data-intensive text processing with mapreduce-Inverted Indexing for Text Retrieval
Inverted Indexing for Text Retrieval
Inverted Indexing
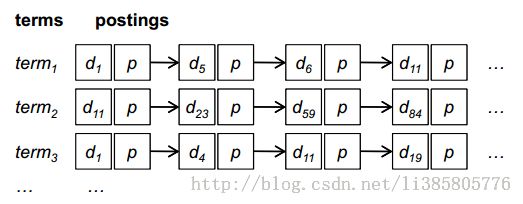
Baseline Algorithm
MainIdea:map的输入为文档编号和文档的内容,输出为[ 词 , (文档编号,词频)],reduce将同一个词的所有文档编号和词频聚集,然后按文档编号排序,最后输出的是按文档编号由小到大排序的项。


Discussion:
存在规模瓶颈,一个词的所有(文档,词频)项可能不足以存放在内存当中,无法实现内部排序。
Inverted Indexing: Revised Implementation
MainIdea:使用value-to-key conversion design pattern,map输出[ ( 词,文档编号) 项,自定义partitioner和排序方式,保证reduce的输入中同一词,按文档编号有序作排列,省去了实现排序的过程。

程序代码如下:
package InvertedIndexing;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.HashMap;
/**
* Created with IntelliJ IDEA.
* User: ubuntu
* Date: 13-11-22
* Time: 上午10:07
* To change this template use File | Settings | File Templates.
*/
public class RevisedInvertedIndexing extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "RevisedInvertedIndexing");
job.setJarByClass(RevisedInvertedIndexing.class);
job.setInputFormatClass(MyInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
MyInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Item.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(MyPartitioner.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new RevisedInvertedIndexing(), args);
System.exit(exitCode);
}
public static class Item implements WritableComparable {
private String term;
private String docName;
public Item() {
this.term = "";
}
public String getTerm() {
return term;
}
public void setTerm(String term) {
this.term = term;
}
public String getDocName() {
return docName;
}
public void setDocName(String docName) {
this.docName = docName;
}
@Override
public int compareTo(Object o) {
Item that = (Item) o;
int cmp = this.getTerm().compareTo(that.getTerm());
if (cmp != 0) {
return cmp;
} else {
return this.getDocName().compareTo(that.getDocName());
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(term);
out.writeUTF(docName);
}
@Override
public void readFields(DataInput in) throws IOException {
this.term = in.readUTF();
this.docName = in.readUTF();
}
@Override
public int hashCode() {
return term.hashCode() + docName.hashCode();
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
Item that = (Item) obj;
if (this.getTerm().equals(that.getTerm())) {
return this.getDocName().equals(that.getDocName());
} else {
return false;
}
}
@Override
public String toString() {
return "("+term.toString()+","+docName.toString()+")";
}
}
public static class MyPartitioner extends Partitioner<Item, LongWritable> {
@Override
public int getPartition(Item term, LongWritable i, int numPartitions) {
return term.getTerm().hashCode() * 12 % numPartitions;
}
}
public static class MyMapper extends Mapper<Text, Text, Item, LongWritable> {
private Item outKey = new Item();
private LongWritable outValue = new LongWritable();
private HashMap<String, Long> hashMap;
private String docName;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
hashMap = new HashMap<String, Long>();
}
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
if (docName == null) {
docName = key.toString();
}
for (String word : words) {
if (word.startsWith("\"")) {
word = word.substring(1);
}
while (word.endsWith("\"") || word.endsWith(".") || word.endsWith(",") || word.endsWith(" ")) {
word = word.substring(0, word.length() - 1);
}
addItem(word);
}
}
private void addItem(String word) {
if (hashMap.containsKey(word)) {
hashMap.put(word, hashMap.get(word) + 1);
} else {
hashMap.put(word, 1L);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (String s : hashMap.keySet()) {
outKey.setTerm(s);
outKey.setDocName(docName);
outValue.set(hashMap.get(s));
context.write(outKey,outValue);
// System.out.println(outKey.toString()+"-"+outValue.toString()+"\t");
}
}
}
public static class MyReduce extends Reducer<Item, LongWritable, Text, Text> {
private String preTerm = null;
private String term;
private StringBuilder outValueString = new StringBuilder();
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void reduce(Item key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
term = key.getTerm();
// if (term.equals(preTerm) || preTerm == null) {
// preTerm = term;
//
// } else {
// outKey.set(preTerm);
// outValue.set(outValueString.toString());
// context.write(outKey,outValue);
// preTerm = term;
// outValueString.delete(0, outValueString.length());
// }
if (term.equals(preTerm) == false && preTerm != null) {
outKey.set(preTerm);
outValue.set(outValueString.toString());
context.write(outKey,outValue);
outValueString.delete(0, outValueString.length());
}
preTerm = term;
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
if (outValueString.length() == 0) {
outValueString.append(key.getDocName() + "-" + sum);
}else {
outValueString.append(" " + key.getDocName() + "-" + sum);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
outKey.set(term);
outValue.set(outValueString.toString());
context.write(outKey,outValue);
}
}
public static class MyInputFormat extends FileInputFormat<Text, Text> {
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
return new MyRecordReader();
}
}
public static class MyRecordReader extends RecordReader<Text, Text> {
private LineRecordReader lineRecordReader;
private FileSplit fileSplit;
private Text key;
private Text value;
private TaskAttemptContext taskAttemptContext;
public MyRecordReader() {
key = new Text();
value = new Text();
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
fileSplit = (FileSplit) split;
key.set(fileSplit.getPath().getName());
taskAttemptContext = context;
lineRecordReader = new LineRecordReader();
lineRecordReader.initialize(split, context);
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
boolean hasNext = lineRecordReader.nextKeyValue();
value = lineRecordReader.getCurrentValue();
return hasNext;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return lineRecordReader.getProgress();
}
@Override
public void close() throws IOException {
}
}
}
注意:自定义的RecordReader用了装饰模式,持有一个LineRecordReader,只用LineRecordReader获取文本内容作为value,而Key则是通过split获取文件名(这里没有使用文档编号,而直接采用了文件名),Mapper中使用了in-mapper combining
Reduce中的write也可以改变技巧,在每一次reduce执行完毕的时候写出,当前的策略是调用reduce时写出针对上一次的key调用reduce的操作结果。最后一次reduce的结果再cleanup中写出