MDX 生成复杂的集合
order(表达式, 排序的度量值, desc| asc| bdesc| basc) 函数.
Hierarchize函数. 把所有的行, 安装他们应有的层次结构排序
bottomCount 和topCount类似, 只是功能不一样. 可以看看
Head函数(http://msdn.microsoft.com/zh-cn/library/ms144859(v=SQL.105)),返回集中位置靠前的指定数目的元素,同时保留重复项。Head 函数从指定集的开始处返回指定的元组数目。并保留元素的顺序。Count 的默认值为 1。如果指定的元组数目小于 1,则 Head 函数返回空集。如果指定的元组数目超过了集中的元组数目,则此函数返回原始集。
Tail函数(http://msdn.microsoft.com/zh-cn/library/ms146056.aspx),Tail 函数从指定集的结尾处返回指定的元组数目。 会保留元素的顺序。 Count 的默认值为 1。如果指定的元组数目小于 1,则该函数返回空集。 如果指定的元组数目超过了集中的元组数目,则此函数返回原始集。
Item函数. 理解是返回一个成员.
Filter(Set_Expression, Logical_Expression )
union(set,set), Except(set,set)第一个set大于第二个set, Intersect(set,set)并集
Generate( Set_Expression1 , Set_Expression2 [ , ALL ] ) 将一个集应用于另一个集中的每个成员,然后对得到的集求并集。另外,此函数返回通过用字符串表达式对集求值而创建的串联字符串。
order
SELECT
{([Measures].[Reseller Sales Amount])} ON COLUMNS,
Order(
{[Product].[Category].[Category].Members} *
{[Product].[Subcategory].[Subcategory].Members},
([Measures].[Reseller Sales Amount]),
DESC
) ON ROWS
FROM[Step-by-Step]
;
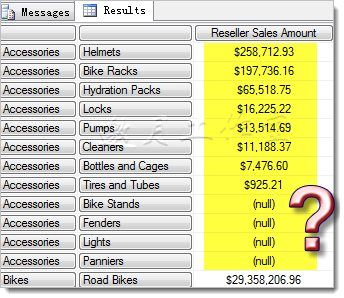
在上面的查询中,交叉联接使用默认排序,而且后面指定了([Measures].[Reseller Sales Amount])排序,但是大家注意到没有,这一列并没有按照指定的数值排序,为什么呢?因为默认的ASC和DESC是分层的(hierarchical),换句话说,这些元组的前一个成员的排序被保留了。为了打乱这个层次结构,可以使用BASC和BDESC(http://msdn.microsoft.com/zh-cn/library/ms145587(v=SQL.105))。
hierarchize

item函数
WITH
MEMBER [Measures].[Top Product Sales]AS
{
EXISTING
TopCount(
[Product].[Product].[Product].Members,
1,
([Measures].[Internet Sales Amount])
) *
{[Measures].[Internet Sales Amount]}
}.Item(0)
,FORMAT_STRING="Currency"
MEMBER [Measures].[Top Product Name]AS
{
EXISTING
TopCount(
[Product].[Product].[Product].Members,
1,
([Measures].[Internet Sales Amount])
)
}.Item(0).Item(0).Name
MEMBER [Measures].[Top ProductValue Name]AS
{
EXISTING
TopCount(
[Product].[Product].[Product].Members,
2,
([Measures].[Internet Sales Amount])
)*
{[Measures].[Internet Sales Amount]}
}.Item(1).Item(1).Name
SELECT
{
([Measures].[Internet Sales Amount]),
([Measures].[Top Product Sales]),
([Measures].[Top Product Name])
,([Measures].[Top ProductValue Name])
} ON COLUMNS,
{
([Date].[Calendar Year].[CY 2001]):
([Date].[Calendar Year].[CY 2004])
} ON ROWS
FROM[Step-by-Step]
;

item函数, 是一个很有意思的函数. 我们先来看([Measures].[Top Product Sales]), 这是第二列.
是由 得到的. 这是什么意思呢. 我是这么理解的. 返回按照internet Sales Amount排序的最高的产品. 然后乘以internet Sales Amount度量值. 得到一个正方形. 之所以需要加existing关键字. 是因为, 这个正方形是需要被
得到的. 这是什么意思呢. 我是这么理解的. 返回按照internet Sales Amount排序的最高的产品. 然后乘以internet Sales Amount度量值. 得到一个正方形. 之所以需要加existing关键字. 是因为, 这个正方形是需要被 ![]() 切割的. 不过. 经过测试 , 不加其实也可以. 看起来应该不需要加.
切割的. 不过. 经过测试 , 不加其实也可以. 看起来应该不需要加.
item(0)呢. 当然是返回这个正方形的第一列.(其实也就一个成员. 因为top返回是一个产品.),
这样讲太邪乎. 上图 , 看返回的就是 1205那个. 只是被每个年给打散了.
, 看返回的就是 1205那个. 只是被每个年给打散了.
如上图的测试. 得到 item(0) 返回的是 , 不过. 上面的两个限定(理解为key)是没有意义的, 使用起来只会是value.
, 不过. 上面的两个限定(理解为key)是没有意义的, 使用起来只会是value.
如果需要得到上面的key. 那么 item(0).item(0)得到Road-150 Red, 62, item(0).item(1)得到Internet Sales Amount. 很好玩. 也很深奥. 不过它返回的是一个成员, 记住.
filter过滤. filter和where的不同. where只能进行维度切片. filter因为有表达式true和false的概念, 因此能切到元组上. 比如.

Generate( Set_Expression1 , Set_Expression2 [ , ALL ] ) 将一个集应用于另一个集中的每个成员,然后对得到的集求并集。另外,此函数返回通过用字符串表达式对集求值而创建的串联字符串。
 这是普通的crossjoin的结果. 不能获得所有的集合.
这是普通的crossjoin的结果. 不能获得所有的集合.
详细见http://www.cnblogs.com/downmoon/archive/2011/11/22/2258963.html