在线机器学习算法及其伪代码
机器学习:需要从已知的数据 学习出需要的模型
在线算法:需要及时处理收集的数据,并给出预测或建议结果,并更新模型
通用的在线学习算法步骤如下:
1. 收集和学习现有的数据
2. 依据模型或规则,做出决策,给出结果
3. 根据真实的结果,来训练和学习规则或模型
常用的在线学习算法:
Perceptron: 感知器
PA: passive Perceptron
PA-I
PA-II
Voted Perceptron
confidence-weighted linear linear classification: 基于置信度加权的线性分类器
Weight Majority algorithm
AROW:adaptive regularization of weighted vector 加权向量的自适应正则化
"NHERD":Normal Herd 正态
这里收集了一些算法伪代码,代码然后配上语言描述,就清晰多了。
感知器Perceptron:
线性分类器,是一个利用超平面来进行二分类的分类器,每次利用新的数据实例,预测,比对,更新,来调整超平面的位置。
相对于SVM,感知器不要每类数据与分类面的间隔最大化。

平均感知器Average Perceptron:
线性分类器,其学习的过程,与Perceptron感知器的基本相同,只不过,它将所有的训练过程中的权值都保留下来,然后,求均值。
优点:克服由于学习速率过大,所引起的训练过程中出现的震荡现象。即超平面围着一个中心,忽左忽右之类...
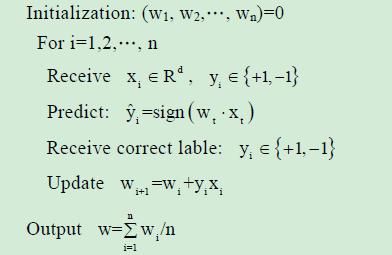
Passive Aggressive Perceptron:
修正权值时,增加了一个参数Tt,预测正确时,不需要调整权值,预测错误时,主动调整权值。并可以加入松弛变量的概念,形成其算法的变种。
优点:能减少错误分类的数目,而且适用于不可分的噪声情况。
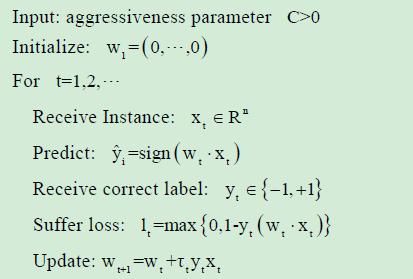
Tt 有三种计算方法:
a. Tt = lt / (||Xt||^2)
b. Tt = min{C, lt / ||Xt||^2}
c. Tt = lt / (||Xt||^2 + 1/(2C))
分别对应PA, PA-I, PA-II 算法,三种类型。
Voted Perceptron:
存储和使用所有的错误的预测向量。
优点:实现对高维数据的分类,克服训练过程中的震荡,训练时间比SVM要好。
缺点:不能保证收敛

Confidence Weight:
线性分类器
每个学习参数都有个信任度(概率),信任度小的参数更应该学习,所以会得到更频繁的修改机会。信任度,用参数向量的高斯分布表示。
权值w符合高斯分布N(u, 离差阵),而 由w*x的结果,可以预测其分类的结果。
并对高斯分布(的参数)进行更新。
这种方法能提供分类的准确性,并加快学习速度。其理论依据在在于算法正确的预测概率不小于高斯分布的一个值。

AROW: adaptive regularition of weighted vector
具有的属性:大间隔训练large margin training,置信度权值confidence weight,处理不可分数据(噪声)non-separable
相对于SOP(second of Perceptron),PA, CW, 在噪声情况下,其效果会更好.
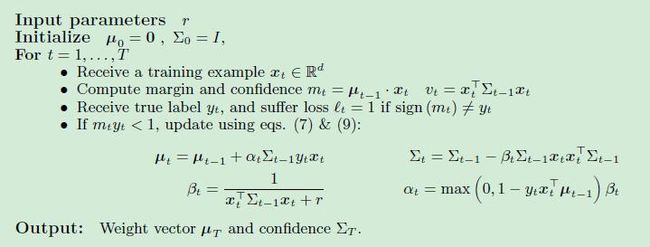
Normal herding:
线性分类器
NHerd算法在计算全协方差阵和对角协方差阵时,比AROW更加的积极。

Weight Majority:
每个维度都可以作为一个分类器,进行预测;然后,依据权值,综合所有结果,给出一个最终的预测。
依据最终的预测和实际测量结果,调整各个维度的权值,即更新模型。
易于实施,错误界比较小,可推导。

Voted Perceptron:
存储和使用所有的错误的预测向量。
优点:实现对高维数据的分类,克服训练过程中的震荡,训练时间比SVM要好。
缺点:不能保证收敛
以上Perceptron, PA, CW, AROW, NHerd都是Jubatus分布式在线机器学习 框架能提供的算法。
Jubatus与Mahout的异同?
两者都是针对分布式处理的机器学习算法库,有较强的伸缩性和运行在普通的硬件上。
但Mahout由于mapreduce的架构,对一些比较复杂的机器学习算法还无法及时支持,且对于实时在线处理数据流也支持比较弱。
Jubatus偏重于在线处理方式,具有较高吞吐量和低延迟的特点,这与Jubatus模型的同步和共享能力相关,并且Jubatus是将数据都是在内存中进行处理分析的。
http://en.wikipedia.org/wiki/Jubatus
http://jubat.us/en/