Mahout随机森林算法源码分析(2-4)
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
接上篇,先来说说上篇最后的bestIg和bestIndex的求法。在说这个前,要首先明确一个数组的熵的求法,按照mahout中的源码针对这样的一个数组a=[1,3,7,3,0,2]其熵为:
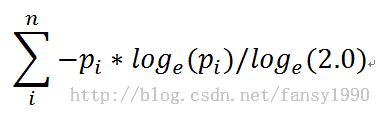
设sum=1+3+7+3+0+2,则其中pi对应于1/sum、3/sum、7/sum、3/sum、2/sum(其中若数组中的元素为0,则不参与计算),这个是数组熵的计算。
假如我有这样的一个数组counts:
[1,3,5,3,0] [0,9,2,4,2] [7,2,1,3,4] [4,3,6,8,3] [3,2,1,4,5]那么首先我把对应的数字相加得到countAll=[15,19,15,22,14],然后求得countAll的熵hy,作为一个常数。然后把counts数组分为两部分前面i行和后面的5-i行分别为一组,然后求得这两组的熵分别是ig(i)、ig'(i),这两组对应的size(i)=所有元素相加值,size'(i)也等于所有元素相加值。比如size(1)=12。Size=counts所有元素相加,是一个常数。然后得到这样的一个常数Ig(i)=hy-size(i)*ig(i)/Size-size'(i)*ig'(i)/Size。i从0到4,这样就得到了5个Ig。最后bestIg=max(Ig(i)),bestIndex=bestIg对应的i值。
然后到返回值了return new Split(attr, bestIg, values[best]);这个Split有三个值,attr对应是属性的标识,bestIg是属性的衡量值,用于和其他属性做对比,values[best]是属性attr的分水岭,用于attr属性内部的比较。
代码继续往下看:
Split best = null;
for (int attr : attributes) {
Split split = igSplit.computeSplit(data, attr);
if (best == null || best.getIg() < split.getIg()) {
best = split;
}
}上面随机选择了三个属性,然后这里则取出其Ig值比较高的那个属性的Split。
代码继续:
Node childNode;
if (data.getDataset().isNumerical(best.getAttr())) {
boolean[] temp = null;
Data loSubset = data.subset(Condition.lesser(best.getAttr(), best.getSplit()));
Data hiSubset = data.subset(Condition.greaterOrEquals(best.getAttr(), best.getSplit()));
if (loSubset.isEmpty() || hiSubset.isEmpty()) {
// the selected attribute did not change the data, avoid using it in the child notes
selected[best.getAttr()] = true;
} else {
// the data changed, so we can unselect all previousely selected NUMERICAL attributes
temp = selected;
selected = cloneCategoricalAttributes(data.getDataset(), selected);
}
// size of the subset is less than the minSpitNum
if (loSubset.size() < minSplitNum || hiSubset.size() < minSplitNum) {
// branch is not split
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("branch is not split Leaf({})", label);
return new Leaf(label);
}
Node loChild = build(rng, loSubset);
Node hiChild = build(rng, hiSubset);
// restore the selection state of the attributes
if (temp != null) {
selected = temp;
} else {
selected[best.getAttr()] = alreadySelected;
}
childNode = new NumericalNode(best.getAttr(), best.getSplit(), loChild, hiChild);
}
比如这次debug随机选择的三个属性是[4,2,0],然后计算得到属性2的Ig最大,所以首先选择属性2,属性2是Numerical的,所以直接进入到if下面的代码块
刚开始 Data loSubset = data.subset(Condition.lesser(best.getAttr(), best.getSplit())); Data hiSubset = data.subset(Condition.greaterOrEquals(best.getAttr(), best.getSplit()));这两句就是把所有数据按照属性bestAttr中的bestSplit来进行分组。若属性bestAttr中的值小于bestSplit的值,那么这条数据就被分给loSubset中,否则分给hiSubset中。debug模式查看这两个变量的值:
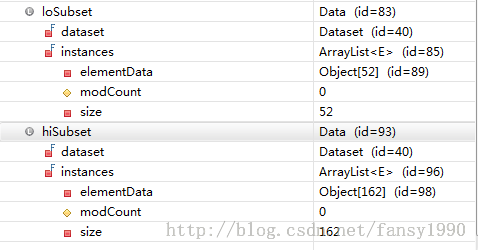
可以看到52+162=214,这说明这两个数组的确是由214条记录分离得到的。且分别观察loSubset、hiSubset,可以看到里面属性attr的值都是分别<bestSplit和>=bestSplit的。
下面到了Node loChild = build(rng, loSubset);然后又到了build函数,这次data是含有52条记录的数据了。然后又随机取出三个属性,计算得到最优的属性,然后再按照最优的属性把数据分为两部分,然后再build()。啥时候退出循环呢?
if (loSubset.size() < minSplitNum || hiSubset.size() < minSplitNum) {
// branch is not split
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("branch is not split Leaf({})", label);
return new Leaf(label);
}这里可以看到当分组后的两部分数据中的其中一部分数据小于给定的阈值minSplitNum(终于知道这个值是用来干啥的了)的时候,就退出循环。返回的new Leaf(label)中的label是哪个label呢?是data中label最多的那个,可以参见下面的代码:
public int majorityLabel(Random rng) {
// count the frequency of each label value
int[] counts = new int[dataset.nblabels()];
for (int index = 0; index < size(); index++) {
counts[(int) dataset.getLabel(get(index))]++;
}
// find the label values that appears the most
return DataUtils.maxindex(rng, counts);
}最后返回的childNode是什么? childNode = new NumericalNode(best.getAttr(), best.getSplit(), loChild, hiChild);可以看到这个childNode包含四个属性,第一个是属性attr,第二个是该属性的分水岭bestSplit,第三个是左子树,第四个是右子树。
通过上面不断的递归循环,最后得到一棵树,调用返回到Step1MapperFollow的 Node tree=bagging.build(rng)上面来。比如某次debug的树如下:
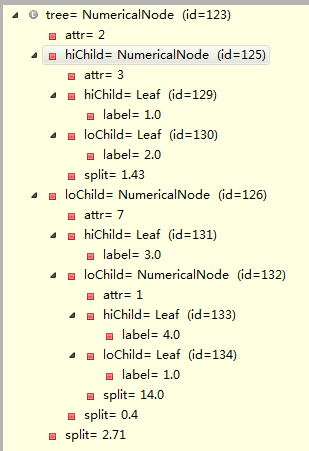
对应的树画出来如下所示:
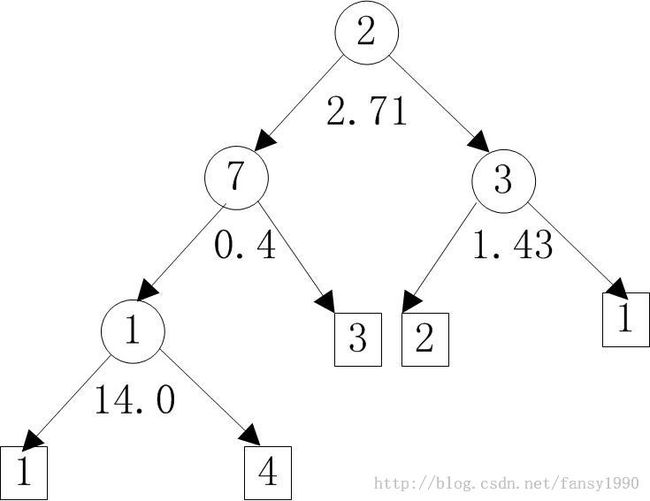
左边是属性值小于中间的那个数字的,右边是大于或等于的。
然后就是设置下输出的格式key.set(partition, firstTreeId + treeId);
// if (!isNoOutput()) {
MapredOutput emOut = new MapredOutput(tree);
然后直接输出了,比如Step1MapperFollow的输出如下:
key:0***value:{NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,LEAF:;;;;;;,LEAF:;; | null}
key:1***value:{NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,LEAF:;;;,LEAF:;;;,LEAF:;;; | null}
key:2***value:{NUMERICAL:NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,LEAF:;;,NUMERICAL:LEAF:;,LEAF:;;; | null}
这样表示输出3棵树,其中最后一棵树就是上图的那棵树的打印字符串。这样Step1Mapper的仿制代码就分析完了,其实就是Step1Mapper的工作流分析完了。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990