老段带你学sed&awk第一讲
2.grep的基本用法
grep 也支持正则表达式,因为grep比较简单,所以我们就用grep来让大家理解什么是正则表达式。
grep的作用是用来过滤含有特定字符的行。
用法:grep 关键字 file

3.正则表达式元字符
^表示行开头
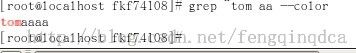
$表示行尾

查找的是以tom为行尾的这些行。
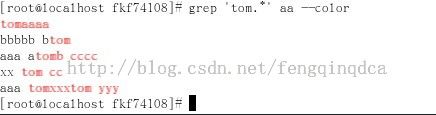
在正则表达式中,.表示单个字符,它可以匹配除了换行符之外的所有字符。

.也是能够匹配空格的。上图的意思是说在aa中找到tom后面含有三个字符的那些行。
*表示它前面的那个字符可以出现任意次。
+表示它前面的那个字符至少要出现一次。

上图的意思是在aa中查找tom后面要有一个字符,且这个字符必须要出现一次。

上图的btom这行就没有匹配出来,因为btom后面没有任何字符了,而我们要查找的是tom后面至少要有一个字符。
我们在这个命令里使用了-E选项,意思就是使用扩展的grep,因为grep所能使用的元字符有限。
刚才讲的两个元字符*和+这两个元字符都是贪婪型的。
所谓的贪婪型就是进行最长的匹配。
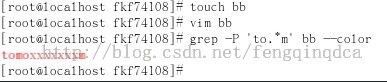
从上图我们看到了它匹配的是最长匹配。这种匹配方法叫做贪婪匹配,但有时候我们并不需要这样的结果,我们只想要最短匹配(懒惰匹配)

只要在*后面加上?就可以了。
?表示它前面的字符可以有也可以没用
![]()
从上图可以看出来?好前面的a可以出现也可以没用,都能匹配出来。
注意grep 不支持+ ?这个元字符,如果要使用的话,只能使用扩展grep(egrep 或者grep -E)
[]:匹配一个字符,出现在[]里面的字符都是或的关系:

上图的意思是在aa中查找那些Tom或者tom开头的行。
^如果是出现在中括号外面 表示开头的意思,如果是出现在[]里面的话,表示否定的意思。

这里匹配的是,开头不能是T或者t的行,而且后面还要有2个字符。
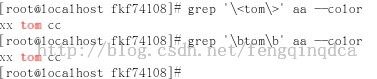
^$他们匹配的是行的开头和行的结尾,如果我们想匹配单词的开头,用\<
grep '\<tom' aa --color
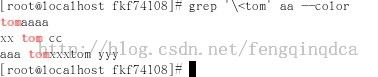
\>表示单词的结尾:grep 'tom\>' aa --color

上图所显示的内容是以tom单词结束的,并不是行的结束。
很多时候,我就想找tom的单词,而不是tomaaa这样的单词。
\<\>是精确匹配符号,如\<the\>表达式精确匹配the这个单词,而不匹配包含the的单词,如them there等。
在正则表达式中,我们还可以做标签。如果我们在匹配模式中给某一部分做了一个标签的话,我们在后面就可以直接引用它。如果我们想对某一部分作标签的话,只要使用\(\)括起来就可以了,如果我们想引用的话就使用\n(n代表数字)。比如说第一个被引用\(\)的部分我们就用\1来再次引用:

这里第一个\(\)引用的内容是tom,所以我用\1来调用tom。这句话的意思是,我们过滤含有tom,tom后面有三个字符,然后再有一个tom这样的行。上图中的\1就表示tom。
如果希望tom后面有三个字符,我们可以这样
grep 'tom.\{3\}' aa --color
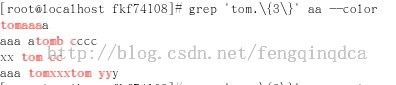
这句话的意思是要查找tom后面跟一个字符,而且这个字符要出现三次。
![]()
我们刚才使用的方法是:\{n\},表示的意思是前面的字符要出现n次。
\{n,\}它前面的字符至少要出现n次。
\{n,m\}它前面的字符出现的次数在n~m之间。
我们可以使用[0-9]来表示数字,除了这种方法我们还可以使用\d来表示数字
grep -P '\d' aa --color