android之Pull解析XML
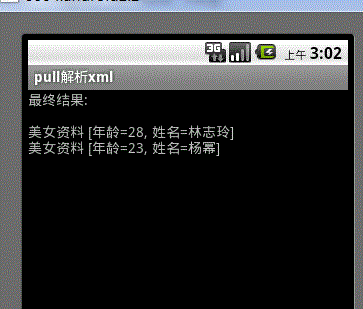
上图为最终效果图。
代码结构示意图:
我们先来看看代码:
main.xml
<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:orientation="vertical" android:layout_width="fill_parent" android:layout_height="fill_parent" > <TextView android:id="@+id/showBeauty" android:layout_width="fill_parent" android:layout_height="wrap_content" /> </LinearLayout>
Activity的代码
package cn.com.pulltest; import java.io.InputStream; import java.util.ArrayList; import org.xmlpull.v1.XmlPullParser; import org.xmlpull.v1.XmlPullParserFactory; import android.app.Activity; import android.os.Bundle; import android.util.Log; import android.widget.TextView; public class PullActivity extends Activity { private String result = ""; private ArrayList<Beauty> beauties = new ArrayList(); @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); try { // 以流的形式获取src目录下的xml文件(此文件的父亲文件夹必须是src) InputStream InputStream = this.getClass().getClassLoader().getResourceAsStream("beauties.xml"); // 获取一个XmlPullParser XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory.newInstance(); XmlPullParser parser = xmlPullParserFactory.newPullParser(); // 设置输入流已经编码方式 parser.setInput(InputStream, "UTF-8"); // 获取当前的事件类型 int eventType = parser.getEventType(); Beauty beauty = null; while(XmlPullParser.END_DOCUMENT!=eventType){ String nodeName = parser.getName(); switch (eventType) { case XmlPullParser.START_TAG: if(nodeName.equals("beauty")){ beauty = new Beauty(); } if(nodeName.equals("name")){ beauty.setName(parser.nextText()); } if(nodeName.equals("age")){ beauty.setAge(parser.nextText()); } break; case XmlPullParser.END_TAG: if(nodeName.equals("beauty")&&beauty!=null){ beauties.add(beauty); } break; default: break; } // 手动的触发下一个事件 eventType = parser.next(); Log.i("PullActivity", eventType+""); } for(Beauty beauty2 : beauties){ result+="/n"+beauty2.toString(); } //result = beauties.size()+""; TextView textView = (TextView) findViewById(R.id.showBeauty); textView.setText("最终结果: /n "+result); } catch (Exception e) { e.printStackTrace(); } } /** * * @author chenzheng * 这里使用内部类是为了效率考虑,内部类要比单独顶一个bean类更加的高效以及节约空间 * */ private class Beauty{ String name; String age; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAge() { return age; } public void setAge(String age) { this.age = age; } @Override public String toString() { return "美女资料 [年龄=" + age + ", 姓名=" + name + "]"; } } }
beauties.xml
<?xml version="1.0" encoding="UTF-8"?> <beauties> <beauty> <name>林志玲</name> <age>28</age> </beauty> <beauty> <name>杨幂</name> <age>23</age> </beauty> </beauties>
这里的book.xml没有用到。
AndroidManifest.xml使用的是默认的。
运行,我们就可以看到了刚开始的那种结果了。
----------------------------------------------------------------------------------------
这里对xml进行解析时,需要注意的是,beauties.xml的位置,我们这里多添加了一个book.xml也是为了让大家明白,xml文件的确切位置应该是在src下,而不是src下的子文件夹下。
----------------------------------------------------------------------------------------
一般,我们使用java解析xml,主要还是有两种方式,一种方式是SAX解析,另一种是DOM解析。当然还有一系列的其他第三方解析API,如JDOM/DOM4J.他们各自有各自的优缺点。这里我们主要分析下最基础的两种解析方式,sax解析和dom解析。
两者依赖的解析机制是完全不同的。sax解析,依赖于事件触发机制,你可以认为我们在读取xml的时候,每遇到一个xml内容都会触发相应的事件,我们一行行的往下读,事件也自动的一个个的往下触发,一直到最终结束。代码中,我们则需要实现一个defaultHandler,来定义当xml读到什么内容时,进行什么样子的操作。sax解析,只能从文档头一直读到尾,中间不能停止也不能对文件进行修改。直到解析完了整个文档才会返回。
dom解析,则是通过在内存中形成一个节点树来完成xml解析,它虽然可以快速的定位xml中的某个位置,并且可以对其进行修改操作,但是它对内存的要求比较大。特别是当xml文件比较大的时候,这个缺点就更严重了。对于手机来说,这很致命。
SAX方式的特点是需要解析完整个文档才会返回,如果在一个XML文档中我们只需要前面一部分数据,但是使用SAX方式还是会对整个文档进行解析,尽管XML文档中后面的大部分数据我们其实都不需要解析,因此这样实际上就浪费了处理资源。
为了解决点这种缺陷,Android利用另一种更加高效方便的xml解析方式对xml文件进行解析,这就是Pull解析。
Pull解析器和SAX解析器虽有区别但也有相似性。他们的区别为:SAX解析器的工作方式是自动将事件推入注册的事件处理器进行处理,因此你不能控制事件的处理主动结束;而Pull解析器的工作方式允许你在应用程序代码中主动从解析器中获取事件,正因为是主动获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析。
OPhone/Android系统中和Pull方式相关的包为org.xmlpull.v1,在这个包中提供了Pull解析器的工厂类XmlPullParserFactory和Pull解析器XmlPullParser,XmlPullParserFactory实例调用newPullParser方法创建XmlPullParser解析器实例,接着XmlPullParser实例就可以调用getEventType()和next()等方法依次主动提取事件,并根据提取的事件类型进行相应的逻辑处理。
代码如下
// 以流的形式获取src目录下的xml文件(此文件的父亲文件夹必须是src) InputStream InputStream = this.getClass().getClassLoader().getResourceAsStream("beauties.xml"); // 获取一个XmlPullParser XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory.newInstance(); XmlPullParser parser = xmlPullParserFactory.newPullParser(); // 设置输入流已经编码方式 parser.setInput(InputStream, "UTF-8");
我们然后就可以通过XmlPullParser里面提供的方法进行解析了,这里列出几个重要的方法说明
//在xml读取的开始调用,并触发读取文件时的第一个事件,返回的是事件的标示
public int getEventType() throws XmlPullParserException ;
//遍历下一个事件,返回一个事件的类型
public int next() throws XmlPullParserException, IOException
//得到当前Tag名字
public String getName();
//获取文本
public String getText();
//得到当前Tag下面的属性数量
public int getAttributeCount() ;
//得到当前Tag下面指定位置的属性名称
public String getAttributeName(int index);
//得到当前Tag下面指定位置的属性植
public String getAttributeValue(int index);
//如果当前事件是一个start_tag并且下一个元素就是文本的话,那么就将这个文本内容返回;如果下一个元素直接就是end_tag的话,那么久返回空字符串;其他情况返回异常。
public String getNextText();
-------------------------------------------------------------------------
我们总结下pull解析的代码步骤:
第一步:我们需要先定义一个xml文件(当然也可以是从网络上获取的xml文件)
第二步:创建一个XmlPullParser对象,用于对文件进行解析
第三步:通过parser.setInput()方法,将文件和文件解析器关联起来。
第四步:调用getEventType();方法正式开始解析。
第五步:在while循环中处理xml