RNN-RBM for music composition 网络架构及程序解读
RNN(recurrent neural network)是神经网络的一种,主要用于时序数据的分析,预测,分类等。
RNN的general介绍请见下一篇文章《Deep learning From Image to Sequence》。本文针对对deep learning有一点基础(神经网络基本training原理,RBM结构及原理,简单时序模型)的小伙伴讲一下Bengio一个工作(RNNRBM)的原理和实现。
本文重点内容:针对RNN(recurrent neural network)一个应用:music composition进行架构和程序解读,参见paper:Modeling Temporal Dependencies in high-dimensional Sequences。
-----------------------------------------------------------------
Content:
1. RNN 的 general 架构及思想
2. RNN-RBM的定义
2.1 RTRBM结构
2.2 RNN-RBM网络架构
2.3 RNN-RBM的训练
3. RNN-RBM的实现及程序解读
-----------------------------------------------------------------
1. RNN 的 general 架构及思想
RNN是处理时序数据的NN模型,旨在建立时序数据模型,做模拟/预测/分类等。

fig1. Architecture of RNN
如上图A所示为RNN的基本结构,简单的说RNN就是由input units (u), internal units (x), output units (y)组成的neural network. 其中internal units 层内会有连接形成环。Intuitively,这样做的目的是希望让网络下一时刻的状态与当前时刻相关,即,一个有记忆的网络。
展开!如图B,是在t-1, t, t+1时刻network的参数传递(仅展示出forward-propagation中节点间相互decision情况)
2. RNN-RBM的定义:
2.1 RTRBM结构
首先我们以RTRBM(RNNRBM简化版,由Sutskever于08年提出)介入。以下是RTRBM的结构:
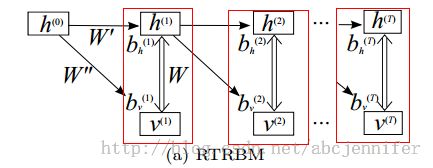
图中每一个红框框住了一个RBM,h是hidden states,v是visible nodes,比如表示为某一时刻的语音等(但实际上为了增加维度有些工作会把v(t)扩展为前后共n帧data的value),双向箭头表示h和v生成的条件概率,即:
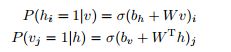 (1)
(1)
其中σ是sigmoid函数。
对于每个时刻的RBM,v和h的联合概率分布为:
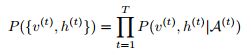 (2)
(2)
其中A(t)=![]() ,即所有t时刻之前的{v,h}集合。
,即所有t时刻之前的{v,h}集合。
此外对于RTRBM,可以理解为每个时刻可以由上一时刻的状态h(t-1)对该时刻产生影响(通过W'和W''),然后通过RBM得到一个(h(t),v(t))稳态。由于每一个参数都和上一时刻的参数有关,我们可以认为只有bias项是受hidden影响的,这样效果是一样的,即:
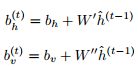 (2)
(2)
2.2 RNN-RBM网络架构
看到了RTRBM这个结构,bengio他们就想了,RTRBM结构里hidden layer描述的是visible的条件概率分布,只能保存暂时的信息(他应该指的是达到稳态后),那我能不能把这些rbm里的hidden layer用RNN代替?于是就冒出了RNN-RBM:
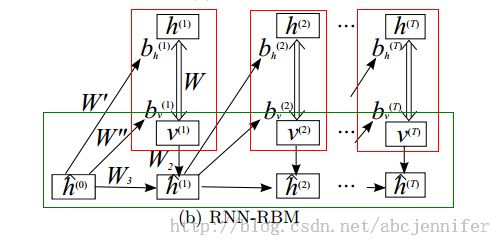
其中每个红框依然框住一个RBM,而下面绿框就表示了一个按时间展开了的RNN。这样设计的好处是把hiddenlayer分离了,一部分(h)只用于表示当前RBM的稳态state,另一部分(h^)表示RNN里的hidden节点。
PS: 关于RNN的网络结构:v(visible),u(internal units),h(hidden)
边:v-u, u-v, v-h(双向边,==h-v), u-h, u-u(实际上是环,只不过时序模型中unfold成u^t-u^{t+1})这些边在不同level(sequence的不同时刻)是共享权值滴。
所以我们实际上要优化的参数就是上面的5个weight matrix加bv,bh,bu
2.3 RNN-RBM 的训练
1. 由![]() 计算h^
计算h^
2. 由(2)计算bh, bv,并根据k-step block gibbs采样得到v(t)
3. 通过NLL的cost![]() 对RBM里的参数(W, bh, bv)进行求导并更新
对RBM里的参数(W, bh, bv)进行求导并更新
4. 估计RNN参数(W2, W3, bh^)并进行更新
3. RNN-RBM的实现及程序解读
3.1 准备工作及环境配置
3.1.1 参考程序见 : http://deeplearning.net/tutorial/rnnrbm.html
3.1.2 下载midi包(http://www.iro.umontreal.ca/~lisa/deep/midi.zip),extract到python包目录下(我的是/usr/lib/python2.7/dist-packages)
3.1.3 下载数据集(Nottingham Database of folk tunes),放在代码同文件夹下的data/
3.2 程序关键点解读:
1. build_rbm: 构建单个RBM, 进行k次vhv采样
输入:5个参数v(visible), W(RBM weight), bv(v_bias), bh(h_bias), k(param k in CD-k)输出:
v_sample(CD-k对visible的采样结果),
cost(RBM中的cost<NLL>,即FE(input)-FE(v_sample), FE表示Free Energy. 后面要用cost对参数求导),
monitor(cost monitor,CD-k中用重构cross-entropy代替上面cost用来观测)
updates(Gibbs采样的update dictionary)
2. build_rnnrbm: 构建RNN-RBM
输入:n_visible, n_hidden(conditional RBM 的隐节点数), n_hidden_recurrent(RNN的隐节点数)
default:n_visible = 88(钢琴音阶),n_hidden = 150, n_hidden_recurrent = 100
输出:
v: 训练的时序数据
v_t: visible 的采样时序数据
params: W,bv(b_vias),bh,Wuh,Wuv,Wvu,Wuu,bu (8个待train参数)
v_sample, cost, monitor, updates_rbm = build_rbm(v, W, bv_t[:], bh_t[:], k=15)
updates_train: 训练模式下的param更新dictionary
updates_generate: 生成模式下param更新dictionary
嵌套函数:
recurrence(v_t, u_tm1):
训练模式下,直接根据当前v_t和u_tm1生成u_t
生成模式下,v_t输入为None,recurrence从全零开始gibbs采样k次生成v_t,并计算相应u_t
注: line 156: (u_t, bv_t, bh_t), updates_train = theano.scan(lambda v_t, u_tm1, *_: recurrence(v_t, u_tm1),sequences=v, outputs_info=[u0, None, None], non_sequences=params)对sequence=v的每一个时刻跑recurrence得到相应bv_t,bh_t;然后用它们估计下一时刻的v(gibbs sampling):v_sample, cost, monitor, updates_rbm = build_rbm(v, W, bv_t[:], bh_t[:], k=15)
3. RnnRbm.train:
输入:files: 文件名,batch_size, num_epochs
功能:训练模式。将train目录下的每个mid文件分成batch进行SGD更新参数,并计算cost.
输出:train目录下所有mid文件的cost均值
4. RnnRbm.generate:
功能:生成模式。用build_rnnrbm的recurrence生成长为updates_generate的n_step(line 166:默认为200)的sequence.
(v_t, u_t), updates_generate = theano.scan(lambda u_tm1, *_: recurrence(None, u_tm1),outputs_info=[None, u0], non_sequences=params, n_steps=200)
5. 几个n_steps:
1. line 60: chain, updates = theano.scan(lambda v: gibbs_step(v)[1], outputs_info=[v], n_steps=k)的k表示Gibbs的CD-k采样采k次而不等到converge
2.line 148: recurrence中 v_t, _, _, updates = build_rbm(T.zeros((n_visible,)), W, bv_t, bh_t, k=25);k=25 表示recurrence进行Gibbs采样25次(意义同1)
3. line 164: (v_t, u_t), updates_generate = theano.scan(lambda u_tm1, *_: recurrence(None, u_tm1), outputs_info=[None, u0], non_sequences=params, n_steps=200) 生成模式下n_step=200即生成的sequence(v_t)长200, 哪为什么最后可视化出来横坐标只有60呢?看RnnRbm中dt的作用。最后我们画的是extent = (0, self.dt * len(piano_roll)) + self.r。这里默认dt = 0.3,len(piano_roll)=200. 懂了?
4. line 156: (u_t, bv_t, bh_t), updates_train = theano.scan(lambda v_t, u_tm1, *_: recurrence(v_t, u_tm1), sequences=v, outputs_info=[u0, None, None], non_sequences=params)这里没有显示n_step,但是scan的重复次数0实际上是由sequence长度定的。