【神经网络学习笔记】上证指数开盘指数预测
摘要:
上证指数是反映上海证券交易所挂牌股票总体走势的统计指标。上海证券交易所股票指数的发布几乎是和股市行情的变化相同步的,它是我国股民和证券从业人员研判股票价格变化趋势必不可少的参考依据。本文通过分析1991年至今近6000个交易日的开盘指数,来预测未来5天内的开盘指数变化趋势和变化范围。
一、原理介绍
粒计算:
人类在处理大量复杂信息时.由于人类认知能力有限,往往会把大量复杂信息按其各自特征和性能将其划分为若干较为简单的块.每个被分出来的块就被看成是一个粒。实际上,粒就是指一些个体通过不分明关系、相似关系、邻近关系或功能关系等所形成的块。这种处理信息的过程.称信息粒化。如商场的货物多种多样,如果不按某种方式摆放就很难进行有效管理.于是人们按货架所摆放货物的种类、体积、等级等将商场划分为若干块并以此安排货架,其每一块将摆放同一种类或体积相似或同一等级的货物。这里所说的块就是粒的概念,划分粒的过程称为信息粒。
预测准确的开盘指数并不现实,所以对趋势的预测就尤为重要,利用粒计算可以计算出未来时间段内的最大值、最小值、以及平均值,从而预测股票走势.。
SVM:支持向量机,用于对粒计算的三个指数Low,R,Up(分别代表最小值,平均值,最大值)回归计算。
二、计算流程
1、导入数据,szzs_open<5668*1>
2、用FIG_D函数对数据进行模糊信息粒化,本文采用5个数据为一个“窗”,所以生成的3个矩阵Low,R,Up的大小均为<1*1133>
3、用SVM对粒化数据进行预测。注意粒化后有3个属性,要分别预测。
4、给出上证指数开盘指数的变化趋势和变化范围。
三、代码实现
1、导入数据并可视化
<span style="font-size:12px;">%% 清空环境变量
close all;
clear;
clc;
format compact;
%% 原始数据的提取
% 载入测试数据上证指数(1991.6.9-2014.08.13)
% 数据是一个5668*14的double型的矩阵,每一行表示每一天的上证指数
% 14列分别表示当天上证指数的开盘指数,指数最高值,指数最低值,收盘指数,当日交易量,当日交易额.涨数,跌数,MA1~MA6
load szzs.mat;
% 提取数据
ts = szzs_open;
time = length(ts);
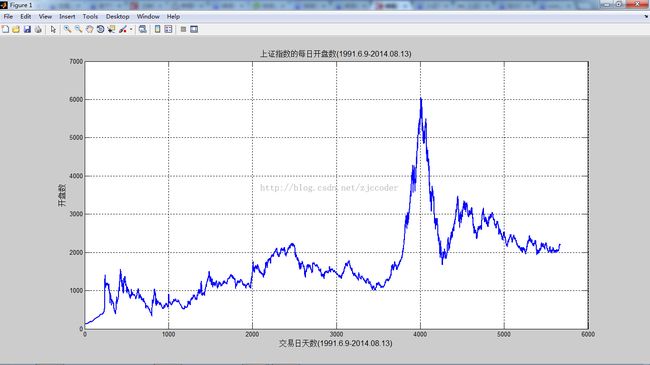
% 画出原始上证指数的每日开盘数
figure;
plot(ts,'LineWidth',2);
title('上证指数的每日开盘数(1991.6.9-2014.08.13)','FontSize',12);
xlabel('交易日天数(1991.6.9-2014.08.13)','FontSize',12);
ylabel('开盘数','FontSize',12);
grid on;
% print -dtiff -r600 original;
snapnow;</span>
%% 对原始数据进行模糊信息粒化 win_num = floor(time/5); tsx = 1:win_num; tsx = tsx'; [Low,R,Up]=FIG_D(ts','triangle',win_num); snapnow;3、数据预处理,将Low归一化
% 数据预处理,将Low进行归一化处理 % mapminmax为matlab自带的映射函数 [low,low_ps] = mapminmax(Low); low_ps.ymin = 100; low_ps.ymax = 500; % 对Low进行归一化 [low,low_ps] = mapminmax(Low,low_ps); % 对low进行转置,以符合libsvm工具箱的数据格式要求 low = low'; snapnow;4、在训练SVM网络之前需要先设置网络参数c和g,此处用交叉验证方法选择,即SVMcgForRegress函数,分两次在给定的空间上搜寻最佳c和g,赋给bestc,bestg。
% 选择回归预测分析中最佳的SVM参数c&g
% 首先进行粗略选择
[bestmse,bestc,bestg] = SVMcgForRegress(low,tsx,-10,10,-10,10,3,1,1,0.1,1);
% 打印粗略选择结果
disp('打印粗略选择结果');
str = sprintf( 'SVM parameters for Low:Best Cross Validation MSE = %g Best c = %g Best g = %g',bestmse,bestc,bestg);
disp(str);
% 根据粗略选择的结果图再进行精细选择
[bestmse,bestc,bestg] = SVMcgForRegress(low,tsx,-4,8,-10,10,3,0.5,0.5,0.05,1);
5、用上面得到的bestc和bestg作为参数,训练SVM网络。
% 训练SVM cmd = ['-c ', num2str(bestc), ' -g ', num2str(bestg) , ' -s 3 -p 0.1']; low_model = svmtrain(low, tsx, cmd);7、预测Low
% 预测low
[low_predict,low_mse,dec_value_low] = svmpredict(low,tsx,low_model);
low_predict = mapminmax('reverse',low_predict,low_ps);
predict_low = svmpredict(1,win_num+1,low_model);
predict_low = mapminmax('reverse',predict_low,low_ps);
predict_low
8、让我们看看误差
figure;
error = low_predict - Low';
plot(error,'ro');
title('误差(predicted data-original data)','FontSize',12);
xlabel('粒化窗口数目','FontSize',12);
ylabel('误差量','FontSize',12);
grid on;

嗯,预测结果还不错,下面按上面的方法把另两个参数R和Up也预测了,我就一并写了。
%% 利用SVM对R进行回归预测
% 数据预处理,将R进行归一化处理
% mapminmax为matlab自带的映射函数
[r,r_ps] = mapminmax(R);
r_ps.ymin = 100;
r_ps.ymax = 500;
% 对R进行归一化
[r,r_ps] = mapminmax(R,r_ps);
% 画出R归一化后的图像
figure;
plot(r,'r*');
title('r归一化后的图像','FontSize',12);
grid on;
% 对R进行转置,以符合libsvm工具箱的数据格式要求
r = r';
% snapnow;
% 选择回归预测分析中最佳的SVM参数c&g
% 首先进行粗略选择
[bestmse,bestc,bestg] = SVMcgForRegress(r,tsx,-10,10,-10,10,3,1,1,0.1);
% 打印粗略选择结果
disp('打印粗略选择结果');
str = sprintf( 'SVM parameters for R:Best Cross Validation MSE = %g Best c = %g Best g = %g',bestmse,bestc,bestg);
disp(str);
% 根据粗略选择的结果图再进行精细选择
[bestmse,bestc,bestg] = SVMcgForRegress(r,tsx,-4,9,-10,10,3,0.5,0.5,0.05);
% 打印精细选择结果
disp('打印精细选择结果');
str = sprintf( 'SVM parameters for R:Best Cross Validation MSE = %g Best c = %g Best g = %g',bestmse,bestc,bestg);
disp(str);
% 训练SVM
cmd = ['-c ', num2str(bestc), ' -g ', num2str(bestg) , ' -s 3 -p 0.1'];
r_model = svmtrain(r, tsx, cmd);
% 预测
[r_predict,r_mse,dec_value2] = svmpredict(r,tsx,r_model);
r_predict = mapminmax('reverse',r_predict,r_ps);
predict_r = svmpredict(1,win_num+1,r_model);
predict_r = mapminmax('reverse',predict_r,r_ps);
predict_r
%% 对于R的回归预测结果分析
figure;
hold on;
plot(R,'b+');
plot(r_predict,'r*');
legend('original r','predict r',2);
title('original vs predict','FontSize',12);
grid on;
figure;
error = r_predict - R';
plot(error,'ro');
title('误差(predicted data-original data)','FontSize',12);
grid on;
% snapnow;
%% 利用SVM对Up进行回归预测
% 数据预处理,将up进行归一化处理
% mapminmax为matlab自带的映射函数
[up,up_ps] = mapminmax(Up);
up_ps.ymin = 100;
up_ps.ymax = 500;
% 对Up进行归一化
[up,up_ps] = mapminmax(Up,up_ps);
% 画出Up归一化后的图像
figure;
plot(up,'gx');
title('Up归一化后的图像','FontSize',12);
grid on;
% 对up进行转置,以符合libsvm工具箱的数据格式要求
up = up';
snapnow;
% 选择回归预测分析中最佳的SVM参数c&g
% 首先进行粗略选择
[bestmse,bestc,bestg] = SVMcgForRegress(up,tsx,-10,10,-10,10,3,1,1,0.5);
% 打印粗略选择结果
disp('打印粗略选择结果');
str = sprintf( 'SVM parameters for Up:Best Cross Validation MSE = %g Best c = %g Best g = %g',bestmse,bestc,bestg);
disp(str);
% 根据粗略选择的结果图再进行精细选择
[bestmse,bestc,bestg] = SVMcgForRegress(up,tsx,-4,9,-10,10,3,0.5,0.5,0.2);
% 打印精细选择结果
disp('打印精细选择结果');
str = sprintf( 'SVM parameters for Up:Best Cross Validation MSE = %g Best c = %g Best g = %g',bestmse,bestc,bestg);
disp(str);
% 训练SVM
cmd = ['-c ', num2str(bestc), ' -g ', num2str(bestg) , ' -s 3 -p 0.1'];
up_model = svmtrain(up, tsx, cmd);
% 预测
[up_predict,up_mse,dec_value3] = svmpredict(up,tsx,up_model);
up_predict = mapminmax('reverse',up_predict,up_ps);
predict_up = svmpredict(1,win_num+1,up_model);
predict_up = mapminmax('reverse',predict_up,up_ps);
predict_up
%% 对于Up的回归预测结果分析
figure;
hold on;
plot(Up,'b+');
plot(up_predict,'r*');
legend('original up','predict up',2);
title('original vs predict','FontSize',12);
grid on;
figure;
error = up_predict - Up';
plot(error,'ro');
title('误差(predicted data-original data)','FontSize',12);
grid on;
9、至此,3个参数已经都预测出来了,分别是predict_low,predict_r,predict_up,command Window已经满了,我们在Workspace分别点开看看这三个数据
predict_low = 2210.6
predict_r = 2257.7
predict_up = 2285.8
也就是说在未来的5天内,上证开盘指数会在2210.6~2285.8范围内。
因为我们的数据有5668个,5668%5 = 3,所以最后三天的数据是没有计算在内的,这个预测是2014-8-11~2014-8-15的预测数据。
四、验证
我们把前5天和后5天的预测数据和实际数据都列出来看看(9,10日为周末,不开盘)
| 日期 | 4 | 5 | 6 | 7 | 8 | 模糊粒子描述 |
| 实际开盘数 | 2190.0 | 2224.6 | 2212.0 | 2216.7 | 2118.7 | [Low,R.Up]=[2179.3,2212.9,2226.8] |
| 日期 | 11 | 12 | 13 | 14 | 15 | 模糊粒子描述 |
| 实际开盘数 | 2199.4 | 2222.7 | 2223.1 | 2221.5 | ? | [Low,R.Up]=[2210.6,2257.7,2285.8] |
1、实际开盘指数都在Low和Up之间,说明范围预测准确。
2、两个时段的R分别是2212.9和2257.7,说明要开盘指数上涨,从已开的数据来看,前后5天相比指数整体是上涨的,预测正确。
五、总结
此种方法在数值上实现了对开盘指数的预测,
但开盘指数会受市场因素,舆论因素,政策因素的影响,此模型未考虑这些因素,以后将加入,使模型更准确。
SVM+粒计算不失为预测的新途径。
(PS:放出8月18~8月22的预测数据,以供检验[Low,R.Up]=[2208.6,2272.0,2316.2] ,看来是牛市哦^_^~)