Spark修炼之道(进阶篇)——Spark入门到精通:第十节 Spark Streaming(一)
本节主要内容
本节部分内容来自官方文档:http://spark.apache.org/docs/latest/streaming-programming-guide.html#mllib-operations
- Spark流式计算简介
- Spark Streaming相关核心类
- 入门案例
1. Spark流式计算简介
Hadoop的MapReduce及Spark SQL等只能进行离线计算,无法满足实时性要求较高的业务需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较常用的流式计算框架,它们分别是Storm,Spark Streaming和Samza,各个框架的比较及使用情况,可以参见:http://www.csdn.net/article/2015-03-09/2824135。本节对Spark Streaming进行重点介绍,Spark Streaming作为Spark的五大核心组件之一,其原生地支持多种数据源的接入,而且可以与Spark MLLib、Graphx结合起来使用,轻松完成分布式环境下在线机器学习算法的设计。Spark支持的输入数据源及输出文件如下图所示:

在后面的案例实战当中,会涉及到这部分内容。中间的”Spark Streaming“会对输入的数据源进行处理,然后将结果输出,其内部工作原理如下图所示:
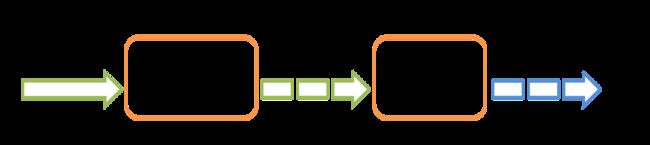
Spark Streaming接受实时传入的数据流,然后将数据按批次(batch)进行划分,然后再将这部分数据交由Spark引擎进行处理,处理完成后将结果输出到外部文件。
先看下面一段基于Spark Streaming的word count代码,它可以很好地帮助初步理解流式计算
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: StreamingWordCount <directory>")
System.exit(1)
}
//创建SparkConf对象
val sparkConf = new SparkConf().setAppName("HdfsWordCount").setMaster("local[2]")
// Create the context
//创建StreamingContext对象,与集群进行交互
val ssc = new StreamingContext(sparkConf, Seconds(20))
// Create the FileInputDStream on the directory and use the
// stream to count words in new files created
//如果目录中有新创建的文件,则读取
val lines = ssc.textFileStream(args(0))
//分割为单词
val words = lines.flatMap(_.split(" "))
//统计单词出现次数
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//打印结果
wordCounts.print()
//启动Spark Streaming
ssc.start()
//一直运行,除非人为干预再停止
ssc.awaitTermination()
}
}运行上面的程序后,再通过命令行界面,将文件拷贝到相应的文件目录,具体如下:
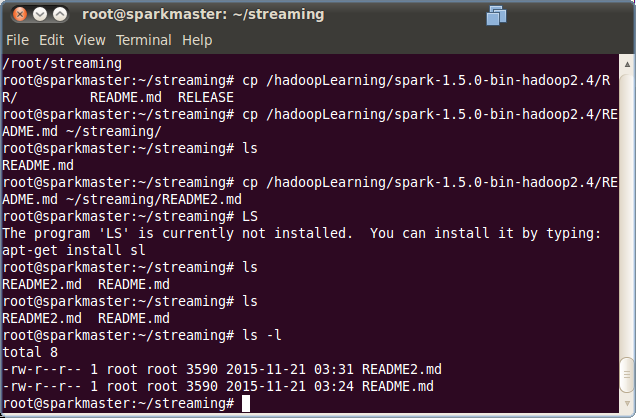
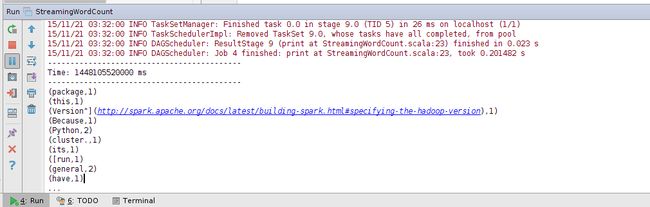
程序在运行时,根据文件创建时间对文件进行处理,在上一次运行时间后创建的文件都会被处理,输出结果如下:
2. Spark Streaming相关核心类
1. DStream(discretized stream)
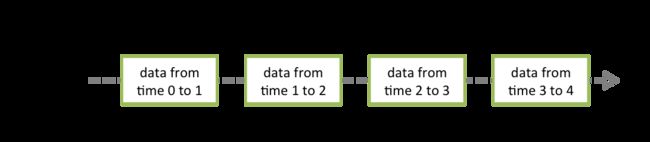
Spark Streaming提供了对数据流的抽象,它就是DStream,它可以通过前述的 Kafka, Flume等数据源创建,DStream本质上是由一系列的RDD构成。各个RDD中的数据为对应时间间隔( interval)中流入的数据,如下图所示:
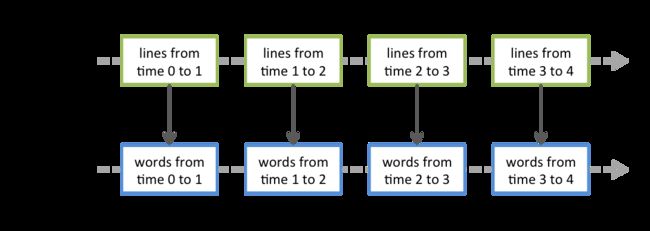
对DStream的所有操作最终都要转换为对RDD的操作,例如前面的StreamingWordCount程序,flatMap操作将作用于DStream中的所有RDD,如下图所示:
2.StreamingContext
在Spark Streaming当中,StreamingContext是整个程序的入口,其创建方式有多种,最常用的是通过SparkConf来创建:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))创建StreamingContext对象时会根据SparkConf创建SparkContext
/** * Create a StreamingContext by providing the configuration necessary for a new SparkContext. * @param conf a org.apache.spark.SparkConf object specifying Spark parameters * @param batchDuration the time interval at which streaming data will be divided into batches */
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}也就是说StreamingContext是对SparkContext的封装,StreamingContext还有其它几个构造方法,感兴趣的可以了解,后期在源码解析时会对它进行详细的讲解,创建StreamingContext时会指定batchDuration,它用于设定批处理时间间隔,需要根据应用程序和集群资源情况去设定。当创建完成StreamingContext之后,再按下列步骤进行:
- 通过输入源创建InputDStreaim
- 对DStreaming进行transformation和output操作,这样操作构成了后期流式计算的逻辑
- 通过StreamingContext.start()方法启动接收和处理数据的流程
- 使用streamingContext.awaitTermination()方法等待程序处理结束(手动停止或出错停止)
- 也可以调用streamingContext.stop()方法结束程序的运行
关于StreamingContext有几个值得注意的地方:
1.StreamingContext启动后,增加新的操作将不起作用。也就是说在StreamingContext启动之前,要定义好所有的计算逻辑
2.StreamingContext停止后,不能重新启动。也就是说要重新计算的话,需要重新运行整个程序。
3.在单个JVM中,一段时间内不能出现两个active状态的StreamingContext
4.调用StreamingContext的stop方法时,SparkContext也将被stop掉,如果希望StreamingContext关闭时,保留SparkContext,则需要在stop方法中传入参数stopSparkContext=false
/**
* Stop the execution of the streams immediately (does not wait for all received data
* to be processed). By default, if stopSparkContext is not specified, the underlying
* SparkContext will also be stopped. This implicit behavior can be configured using the
* SparkConf configuration spark.streaming.stopSparkContextByDefault.
*
* @param stopSparkContext If true, stops the associated SparkContext. The underlying SparkContext
* will be stopped regardless of whether this StreamingContext has been
* started.
*/
def stop(
stopSparkContext: Boolean = conf.getBoolean(“spark.streaming.stopSparkContextByDefault”, true)
): Unit = synchronized {
stop(stopSparkContext, false)
}
5.SparkContext对象可以被多个StreamingContexts重复使用,但需要前一个StreamingContexts停止后再创建下一个StreamingContext对象。
3. InputDStreams及Receivers
InputDStream指的是从数据流的源头接受的输入数据流,在前面的StreamingWordCount程序当中,val lines = ssc.textFileStream(args(0)) 就是一种InputDStream。除文件流外,每个input DStream都关联一个Receiver对象,该Receiver对象接收数据源传来的数据并将其保存在内存中以便后期Spark处理。
Spark Streaimg提供两种原生支持的流数据源:
Basic sources(基础流数据源)。直接通过StreamingContext API创建,例如文件系统(本地文件系统及分布式文件系统)、Socket连接及Akka的Actor。
文件流(File Streams)的创建方式:
a. streamingContext.fileStreamKeyClass, ValueClass, InputFormatClass
b. streamingContext.textFileStream(dataDirectory)
实时上textFileStream方法最终调用的也是fileStream方法
def textFileStream(directory: String): DStream[String] = withNamedScope(“text file stream”) {
fileStreamLongWritable, Text, TextInputFormat.map(_._2.toString)
}基于Akka Actor流数据的创建方式:
streamingContext.actorStream(actorProps, actor-name)基于Socket流数据的创建方式:
ssc.socketTextStream(hostname: String,port: Int,storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2)基于RDD队列的流数据创建方式:
streamingContext.queueStream(queueOfRDDs)Advanced sources(高级流数据源)。如Kafka, Flume, Kinesis, Twitter等,需要借助外部工具类,在运行时需要外部依赖(下一节内容中介绍)
Spark Streaming还支持用户
3. Custom Sources(自定义流数据源),它需要用户定义receiver,该部分内容也放在下一节介绍
最后有两个需要注意的地方:
- 在本地运行Spark Streaming时,master URL不能使用“local” 或 “local[1]”,因为当input DStream与receiver(如sockets, Kafka, Flume等)关联时,receiver自身就需要一个线程来运行,此时便没有线程去处理接收到的数据。因此,在本地运行SparkStreaming程序时,要使用“local[n]”作为master URL,n要大于receiver的数量。
- 在集群上运行Spark Streaming时,分配给Spark Streaming程序的CPU核数也必须大于receiver的数量,否则系统将只接受数据,无法处理数据。
3. 入门案例
为方便后期查看运行结果,修改日志级别为Level.WARN
import org.apache.spark.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}- NetworkWordCount
基于Socket流数据
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
//修改日志层次为Level.WARN
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[4]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
//创建SocketInputDStream,接收来自ip:port发送来的流数据
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}配置运行时参数
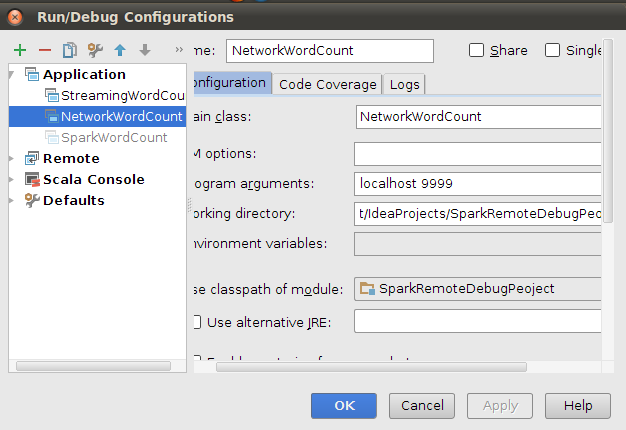
使用
//启动netcat server
root@sparkmaster:~/streaming# nc -lk 9999
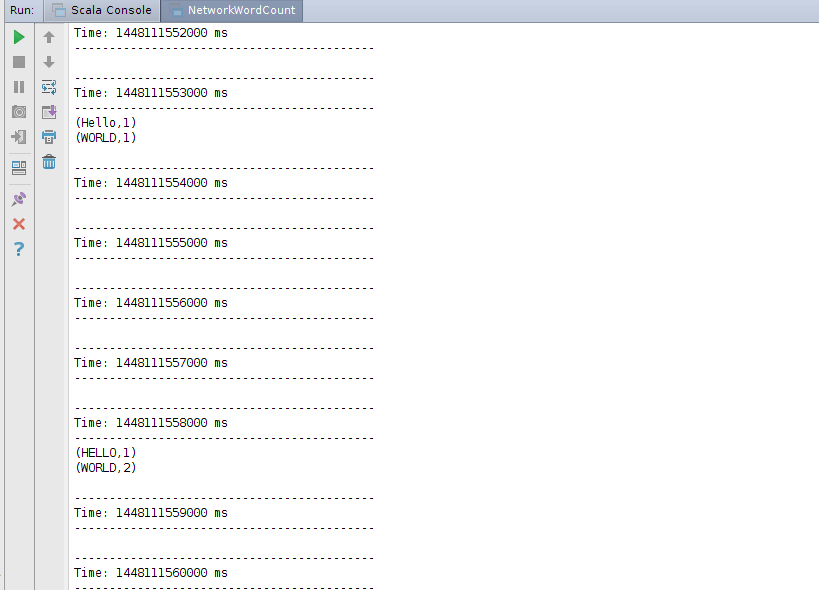
运行NetworkWordCount 程序,然后在netcat server运行的控制台输入任意字符串
root@sparkmaster:~/streaming# nc -lk 9999
Hello WORLD
HELLO WORLD WORLD
TEWST
NIMA
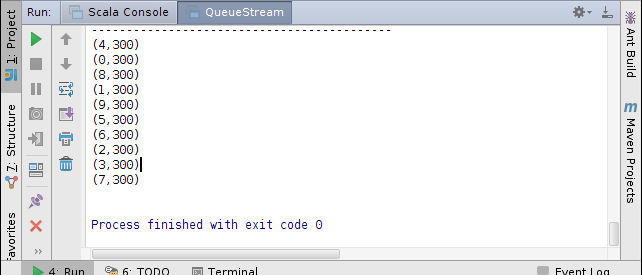
- QueueStream
基于RDD队列的流数据
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object QueueStream {
def main(args: Array[String]) {
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("QueueStream").setMaster("local[4]")
// Create the context
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create the queue through which RDDs can be pushed to
// a QueueInputDStream
//创建RDD队列
val rddQueue = new mutable.SynchronizedQueue[RDD[Int]]()
// Create the QueueInputDStream and use it do some processing
// 创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue)
//处理队列中的RDD数据
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
//启动计算
ssc.start()
// Create and push some RDDs into
for (i <- 1 to 30) {
rddQueue += ssc.sparkContext.makeRDD(1 to 3000, 10)
Thread.sleep(1000)
//通过程序停止StreamingContext的运行
ssc.stop()
}
}