Spark计算Pi运行过程详解---Spark学习笔记4
上回运行了一个计算Pi的例子
那么Spark究竟是怎么执行的呢?
我们来看一下脚本
#!/bin/sh
export YARN_CONF_DIR=/home/victor/software/hadoop-2.2.0/etc/hadoop
SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly-0.8.1-incubating-hadoop2.2.0.jar \
./spark-class org.apache.spark.deploy.yarn.Client \
--jar ./examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar \
--class org.apache.spark.examples.JavaSparkPi \
--args yarn-standalone \
--num-workers 2 \
--master-memory 400m \
--worker-memory 512m \
--worker-cores 1
首先看,设置环境变量
export YARN_CONF_DIR=/home/victor/software/hadoop-2.2.0/etc/hadoop
这里要设置yarn的配置文件地址,因为要运行在yarn上,所以需要这个
我们打开spark-class文件,这个shell是运行程序的入口,可以清晰的看到,其实这个文件就是执行java命令,将一些前置的java options和所需要的CLASSPATH加入,并且运行后面传入的参数。
more spark-class
# Compute classpath using external script
CLASSPATH=`$FWDIR/bin/compute-classpath.sh`
CLASSPATH="$SPARK_TOOLS_JAR:$CLASSPATH"
export CLASSPATH
if [ "$SPARK_PRINT_LAUNCH_COMMAND" == "1" ]; then
echo -n "Spark Command: "
echo "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@"
echo "========================================"
echo
fi
exec "$RUNNER" -cp "$CLASSPATH" $JAVA_OPTS "$@"
这里设置classpath还引用到了$SPARK_HOME/bin/compute-classpath.sh,这个就是将spark所以的assembly的jar都加入classpath,将yarn的配置到classpath中。
more $SPARK_HOME/bin/compute-classpath.sh
# Load environment variables from conf/spark-env.sh, if it exists if [ -e $FWDIR/conf/spark-env.sh ] ; then . $FWDIR/conf/spark-env.sh fi # Build up classpath CLASSPATH="$SPARK_CLASSPATH:$FWDIR/conf" if [ -f "$FWDIR/RELEASE" ]; then ASSEMBLY_JAR=`ls "$FWDIR"/jars/spark-assembly*.jar` else ASSEMBLY_JAR=`ls "$FWDIR"/assembly/target/scala-$SCALA_VERSION/spark-assembly*hadoop*.jar` fi CLASSPATH="$CLASSPATH:$ASSEMBLY_JAR" # Add test classes if we're running from SBT or Maven with SPARK_TESTING set to 1 if [[ $SPARK_TESTING == 1 ]]; then CLASSPATH="$CLASSPATH:$FWDIR/core/target/scala-$SCALA_VERSION/test-classes" CLASSPATH="$CLASSPATH:$FWDIR/repl/target/scala-$SCALA_VERSION/test-classes" CLASSPATH="$CLASSPATH:$FWDIR/mllib/target/scala-$SCALA_VERSION/test-classes" CLASSPATH="$CLASSPATH:$FWDIR/bagel/target/scala-$SCALA_VERSION/test-classes" CLASSPATH="$CLASSPATH:$FWDIR/streaming/target/scala-$SCALA_VERSION/test-classes" fi # Add hadoop conf dir if given -- otherwise FileSystem.*, etc fail ! # Note, this assumes that there is either a HADOOP_CONF_DIR or YARN_CONF_DIR which hosts # the configurtion files. if [ "x" != "x$HADOOP_CONF_DIR" ]; then CLASSPATH="$CLASSPATH:$HADOOP_CONF_DIR" fi if [ "x" != "x$YARN_CONF_DIR" ]; then CLASSPATH="$CLASSPATH:$YARN_CONF_DIR" fi echo "$CLASSPATH"
其实执行的就是 java -cp $CLASSPATH $JAVA_OPTS org.apache.spark.deploy.yarn.Client
这个类顾名思义spark.deploy.yarn.Client,将spark的应用程序部署到yarn上去的Client
这个类做的事情也很简单,就是设置是否运行在yarn上,设置运行应用程序需要的参数。
object Client {
val SPARK_JAR: String = "spark.jar"
val APP_JAR: String = "app.jar"
val LOG4J_PROP: String = "log4j.properties"
def main(argStrings: Array[String]) {
// Set an env variable indicating we are running in YARN mode.
// Note that anything with SPARK prefix gets propagated to all (remote) processes
System.setProperty("SPARK_YARN_MODE", "true")
val args = new ClientArguments(argStrings)
new Client(args).run
}
这是入口函数,设置spark_yan_mode是true,传入后面的参数,初始化一个Client,然后执行Run方法。
接下来看一下Client这个类的构造方法:
class Client(conf: Configuration, args: ClientArguments) extends YarnClientImpl with Logging {
def this(args: ClientArguments) = this(new Configuration(), args)
var rpc: YarnRPC = YarnRPC.create(conf)
val yarnConf: YarnConfiguration = new YarnConfiguration(conf)
val credentials = UserGroupInformation.getCurrentUser().getCredentials()
private val SPARK_STAGING: String = ".sparkStaging"
private val distCacheMgr = new ClientDistributedCacheManager()
// Staging directory is private! -> rwx--------
val STAGING_DIR_PERMISSION: FsPermission = FsPermission.createImmutable(0700:Short)
// App files are world-wide readable and owner writable -> rw-r--r--
val APP_FILE_PERMISSION: FsPermission = FsPermission.createImmutable(0644:Short)
// for client user who want to monitor app status by itself.
def runApp() = {
validateArgs()
init(yarnConf)
start()
logClusterResourceDetails()
val newApp = super.getNewApplication()
val appId = newApp.getApplicationId()
verifyClusterResources(newApp)
val appContext = createApplicationSubmissionContext(appId)
val appStagingDir = getAppStagingDir(appId)
val localResources = prepareLocalResources(appStagingDir)
val env = setupLaunchEnv(localResources, appStagingDir)
val amContainer = createContainerLaunchContext(newApp, localResources, env)
appContext.setQueue(args.amQueue)
appContext.setAMContainerSpec(amContainer)
appContext.setUser(UserGroupInformation.getCurrentUser().getShortUserName())
submitApp(appContext)
appId
}
1.创建YARN的RPC句柄,可以使用RPC来调用YARN。
2.初始化YarnConfiguration
3.Credentials用户权限的验证初始化。
4.初始化DistributeCache分发应用程序相关jar和文件到各个计算节点上。
然后执行run方法。
def run() {
val appId = runApp()
monitorApplication(appId)
System.exit(0)
}
在看runApp方法
1.初始化,传入参数
就是执行脚本后面的
--jar spark-examples-assembly-0.8.1-incubating.jar
--class org.apache.spark.examples.JavaSparkPi //计算Pi,这里是java程序
--worker的个数,master的内存大小,worker内存大小。。。等等等等参数,不一一解释了。
2.提交应用程序及请求资源的上下文
3.返回程序ID
4.然后客户端就会持续监控程序的运行状态。就会出现前面我们看见到的log情况
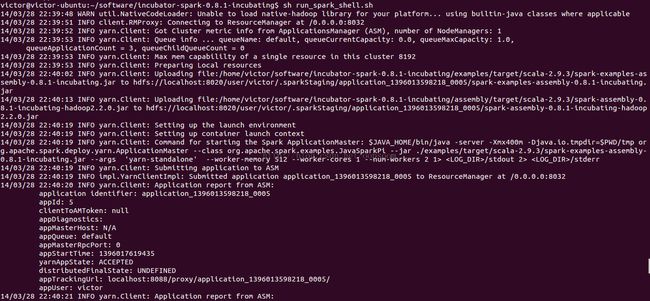
至此,这个例子就完成了,不过官方例子还有一个简单的方式运行
在$SPARK_HOME下有一个run-example的shell
直接执行./run-example org.apache.spark.examples.SparkPi local
victor@victor-ubuntu:~/software/spark$ ./run-example org.apache.spark.examples.SparkPi local log4j:WARN No appenders could be found for logger (org.apache.spark.util.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Pi is roughly 3.143
<原创,转载请注明出处http://blog.csdn.net/oopsoom/article/details/22619765>