Neural Networks for Machine Learning by Geoffrey Hinton (1~2)
机器学习能良好解决的问题
- 识别模式
- 识别异常
- 预测
大脑工作模式
人类有![]() 个神经元,每个包含
个神经元,每个包含![]() 个权重,带宽要远好于工作站。
个权重,带宽要远好于工作站。
神经元的不同类型
Linear (线性)神经元

Binary threshold (二值)神经元
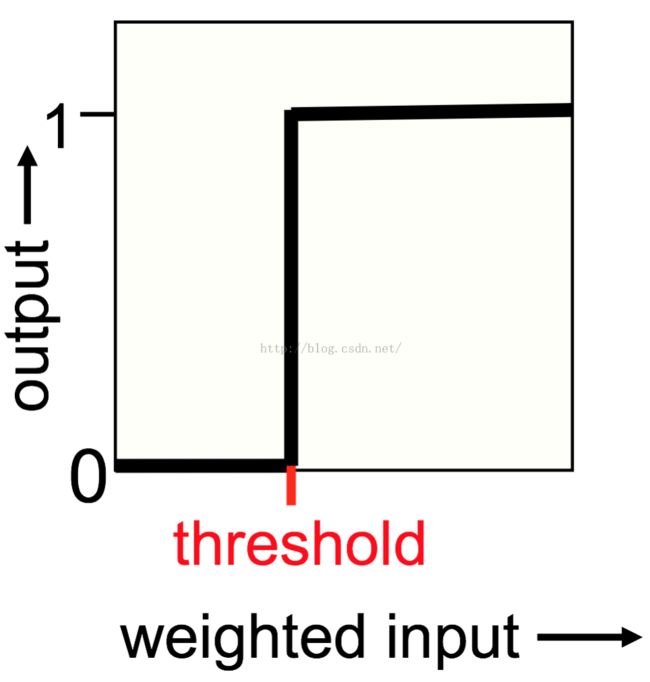
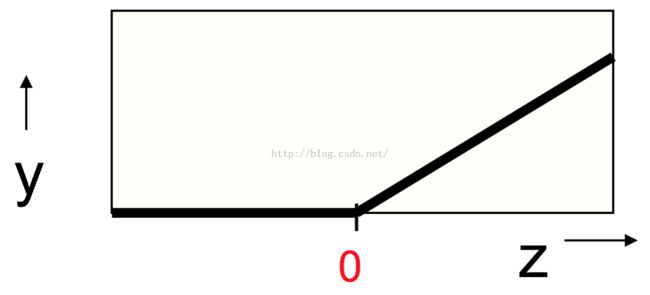
ReLu(Rectified Linear Units) 神经元
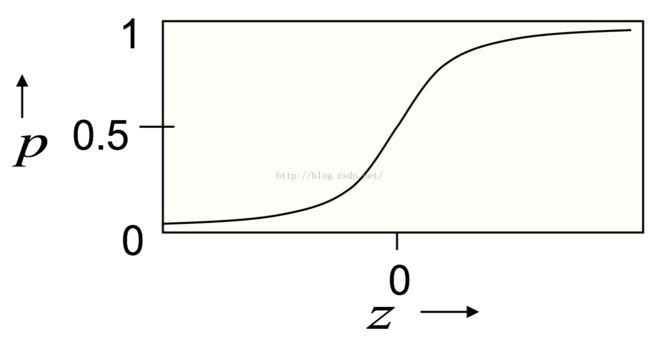
Sigmoid 神经元

Stochastic binary (随机二值)神经元
学习任务的不同类型
Supervised learning(监督学习)
给定输入向量,学习如何预测输出向量。
例如:回归与聚类。
Reinforcement learning(增强学习)
学习如何选择动作去最大化payoff(收益)。
输出是一个动作,或者动作的序列,唯一的监督信号是一个标量反馈。
难度在于反馈在很大程度上是有延时的,而且一个标量包含的信息量很有限。
Unsupervised learning(非监督学习)
发现输入的良好内在表达形式。
提供输入的紧凑、低维度表达。
由已经学到的特征来提供输入的经济性高维度表达。
聚类是极度稀疏的编码形式,只有一维非零特征。
神经网络的不同类型
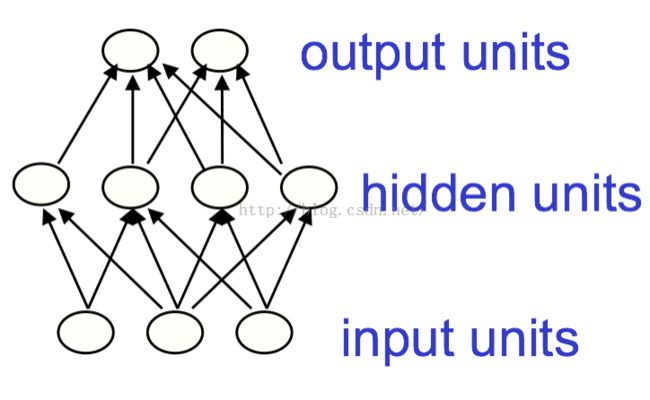
Feed-forward neural networks (前向传播神经网络)
超过一层隐含层即为深度神经网络。
Recurrent networks(循环神经网络)
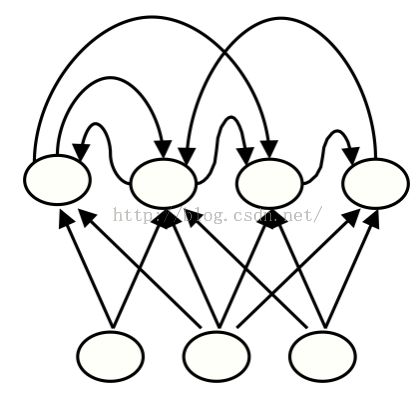
生物学上更可信。
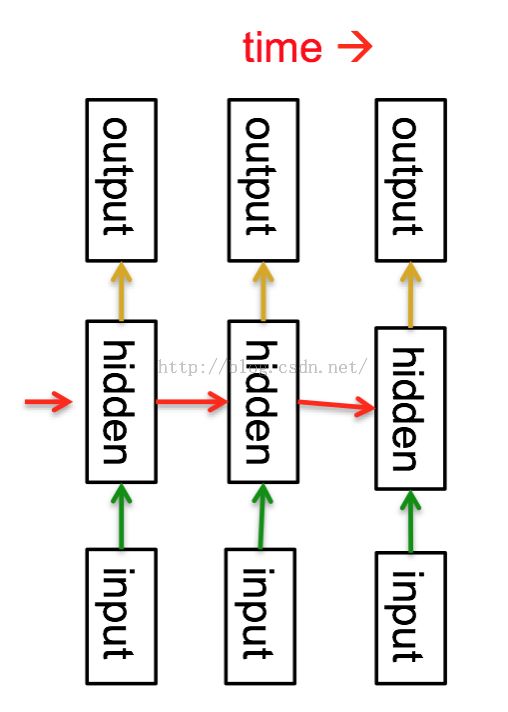
用RNN可以给序列进行建模:
等效于非常深的网络,每层隐含层对应一个时间片。
隐含层有能力记忆长时间信息。
从几何角度看感知机
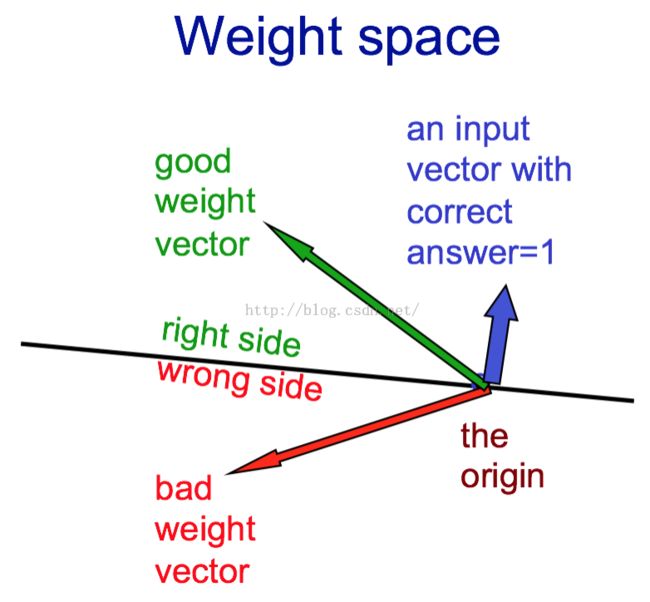
Weight-space (权重空间)
每个权重对应空间一维。
空间每一点对应某个特定权重选择。
忽略偏置项,每个训练样本可以视为一个过原点的超平面。
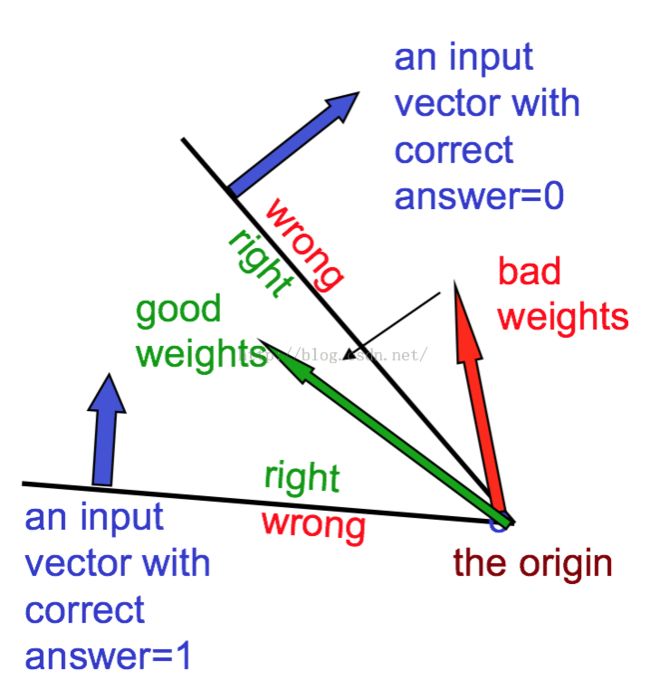
把所有的训练样本都考虑进去,权重的可行解就在一个凸锥里面了。
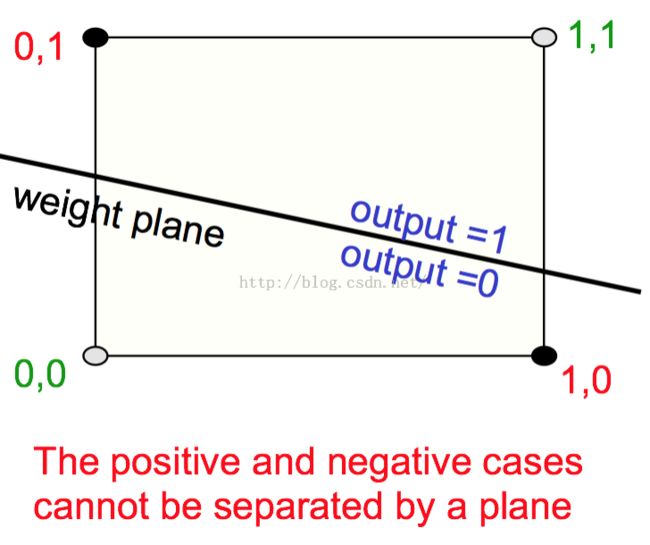
二值神经元做不到的事
同或
循环简单模式识别
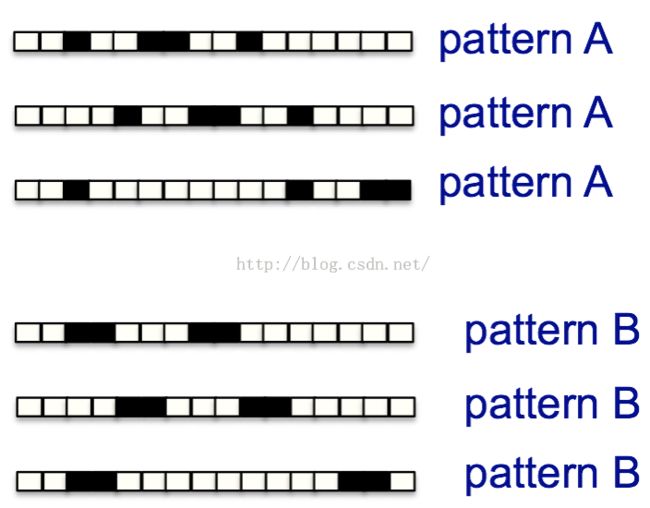
不论对于模式A或是模式B,每次把整个训练集跑完时,神经元得到的输入都是所有权值的4倍。
没有任何区别,也就无法区分两者之间的差异了(非循环模式可以识别)。
使用隐藏神经元
线性神经元再多层也是线性的,不会增加网络学习能力。
固定输出的非线性也不够。
学习隐藏层的权重等效于学习特征。
欢迎参与讨论并关注本博客和微博以及知乎个人主页后续内容继续更新哦~
转载请您尊重作者的劳动,完整保留上述文字以及文章链接,谢谢您的支持!