IME
IME(input method editor),输入法编辑器是允许用户使用标准键盘输入复杂字母与符号,也就是说因为我们一般的KEY处理并不能处理复杂字母与符号的输入,这时就扩展出IME用来管理键盘输入根据特殊的组合形成相应的文字,符号等。值得注意的是,IME并不检索用户用到的的所字符值,而是监控用户的按键,来预料用户可能需要的字符。
一般IME的组成有状态视窗,可以键入并选择备择字符的IME视窗和一张备择字符列表以供用户从中选出所需字符。如下图GBono IME:
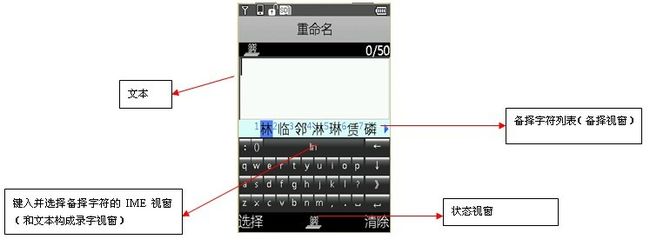
状态视窗指示IME被打开,并向用户提供设置转换模式的方法(GBONO提供的有拼音输入法,笔画输入法,大小写英语,数字等);
录字视窗指在用户输入文本时,显示的视窗,主要依赖转换模式显示输入文本或转换后的文本
备择视窗指在录字视窗出现时选的备择字符或录字视窗中的字符,用户可以滚动备择列表来选择所需的字符,然后返回至录字视窗。
了解了大概的布局,现在看看IME的原理:
从键盘等字符输入设备截取字符,即将标准ASCII字符串按照一定的编码规则转换为汉字、汉字串或其他字符串,进入到目的地(自己设计的转换程序),从而转化成相应的字符显示。(如下图)

另外,对于IME ASCII转化成另一个字符时,涉及到了编码问题(尤其是汉字编码),下面一些编码知识。
ASCII码:ASCII是7位编码,编码范围:0x00~0x7F.ASCII字符集包含英文字母,阿拉伯数字和标点符号字符等.其中0x00-0x20和0x7F共33个控制字符,只支持ASCII码的系统会忽略最高位,只认为低7位是有效的。但现在由于 ANSI 标准使用单一字节表示每个字符,因此最多只能有 256 个字符和标点符号代码。虽然对英语来说已经足够了,但不能完全支持其它语言
UNICODE码:每种语言都有相应的编码页,增加了那些支持多语言软件的复杂度。因而出现了UNICODE码。为每一个字符提供唯一特定的值,不论在什么平台上,用什么语言。
UNICODE是双字节全编码,对于ASCII码也采取双字节编码。UNICODE码有三套编码方式。它们分别是UTF-8,UTF-16BE, UTF-16LE,UTF-32BE和UTF-32LE(Unicode Transformation Format,其中LE小端和BE大端为字节序).正如名字所示,在UTF-8中,字符是以8位序列来编码的,用一个或几个字节来表示一个字符(这种方式最大好处是UTF-8保留了ASCII字符的编码作为它的一部分,A还是0X41)。UTF-16和UTF-32分别是UNICODE的16位和32位编码方式,一般说的UNICODE码为UTF-16。下面为“汉字”各个UNICODE编码,数字为0x6c49和0x5b57。
| 字符集 |
编码 |
| UTF-8 |
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; |
| UTF-16BE |
WORD data_utf16[] = {0x6c49, 0x5b57}; |
| UTF-16LE |
WORD data_utf16[] = {0x496c, 0x575b}; |
| UTF-32BE |
DWORD data_utf32[] = {0x6c49, 0x5b57}; |
| UTF-32LE |
DWORD data_utf32[] = {0x496c0000, 0x575b0000}; |
| ASCII |
BYTE data_ascii[] = {0xba,0xba,0xd7,0xd6}; |
下面讲unicode的各种字符集。
UTF8: 特点是对不同范围的字符使用不同长度的编码,对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节,汉字为三个字节表示一个汉字。
UTF-8以字节为单位对UNICODE进行编码。从UNICODE到UTF-8编码方式如下:
| Unicode编码 |
UTF-8字节流 |
| 000000 – 00007F |
0xxxxxxx |
| 000080 – 0007FF |
110xxxxx 10xxxxxx |
| 000800-00FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF |
11110xxx 10xxxxxx 10xxxxxx |
| 举个例子,以“汉”字的UNICODE编码是0x6C49.在000800-00FFFF之间,使用了3字节:1110xxxx 10xxxxxx 10xxxxxx,我们把0x6c49写成二进制是:0110 1100 0100 1001,用这个比特流依次代替模版中的x,得11100110 10110001 10001001,即E6 B1 89
UTF-16:编码以16位无符号整数为单位。 |
|
| UTF-16 |
二进制 |
| 0x000000~0x00FFFF |
原型(汉字在里面) |
| 0x010000~0x10FFFF |
U’=U - 0x10000, U’转换后写成yyyy yyyy yyxx xxxx xxxx UTF-16编码为:1101 10yy yyyy yyyy 1101 11xx xxxx xxxx |
同样举个例子,0x20C30
U’ = 0x20C30 – 0x10000 = 0x10C30,写成二进制是:0001 0000 1100 0011 0000,用模版代替则1101 1000 0100 0011 1101 1100 0011 0000,即0Xd843 0xdc30
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,UNICODE编码的设计者将0Xd800-0xdfff保留下来,并称为代理区:
| D800-DB7F |
High Surrogates(高位替代) |
| DB80-DBFF |
High Private Use Surrogates(高位专用替代) |
| DC00-DFFF |
Low Surrogates(低位替代) |
也就是这个区的数字为两个WORD的UTF-16编码区分显示。如果有两个word UTF-16要得出UNICODE可根据模版,去掉标志位,然后加上0x10000,即反步骤可得出UNICODE编码。
UTF-32编码则以32位无符号整数为单位,UNICODE的UTF-32编码就是其对应的32位无符号整数。
注:4E00-9FBF为中文范围 0000-007F为C0控制符及基本拉丁文
字节序:分为大端(Big Endian)和小端(LittleEndian),BE和LE是跟CPU有关的,一般都是Litter Endian。大小端只对多字节才有区分。 低地址--- >高地址
BIG ENDIAN是低位字节排放在内存的高端。即 0x05060708,则存在是05 06 07 08
LITTLE ENDIAN是高位字节排放在内存的低端。0x05060708,则是 08 07 06 05
另外,怎么判断字节流顺序,有个BOM(BYTE ORDER MARK)的概念,即在传输字节流前,先传输被作为BOM的字符”零宽无中断空格”,这个字符的编码是FEFF,而反过来的FFFE和FFFE0000在UNICODE中都是未定义的码位,不应该出现在实际的传输中,下表为UTF编码的BOM。
| UTF编码 |
BOM |
| UTF-8 |
EF BB BF |
| UTF-16LE |
FF FE |
| UTF-16BE |
FE FF |
| UTF-32LE |
FF FE 00 00 |
| UTF-32BE |
00 00 FE FF |
汉字编码:
ASCII码的汉字编码(ANSI本地化)有GB2312,HZ,big5等编码(互不兼容)
UNICODE码的汉字编码则在4E00-9FBF
对于ASCII的汉字编码,我们大概了解下GB2312, BIG5,GBK这三种编码。
GB2312: 为了区别ASCII码,ASCII码都是从A1开始,也就是说A1 A1代表着第一个区的第一个字。如果要得到区位码,则只要区位码减去A0 A0则可。区位码具体可看FONT如何显示汉字。第一字节,行码0xA1-0xFE,第二节字,列码0xA1-0xFE,每行94个汉字。其中,1-15行(A1-AF)全角字母、符号;16-55行(B0-CF)以拼音为序的一级汉字3755字;56-87行(D0-F7)以部首为序的二级汉字3008字。
BIG5: 第一节字,行码0x81-0xFE(其中0x81~0Xa0为自定义字符区),第二节字,列码0x40-0x7E,0xA1-0xFE,每行157个汉字;其中,1-3/38-40行(A1-A3,C6-C8)全角字母、符号,4-39行(A4-C6)一级汉字5401字,41-89行(C9-F9)二级汉字7652字。具体可查阅BIG5标准。(二个字节是小于7FH的汉字为big5)
GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位, GBK同时也涵盖了Unicode所有CJK汉字. 该编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GBK的整体编码范围是为0x8140-0xFEFE,不包括低字节是0×7F的组合。高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE。
了解了上面大概的基础知识,对于IME就可以进行构造了!
在下载那有一个简单的IME实现