ba0fc.jpg)

![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第6张图片](http://img.e-com-net.com/image/info5/451c31ac2ca54c39aa46d6079d57a7b0.jpg)
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第7张图片](http://img.e-com-net.com/image/info5/ed81744af5774241aeefe0687d2761c1.jpg)

![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第8张图片](http://img.e-com-net.com/image/info5/44d8286737eb41b99e8571eebf424ebe.jpg)
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第11张图片](http://img.e-com-net.com/image/info5/d19a999db5df4a33a7a5e936a7b5fdd3.jpg)
![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第12张图片](http://img.e-com-net.com/image/info5/0fcc334d1938496da4ff1d84453019d3.jpg)

![[置顶] About Cache Coherence, Atomic Operation, Memory Ordering, Memory Barrier, Volatile_第13张图片](http://img.e-com-net.com/image/info5/036ef400424a4309b32f585d6ae33d2d.jpg)