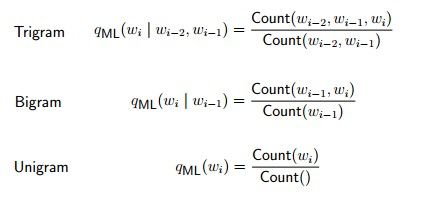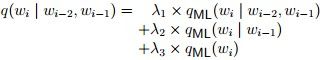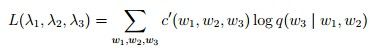NLP 学习笔记 01
coursera上MichaelCollins的课程nlp开始了,在读大部头(mlapp)学习ML的过程中看看nlp也着实不错,可以做一些实践
这个课程老师语速很慢,讲解思路十分清晰,推荐给大家。在学习中我可能会把两周的内容在我的blog做一个总结(也许是一周的,看内容的多少了,这第一周的内容太详实了,总结起来太费劲了![]() ),方便以后学习和查看
),方便以后学习和查看
----------------------------------------------------------------------------------------------------------------
1.Introductionto Natural Language Processing
这一节主要介绍了nlp的一些基本内容,nlp的一般定义计算机使用自然语言作为输入和输出,比如siri可以听懂你说的话。这是让电脑与人类交流最重要的一个中间步骤,其应用大致可以分为Machine Translation(机器翻译,典型应用:谷歌翻译),Information Extraction(信息提取),TextSummarization(文本归纳),DialogueSystems(对话系统:典型应用:siri)。
最基本的nlp问题叫做Tagging,也就是对于一段话的每个词进行特定的标记,举个例子:
“Profitts/N soared/V at/P Boeing/N Co./N ,/,easily/ADV topping/V forecasts/N on/P Wall/N Street/N ./.”
其中红色的标记部分就叫做tag,上例的N表示名词,P表示介词,V表示动词,ADV表示副词,当然tagging的目标具体不仅仅限于词语的词性,可以灵活地设定。比如:
"Pro ts/NA soared/NA at/NA Boeing/SC Co./CC"
其中SC表示Start of Company,CC表示 Company的结束,/NA表示无意义,这样就可以识别出具体的公司的名字了。
nlp是一个很难的问题,因为同一个词汇可能会有不同的词性和意思,甚至同一句话的不同断句都表示不同的意思,这是nlp问题的难点,除此之外,语音识别也面临着同音字的问题,总的来说nlp的主要难点就是Ambiguity。
2.The Language Modeling Problem
我们有有限个数的词汇
![]()
无限个数的句子,由词汇自由组成,而语言模型就是判断一个句子是否符合要求,对于人来说可以很自然地判断一个句子是否正确,但对于电脑来说就没那么简单了,所以我们会使用一个概率分布来体现这个句子的正确性:
如下式,其中![]() 是所有句子组成的集合。
是所有句子组成的集合。
 (2式)
(2式)
一些例子:

这样通过概率的大小可以较为科学地区分句子的正确性,这种技术典型的应用就是语音识别以及中文中的分词。
语言模型中使用最为广泛的模型叫做Markov模型,它对于语言的分析做了一个很强的假设,也就是说“一个词汇出现的概率只与前面的一个或者数个词相关”,很明显这个假设是错的,但在目前的应用中非常有效。用公式解释这个假设也就是:
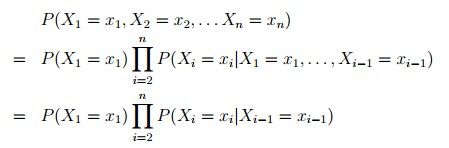
其中最后一个等式使用了假设
![]()
上式因为一个词汇的概率只与前一个词有关,所有又被称为First-OrderMarkov Processess除此之外还有Second-Order MarkovProcesses:与前两个词有关:
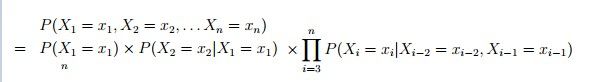
一般为了表示的方便,我们设定x(0)=*,x(-1)=* 。' * '表示一种特殊的开始符号,所以Second-Order又可以表示为:
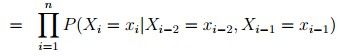
3.Trigram Language Models
一个三元语言模型就是由:
1.一个词的集合V;
2.一个参数q(w|u,v)其中w,u,v满足 ![]()
组成的,并且对于任意一个句子X1……Xn,其中Xn等于STOP,其它词属于V.并且对于这个句子有:
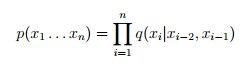 其中设定
其中设定 ![]()
举一个例子:
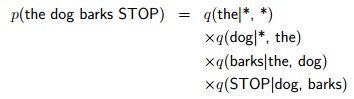
这样我们就定义了这个模型,并且是满足(2式)的要求,那么现在需要的就是计算参数q了。
一个很自然的解就是根据条件概率的定义,通过统计词组出现的次数来计算,也就是:
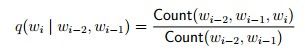
然而这样的确可以,但是会遇到Sparse Data Problems,也就是说分母可能为0,这是极有可能出现的事情,而且当|V|越来越大时,参数q的个数也就越来越多,因为我们知道参数的个数等于|V|^3,这里留待以后解决。
4.Evaluating a Language Model: Perplexity 衡量一个语言模型的标准:复杂度?



5.Linear Interpolation 线性插值?