Hadoop-2.4.1学习之InputFormat及源代码分析
向Hadoop集群提交作业时,需要指定作业输入的格式(未指定时默认的输入格式为TextInputFormat)。在Hadoop中使用InputFormat类或InputFormat接口描述MapReduce作业输入的规范或者格式,之所以说InputFormat类或InputFormat接口是因为在旧的API(hadoop-0.x)中InputFormat被定义为接口,而在新的API(hadoop-1.x及hadoop-2.x)中,InputFormat是做为抽象类存在的,在本篇文章中主要讲述InputFormat抽象类及其子类。InputFormat主要用于验证作业的输入是否符合规范,将输入文件分割为逻辑InputSplit,每个InputSplit被分配给一个Mapper任务,提供RecordReader的实现,该实现负责从InputSplit中收集记录交由Mapper任务处理。不同的InputFormat子类提供了不同的InputSplit和RecordReader,比如用于文件的FileSplit和用于数据库的DBInputSplit,用于文本文件的LineRecordReader和Sequence文件的SequenceFileRecordReader等。下图为InputFormat及其子类关系图:
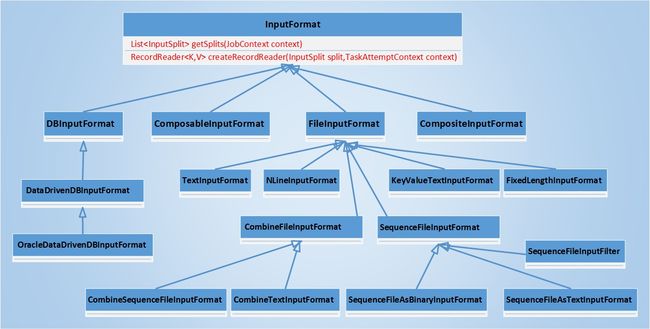
InputFormat抽象类只提供了两个抽象方法,分别用于获取InputSplit和RecordReader。其中的InputSplit只是对输入文件的逻辑分割,而不是物理上将输入文件分割为块,或者说InputSplit只是指定了输入文件的某个范围输入到特定的Mapper中。在实际的应用中,大多数情况都是使用FileInputFormat的子类做为输入,故此在本篇文章中将重点学习FileInputFormat及其子类,对于其它类比如DBInputFormat等将只做简要描述。
- DBInputFormat:从SQL表中读取数据的InputFormat。DBInputFormat使用包含记录号的LongWritable做为键,DBWritable做为值。该类的子类为DataDrivenDBInputFormat,该类与父类使用不同的机制划分InputSplit。
- ComposableInputFormat::抽象类,该类的子类需要提供ComposableRecordReader而不再是RecordReader。相对于RecordReader,ComposableRecordReader提供了额外的方法。
- CompositeInputFormat:在具有相同的排序和分区的一组数据源上执行join操作的InputFormat。
- FileInputFormat:抽象类,是所有基于文件输入的InputFormat的基础类。该类提供了getSplits(JobContext)的通用实现,其子类也可以通过覆盖isSplitable(JobContext, Path)确定输入文件是否可以分割还是整个输入文件都将被特定Mapper任务处理。
FileInputFormat的主要子类有:TextInputFormat、SequenceFileInputFormat、NLineInputFormat、KeyValueTextInputFormat、FixedLengthInputFormat和CombineFileInputFormat,下面简要概述其用途和特点。
- TextInputFormat:用于纯文本文件的InputFormat,也是默认的InputFormat。输入文件被分解为行,回车或者换行做为行结束的标记,键为行在文件中的位置,值为行内容。该InputFormat使用LineRecordReader读取InputSplit的内容。
- NLineInputFormat:将输入中的N行做为一个InputSplit,其中N可以由参数mapreduce.input.lineinputformat.linespermap指定,默认为1。RecordReader也是用LineRecordReader。
- KeyValueTextInputFormat:用于纯文本文件的InputFormat,每行使用分隔字节划分为键和值,该分隔符由参数mapreduce.input.keyvaluelinerecordreader.key.value.separator指定,默认使用\t。如果该分隔符不存在则整行将做为键,值为空。RecordReader为KeyValueLineRecordReader。
- FixedLengthInputFormat:用于读取文件中的记录为固定长度的InputFormat,文件的内容不是必须为文本,也可以是二进制数据。用户必须通过参数fixedlengthinputformat.record.length设置记录的长度,默认值为0,若参数的值小于等于0,将会抛出IOException。RecordReader为FixedLengthRecordReader。
- CombineFileInputFormat:抽象类,该类的getSplits(JobContext)返回的不是List<FileSplit>而是List<CombineFileSplit>。CombineFileSplit根据输入路径中的文件构造,该对象不能够有不同池中的文件,每个CombineFileSplit可能包含不同文件的块。该类有两个子类用于sequence文件和纯文本文件,分别为CombineSequenceFileInputFormat和CombineTextInputFormat,其RecordReader分别为SequenceFileRecordReaderWrapper和 TextRecordReaderWrapper。
- SequenceFileInputFormat:用于sequence文件的InputFormat,获取InputSplit的方法继承自FileInputFormat,并未重写,其RecordReader为SequenceFileRecordReader。该类有三个子类:SequenceFileAsBinaryInputFormat、SequenceFileAsTextInputFormat和 SequenceFileInputFilter,分别用于从sequence文件的二进制格式中读取键值、将sequence文件中的键值转换为字符串形式、从sequence文件中抽样然后交由MapReduce作业处理,抽样由过滤器类确定。三者的RecordReader分别为:SequenceFileAsBinaryRecordReader、SequenceFileAsTextRecordReader和FilterRecordReader。
public List<InputSplit> getSplits(JobContext job) throws IOException {
//以纳秒为单位测试执行的时间
Stopwatch sw = new Stopwatch().start();
//取特定格式的最小分片大小和mapreduce.input.fileinputformat.split.minsize设置的值二者中的较大者,默认为1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//参数mapreduce.input.fileinputformat.split.maxsize的值,默认为Long.MAX_VAULE
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
//获取作业的输入文件
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
//获取file表示的文件所属块的位置
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
//获取文件块大小
long blockSize = file.getBlockSize();
//计算InputSplit大小,通常返回的值为dfs.blocksize的值
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
//若剩余值大于1.1*splitSize,则继续对文件划分,若小于等于该值,则做为一个InputSplit
//也就是说每个InputSplit的最大值为1.1*splitSize,最小文件至少大于0.1*splitSize
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//计算文件分块的索引,此处只计算InputSplit的起始位置是否位于某个块中
//而不管InputSplit的大小是否会超出该块的范围(InputSplit是逻辑概念)
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//起始位置为0,splitSize,2splitSize……,length为splitSize
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
//设置mapreduce.input.fileinputformat.numinputfiles的值为输入文件的数量
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
在上面的代码中,如果splitSize等于blocksize,则InputSplit的起始位置与相应块在文件中offset一致,如果splitSize小于blocksize,即通过参数mapreduce.input.fileinputformat.split.maxsize控制每个InputSplit的大小,那么InputSplit的起始位置就会位于文件块的内部。上述分割InputSplit的逻辑完全是针对大小进行的,那么是否存在将一行记录划分到两个InputSplit中的可能性?答案是肯定的。但上述代码并未对这种情况进行处理,这也意味着在Map阶段存在数据不完整的可能,Hadoop当然不会允许这种情况的发生,而RecordReader就负责处理这种情况,下面以LineRecordReader为例,看看Hadoop是如何处理记录跨InputSplit的。LineRecordReader中的initialize方法在初始化的时候调用一次,此方法将定位InputSplit中第一个换行符的位置,并将实际读取数据的位置定位到第一个换行符之后的位置,如果是第一个InputSplit则不用如此处理。而被过滤的内容则由读取该InputSplit之前的Split的LineRecordReader负责读取,确定第一个换行符位置的代码片段为(此处假设输入为未压缩文件):
//定位到该FileSplit在输入文件中的起始位置
fileIn.seek(start);
in = new SplitLineReader(fileIn, job, this.recordDelimiterBytes);
filePosition = fileIn;
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
//如果不是第一个split(第一个split的start为输入文件的开头,即0),则忽略该split中第一个换行符及之前的数据
//这些数据可能是一整行数据,可能是一行数据的部分内容,也可能仅是换行符本身
if (start != 0) {
//readLine从fileIn读取到换行符(CR,LF以及CRLF)的长度
//然后将start定位到下一行的开始
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
读取InputSplit开头内容的代码位于nextKeyValue中,具体代码为:
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
//此处将读取下一个InputSplit的数据直到换行符,所以initialize需要将下一个InputSplit中第一个换行符之前的内容去掉
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
newSize = in.readLine(value, maxLineLength,
Math.max(maxBytesToConsume(pos), maxLineLength));
pos += newSize;
if (newSize < maxLineLength) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
readLine的功能是读取一行的数据到Text中,因为在分割FileSplit时是基于size的,如果一行被分割到两个split中,比如s1和s2中,在读取s1中的最后一行数据时,会一直读取到s2中的第一个换行符,这是在nextKeyValue方法中实现的,而在处理s2时,则要将已经读取的数据跳过以避免重复读取,这是在initialize中实现的。其它类型的RecordReader是如何实现读取数据的可以阅读其源代码。