CUDA程序优化小记(七)
CUDA程序优化小记(七)
CUDA全称Computer Unified Device Architecture(计算机同一设备架构),它的引入为计算机计算速度质的提升提供了可能,从此微型计算机也能有与大型机相当计算的能力。可是不恰当地使用CUDA技术,不仅不会让应用程序获得提升,反而会比普通CPU的计算还要慢。最近我通过学习《GPGPU编程技术》这本书,深刻地体会到了这一点,并且用CUDA Runtime应用改写书上的例子程序;来体会CUDA技术给我们计算能力带来的提升。
原创文章,反对未声明的引用。原博客地址:http://blog.csdn.net/gamesdev/article/details/18800465
上一版的程序的性能有进一步的提高,因为使用的是共享存储器和缩减树算法。可是使用共享存储器就要注意有可能出现的bank冲突(bank conflict)问题。这一版程序我们将要采取措施尽量避免bank冲突的发生。
共享存储器是CUDA中常见的一类存储器,它位于每个多处理器内,属于片上存储器(on-chip memory)。访问速度非常快,和寄存器相仿。
warp源于纺织术,意为“经纱”,和“纬纱(weft)”相对。CUDA中的SIMT控制器以warp为单位来调度线程。在CUDA中,warp是介于块(BLOCK)和线程之间的调度单位,一般以32个线程为一个warp。GPU会对每个warp进行并行的操作,如并行访问共享存储器等。
为了最大限度地提升共享存储器的带宽,共享存储器被分为若干个内存块,称作bank。bank的特点是能够被同时访问。这些能够被同时访问的内存可以提升GPGPU程序的并行度。
由于GPU执行的并行性,在使用共享存储器的时候可能会出现Bank冲突。具体表现在一个warp内的多个线程在同一个时刻访问相同的bank。如n个线程在同一时刻访问相同的bank,那么称之为n路bank冲突(n-way bank conflict)。由于对共享存储器的访问是以半warp为单位的,即16个线程访问bank,另外16个线程执行计算,因此在出现bank冲突的时候,这些线程会被串行化(sequentialize)。这显然不符合我们设计程序的初衷。因此我们必须设计程序的访问方式来避免bank冲突。
在上一版程序中,每次缩减步骤都会有bank被多个线程访问。在计算能力1.x规范中,共享存储器分为16个bank;在计算能力2.x和3.x规范中,这一数字为32。因此,在一个warp为32线程的情况下,会出现线程0和线程16、线程32等同时访问bank0,线程1和线程17以及线程33等同时访问bank1,由此造成bank冲突。
为了解决bank冲突,我们需要重新设计计算思路。如下图:
| 线程1 |
线程2 |
线程3 |
线程4 |
线程5 |
线程6 |
线程7 |
线程8 |
| ↓ |
↓ |
↓ |
↓ |
↙ |
↙ |
↙ |
↙ |
| ↓ |
↓ |
↙ |
↙ |
|
|
|
|
| ↓ |
↙ |
|
|
|
|
|
|
| ■ |
|
|
|
|
|
|
|
在第一轮,线程5、线程6、线程7和线程8将结果分别存入bank1、bank2、bank3和bank4中;第二轮线程3、线程4将结果分别存入bank1和bank2中,这样最大限度地避免了bank冲突。这样的做法也被称为等间隔访问(strided access)。
下面是这一版程序的运行结果:
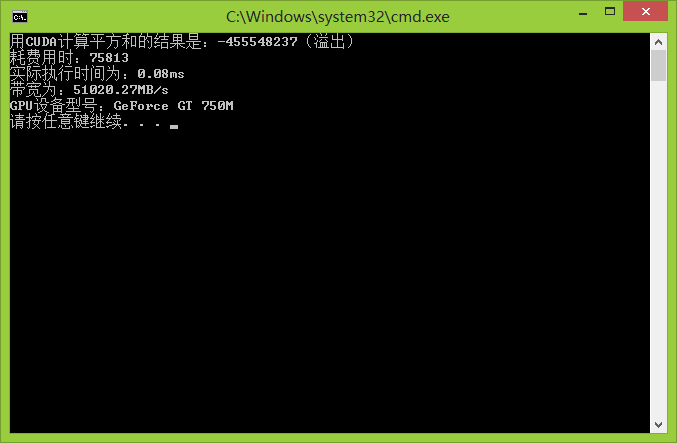
下面是各个显卡处理能力的对比:
| 显卡 |
执行时间 |
带宽 |
| GeForce 9500 GT |
0.54ms |
7416.75MB/s |
| GeForce 9600M GT |
0.485ms |
8.25GB/s |
| GeForce GT750M |
0.08ms |
51020.27MB/s |
下面是程序的所有源代码:
#include <cuda_runtime.h>
#include <cctype>
#include <cassert>
#include <cstdio>
#include <ctime>
#define DATA_SIZE 1048576
#define BLOCK_NUM 32
#define THREAD_NUM 256
#ifndef nullptr
#define nullptr 0
#endif
using namespace std;
////////////////////////在设备上运行的内核函数/////////////////////////////
__global__ static voidKernel_SquareSum( int* pIn, size_t* pDataSize,
int*pOut, clock_t* pTime )
{
// 声明一个动态分配的共享存储器
extern __shared__ int sharedData[];
const size_t computeSize =*pDataSize / THREAD_NUM;
const size_t tID = size_t(threadIdx.x );// 线程
const size_t bID = size_t(blockIdx.x );// 块
int offset = 1; // 记录每轮增倍的步距
// 开始计时
if ( tID == 0 ) pTime[bID] =clock( );// 选择任意一个线程进行计时
// 执行计算
for ( size_t i = bID * THREAD_NUM+ tID;
i < DATA_SIZE;
i += BLOCK_NUM * THREAD_NUM )
{
sharedData[tID] += pIn[i] * pIn[i];
}
// 同步一个块中的其它线程
__syncthreads( );
offset = THREAD_NUM / 2;
while ( offset > 0 )
{
if ( offset > 0 )
{
sharedData[tID] += sharedData[tID + offset];
}
offset >>= 1;
__syncthreads( );
}
if ( tID == 0 )// 如果线程ID为,那么计算结果,并记录时钟
{
pOut[bID] = sharedData[0];
pTime[bID + BLOCK_NUM] = clock( );
}
}
bool CUDA_SquareSum( int* pOut,clock_t* pTime,
int* pIn, size_tdataSize )
{
assert( pIn != nullptr );
assert( pOut != nullptr );
int* pDevIn = nullptr;
int* pDevOut = nullptr;
size_t* pDevDataSize = nullptr;
clock_t* pDevTime = nullptr;
// 1、设置设备
cudaError_t cudaStatus = cudaSetDevice( 0 );// 只要机器安装了英伟达显卡,那么会调用成功
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "调用cudaSetDevice()函数失败!" );
return false;
}
switch ( true)
{
default:
// 2、分配显存空间
cudaStatus = cudaMalloc( (void**)&pDevIn,dataSize * sizeof( int) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中数组时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevOut,BLOCK_NUM * sizeof( int) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中返回值时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevDataSize,sizeof( size_t ) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中数据大小时失败!" );
break;
}
cudaStatus = cudaMalloc( (void**)&pDevTime,BLOCK_NUM * 2 * sizeof( clock_t ) );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMalloc()函数初始化显卡中耗费用时变量失败!" );
break;
}
// 3、将宿主程序数据复制到显存中
cudaStatus = cudaMemcpy( pDevIn, pIn, dataSize * sizeof( int ),cudaMemcpyHostToDevice );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMemcpy()函数初始化宿主程序数据数组到显卡时失败!" );
break;
}
cudaStatus = cudaMemcpy( pDevDataSize, &dataSize, sizeof( size_t ), cudaMemcpyHostToDevice );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "调用cudaMemcpy()函数初始化宿主程序数据大小到显卡时失败!" );
break;
}
// 4、执行程序,宿主程序等待显卡执行完毕
Kernel_SquareSum<<<BLOCK_NUM, THREAD_NUM, THREAD_NUM *sizeof( int)>>>
( pDevIn, pDevDataSize, pDevOut, pDevTime );
// 5、查询内核初始化的时候是否出错
cudaStatus = cudaGetLastError( );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "显卡执行程序时失败!" );
break;
}
// 6、与内核同步等待执行完毕
cudaStatus = cudaDeviceSynchronize( );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在与内核同步的过程中发生问题!" );
break;
}
// 7、获取数据
cudaStatus = cudaMemcpy( pOut, pDevOut, BLOCK_NUM * sizeof( int ),cudaMemcpyDeviceToHost );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在将结果数据从显卡复制到宿主程序中失败!" );
break;
}
cudaStatus = cudaMemcpy( pTime, pDevTime, BLOCK_NUM * 2 * sizeof( clock_t ), cudaMemcpyDeviceToHost );
if ( cudaStatus != cudaSuccess)
{
fprintf( stderr, "在将耗费用时数据从显卡复制到宿主程序中失败!" );
break;
}
// 8、释放空间
cudaFree( pDevIn );
cudaFree( pDevOut );
cudaFree( pDevDataSize );
cudaFree( pDevTime );
return true;
}
// 8、释放空间
cudaFree( pDevIn );
cudaFree( pDevOut );
cudaFree( pDevDataSize );
cudaFree( pDevTime );
return false;
}
void GenerateData( int* pData,size_t dataSize )// 产生数据
{
assert( pData != nullptr );
for ( size_t i = 0; i <dataSize; i++ )
{
srand( i + 3 );
pData[i] = rand( ) % 100;
}
}
int main( int argc, char** argv )// 函数的主入口
{
int* pData = nullptr;
int* pResult = nullptr;
clock_t* pTime = nullptr;
// 使用CUDA内存分配器分配host端
cudaError_t cudaStatus = cudaMallocHost( &pData, DATA_SIZE * sizeof( int ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
cudaStatus = cudaMallocHost( &pResult, BLOCK_NUM * sizeof( int ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
cudaStatus = cudaMallocHost( &pTime, BLOCK_NUM * 2 * sizeof( clock_t ) );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "在主机中分配资源失败!" );
return 1;
}
GenerateData( pData, DATA_SIZE );// 通过随机数产生数据
CUDA_SquareSum( pResult, pTime, pData, DATA_SIZE );// 执行平方和
// 在CPU中将结果组合起来
int totalResult;
for ( inti = 0; i < BLOCK_NUM; ++i )
{
totalResult += pResult[i];
}
// 计算执行的时间
clock_t startTime = pTime[0];
clock_t endTime = pTime[BLOCK_NUM];
for ( inti = 0; i < BLOCK_NUM; ++i )
{
if ( startTime > pTime[i] )startTime = pTime[i];
if ( endTime < pTime[i +BLOCK_NUM] ) endTime = pTime[i + BLOCK_NUM];
}
clock_t elapsed = endTime - startTime;
// 判断是否溢出
char* pOverFlow = nullptr;
if ( totalResult < 0 )pOverFlow = "(溢出)";
else pOverFlow = "";
// 显示基准测试
printf( "用CUDA计算平方和的结果是:%d%s\n耗费用时:%d\n",
totalResult, pOverFlow, elapsed );
cudaDeviceProp prop;
if ( cudaGetDeviceProperties(&prop, 0 ) == cudaSuccess )
{
float actualTime = float( elapsed ) / float(prop.clockRate );
printf( "实际执行时间为:%.2fms\n", actualTime );
printf( "带宽为:%.2fMB/s\n",
float( DATA_SIZE * sizeof( int )>> 20 ) * 1000.0f / actualTime );
printf( "GPU设备型号:%s\n", prop.name );
}
cudaFreeHost( pData );
cudaFreeHost( pResult );
cudaFreeHost( pTime );
return 0;
}
参考文献:
《CUDA C Programming Guide(NVIDIA inc.)》电子书