CUDA程序优化小记(六)
CUDA程序优化小记(六)
CUDA全称Computer Unified Device Architecture(计算机同一设备架构),它的引入为计算机计算速度质的提升提供了可能,从此微型计算机也能有与大型机相当计算的能力。可是不恰当地使用CUDA技术,不仅不会让应用程序获得提升,反而会比普通CPU的计算还要慢。最近我通过学习《GPGPU编程技术》这本书,深刻地体会到了这一点,并且用CUDARuntime应用改写书上的例子程序;来体会CUDA技术给我们计算能力带来的提升。
原创文章,反对未声明的引用。原博客地址:http://blog.csdn.net/gamesdev/article/details/18800393
上次的程序是使用了CUDA的共享存储器进行累加的运算,不过这里面有一个比较明显的资源浪费现象:最后求和的时候通过__syncthreads()函数对一个块(BLOCK)中的所有线程进行同步,但是仅仅使用了一个线程进行求和累加的运算,其余的线程无事可做。为了防止这样的现象发生,我们需要借助并行缩减算法中比较常见的缩减树算法。
缩减树的算法如下图所示。
| 线程1 |
线程2 |
线程3 |
线程4 |
线程5 |
线程6 |
线程7 |
线程8 |
| ↓ |
↙ |
↓ |
↙ |
↓ |
↙ |
↓ |
↙ |
| ↓ |
|
↙ |
|
↓ |
|
↙ |
|
| ↓ |
|
|
|
↙ |
|
|
|
| ■ |
|
|
|
|
|
|
|
在这幅图中8个线程的数据经过层层缩减,分别送到每2n+1个线程中。这样可以尽量让更多的线程承担计算任务。基于这样的思想改写的内核函数如下:
////////////////////////在设备上运行的内核函数/////////////////////////////
__global__ static voidKernel_SquareSum( int* pIn, size_t* pDataSize,
int*pOut, clock_t* pTime )
{
// 声明一个动态分配的共享存储器
extern __shared__ int sharedData[];
const size_t computeSize =*pDataSize / THREAD_NUM;
const size_t tID = size_t(threadIdx.x );// 线程
const size_t bID = size_t(blockIdx.x );// 块
int offset = 1; // 记录每轮增倍的步距
int mask = 1; // 选择合适的线程
// 开始计时
if ( tID == 0 ) pTime[bID] =clock( );// 选择任意一个线程进行计时
// 执行计算
for ( size_t i = bID * THREAD_NUM+ tID;
i < DATA_SIZE;
i += BLOCK_NUM * THREAD_NUM )
{
sharedData[tID] += pIn[i] * pIn[i];
}
// 同步一个块中的其它线程
__syncthreads( );
while ( offset < THREAD_NUM )
{
if ( ( tID & mask ) == 0 )
{
sharedData[tID] += sharedData[tID + offset];
}
offset += offset; // 左移一位
mask = offset + mask; // 掩码多一位二进制位
__syncthreads( );
}
if ( tID == 0 )// 如果线程ID为,那么计算结果,并记录时钟
{
pOut[bID] = sharedData[0];
pTime[bID + BLOCK_NUM] = clock( );
}
}
程序中,设定一个名为mask的变量来选择合适的线程,offset用来计算mask的偏移,两者结合来保证正确的线程被选中用来计算。下面表格可以用来说明其关系。
| 第几轮缩减 |
mask |
offset |
选中的线程 |
|||
| 二进制 |
十进制 |
二进制 |
十进制 |
二进制 |
十进制 |
|
| 1 |
00000001 |
1 |
00000001 |
1 |
XXXXXXX0 |
2的倍数 |
| 2 |
00000011 |
3 |
00000010 |
2 |
XXXXXX00 |
4的倍数 |
| 3 |
00000111 |
7 |
00000100 |
4 |
XXXXX000 |
8的倍数 |
| 4 |
00001111 |
15 |
00001000 |
8 |
XXXX0000 |
16的倍数 |
最后注意一下,while循环中每轮缩减都要保证前一轮参加缩减的线程都已经执行完毕并且写入了正确的存储器,因此还需要使用__syncthreads()函数同步所有的线程。
下面是程序运行截图:
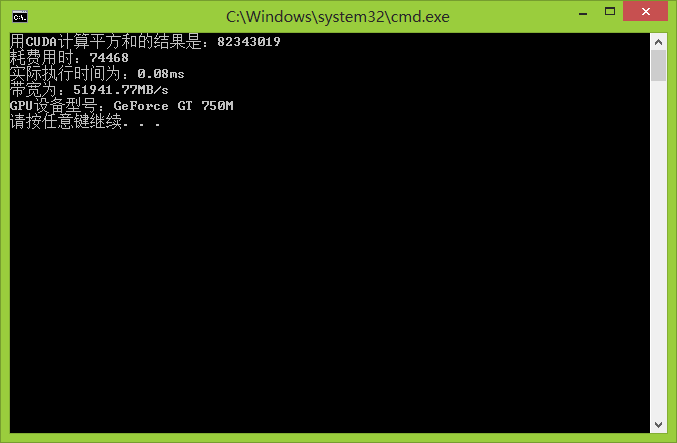
下面是各个平台的执行效率对比:
| 显卡 |
执行时间 |
带宽 |
| GeForce 9500 GT |
0.54ms |
7376.63MB/s |
| GeForce GT750M |
0.08ms |
51941.77MB/s |
下面是程序的所有代码:
#include <cuda_runtime.h>
#include <cctype>
#include <cassert>
#include <cstdio>
#include <ctime>
#define DATA_SIZE 1048576
#define BLOCK_NUM 32
#define THREAD_NUM 256
#ifndef nullptr
#define nullptr 0
#endif
using namespace std;
////////////////////////在设备上运行的内核函数/////////////////////////////
__global__ static voidKernel_SquareSum( int* pIn, size_t* pDataSize,
int*pOut, clock_t* pTime )
{
// 声明一个动态分配的共享存储器
extern __shared__ int sharedData[];
const size_t computeSize =*pDataSize / THREAD_NUM;
const size_t tID = size_t(threadIdx.x );// 线程
const size_t bID = size_t(blockIdx.x );// 块
int offset = 1; // 记录每轮增倍的步距
int mask = 1; // 选择合适的线程
// 开始计时
if ( tID == 0 ) pTime[bID] =clock( );// 选择任意一个线程进行计时
// 执行计算
for ( size_t i = bID * THREAD_NUM+ tID;
i < DATA_SIZE;
i += BLOCK_NUM * THREAD_NUM )
{
sharedData[tID] += pIn[i] * pIn[i];
}
// 同步一个块中的其它线程
__syncthreads( );
while ( offset < THREAD_NUM )
{
if ( ( tID & mask ) == 0 )
{
sharedData[tID] += sharedData[tID + offset];
}
offset += offset; // 左移一位
mask = offset + mask; // 掩码多一位二进制位
__syncthreads( );
}
if ( tID == 0 )// 如果线程ID为,那么计算结果,并记录时钟
{
pOut[bID] = sharedData[0];
pTime[bID + BLOCK_NUM] = clock( );
}
}
bool CUDA_SquareSum( int* pOut,clock_t* pTime,
int* pIn, size_tdataSize )
{
assert( pIn != nullptr );
assert( pOut != nullptr );
int* pDevIn = nullptr;
int* pDevOut = nullptr;
size_t* pDevDataSize = nullptr;
clock_t* pDevTime = nullptr;
// 1、设置设备
cudaError_t cudaStatus = cudaSetDevice( 0 );// 只要机器安装了英伟达显卡,那么会调用成功
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "调用cudaSetDevice()函数失败!" );
return false;
}
switch ( true)
{
default:
// 2、分配显存空间
cudaStatus = cudaMalloc( (void**)&pDevIn,dataSize * sizeof( int) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中数组时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevOut,BLOCK_NUM * sizeof( int) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中返回值时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevDataSize,sizeof( size_t ) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中数据大小时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevTime,BLOCK_NUM * 2 * sizeof( clock_t ) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中耗费用时变量失败!" );
break;
}
// 3、将宿主程序数据复制到显存中
cudaStatus = cudaMemcpy( pDevIn, pIn, dataSize * sizeof( int ),cudaMemcpyHostToDevice );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMemcpy()函数初始化宿主程序数据数组到显卡时失败!" );
break;
}
cudaStatus = cudaMemcpy( pDevDataSize, &dataSize, sizeof( size_t ), cudaMemcpyHostToDevice );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMemcpy()函数初始化宿主程序数据大小到显卡时失败!" );
break;
}
// 4、执行程序,宿主程序等待显卡执行完毕
Kernel_SquareSum<<<BLOCK_NUM, THREAD_NUM, THREAD_NUM *sizeof( int)>>>
( pDevIn, pDevDataSize, pDevOut, pDevTime );
// 5、查询内核初始化的时候是否出错
cudaStatus = cudaGetLastError( );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "显卡执行程序时失败!" );
break;
}
// 6、与内核同步等待执行完毕
cudaStatus = cudaDeviceSynchronize( );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在与内核同步的过程中发生问题!" );
break;
}
// 7、获取数据
cudaStatus = cudaMemcpy( pOut, pDevOut, BLOCK_NUM * sizeof( int ),cudaMemcpyDeviceToHost );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在将结果数据从显卡复制到宿主程序中失败!" );
break;
}
cudaStatus = cudaMemcpy( pTime, pDevTime, BLOCK_NUM * 2 * sizeof( clock_t ), cudaMemcpyDeviceToHost );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在将耗费用时数据从显卡复制到宿主程序中失败!" );
break;
}
cudaFree( pDevIn );
cudaFree( pDevOut );
cudaFree( pDevDataSize );
cudaFree( pDevTime );
return true;
}
cudaFree( pDevIn );
cudaFree( pDevOut );
cudaFree( pDevDataSize );
cudaFree( pDevTime );
return false;
}
void GenerateData( int* pData,size_t dataSize )// 产生数据
{
assert( pData != nullptr );
for ( size_t i = 0; i <dataSize; i++ )
{
srand( i + 3 );
pData[i] = rand( ) % 100;
}
}
int main( int argc, char** argv )// 函数的主入口
{
int* pData = nullptr;
int* pResult = nullptr;
clock_t* pTime = nullptr;
// 使用CUDA内存分配器分配host端
cudaError_t cudaStatus = cudaMallocHost( &pData, DATA_SIZE * sizeof( int ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
cudaStatus = cudaMallocHost( &pResult, BLOCK_NUM * sizeof( int ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
cudaStatus = cudaMallocHost( &pTime, BLOCK_NUM * 2 * sizeof( clock_t ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
GenerateData( pData, DATA_SIZE );// 通过随机数产生数据
CUDA_SquareSum( pResult, pTime, pData, DATA_SIZE );// 执行平方和
// 在CPU中将结果组合起来
int totalResult;
for ( inti = 0; i < BLOCK_NUM; ++i )
{
totalResult += pResult[i];
}
// 计算执行的时间
clock_t startTime = pTime[0];
clock_t endTime = pTime[BLOCK_NUM];
for ( inti = 0; i < BLOCK_NUM; ++i )
{
if ( startTime > pTime[i] )startTime = pTime[i];
if ( endTime < pTime[i +BLOCK_NUM] ) endTime = pTime[i + BLOCK_NUM];
}
clock_t elapsed = endTime - startTime;
// 判断是否溢出
char* pOverFlow = nullptr;
if ( totalResult < 0 )pOverFlow = "(溢出)";
else pOverFlow = "";
// 显示基准测试
printf( "用CUDA计算平方和的结果是:%d%s\n耗费用时:%d\n",
totalResult, pOverFlow, elapsed );
cudaDeviceProp prop;
if ( cudaGetDeviceProperties(&prop, 0 ) == cudaSuccess )
{
float actualTime = float( elapsed ) / float(prop.clockRate );
printf( "实际执行时间为:%.2fms\n", actualTime );
printf( "带宽为:%.2fMB/s\n",
float( DATA_SIZE * sizeof( int )>> 20 ) * 1000.0f / actualTime );
printf( "GPU设备型号:%s\n", prop.name );
}
cudaFreeHost( pData );
cudaFreeHost( pResult );
cudaFreeHost( pTime );
return 0;
}