volley源码解析(三)--Volley核心之RequestQueue类
上一篇文章给大家说明了Request<T>的内部结构,对于这个类而言,volley让我们关注的主要请求获得响应以后,怎么根据自己的需要解析响应,然后在主线程中回调监听器的方法,至于是怎么获得响应的,线程又是怎么开启的,都跟Request无关。
前面已经提到,Request会放在队列里面等待线程的提取,RequestQueue类作为volley的核心类,可以说是连接请求与响应的桥梁。另外,RequestQueue类作为一个集合,还给我们统一管理请求带来更大的方便,这样的思想是很值得我们学习的。
android设计上,也有使用队列这种形式的设计,一个比较典型的例子,就是handler,loop,message的实现。具体大家可以参考这篇文章blog.csdn.net/crazy__chen/article/details/44889479
下面从源码角度看RequestQueue类,首先当然是属性
/**
* A request dispatch queue with a thread pool of dispatchers.
*
* Calling {@link #add(Request)} will enqueue the given Request for dispatch,
* resolving from either cache or network on a worker thread, and then delivering
* a parsed response on the main thread.
* 一个拥有线程池的请求队列
* 调用add()分发,将添加一个用于分发的请求
* worker线程从缓存或网络获取响应,然后将该响应提供给主线程
*/
public class RequestQueue {
/**
* Callback interface for completed requests.
* 任务完成的回调接口
*/
public static interface RequestFinishedListener<T> {
/** Called when a request has finished processing. */
public void onRequestFinished(Request<T> request);
}
/**
* Used for generating monotonically-increasing sequence numbers for requests.
* 使用原子类,记录队列中当前的请求数目
*/
private AtomicInteger mSequenceGenerator = new AtomicInteger();
/**
* Staging area for requests that already have a duplicate request in flight.<br>
* 等候缓存队列,重复请求集结map,每个queue里面都是相同的请求
* <ul>
* <li>containsKey(cacheKey) indicates that there is a request in flight for the given cache
* key.</li>
* <li>get(cacheKey) returns waiting requests for the given cache key. The in flight request
* is <em>not</em> contained in that list. Is null if no requests are staged.</li>
* </ul>
* 如果map里面包含该请求的cachekey,说明已经有相同key的请求在执行
* get(cacheKey)根据cachekey返回对应的请求
*/
private final Map<String, Queue<Request<?>>> mWaitingRequests =
new HashMap<String, Queue<Request<?>>>();
/**
* The set of all requests currently being processed by this RequestQueue. A Request
* will be in this set if it is waiting in any queue or currently being processed by
* any dispatcher.
* 队列当前拥有的所以请求的集合
* 请求在队列中,或者正被调度,都会在这个集合中
*/
private final Set<Request<?>> mCurrentRequests = new HashSet<Request<?>>();
/**
* The cache triage queue.
* 缓存队列
*/
private final PriorityBlockingQueue<Request<?>> mCacheQueue =
new PriorityBlockingQueue<Request<?>>();
/**
* The queue of requests that are actually going out to the network.
* 网络队列,有阻塞和fifo功能
*/
private final PriorityBlockingQueue<Request<?>> mNetworkQueue =
new PriorityBlockingQueue<Request<?>>();
/**
* Number of network request dispatcher threads to start.
* 默认用于调度的线程池数目
*/
private static final int DEFAULT_NETWORK_THREAD_POOL_SIZE = 4;
/**
* Cache interface for retrieving and storing responses.
* 缓存
*/
private final Cache mCache;
/**
* Network interface for performing requests.
* 执行请求的网络
*/
private final Network mNetwork;
/** Response delivery mechanism. */
private final ResponseDelivery mDelivery;
/**
* The network dispatchers.
* 该队列的所有网络调度器
*/
private NetworkDispatcher[] mDispatchers;
/**
* The cache dispatcher.
* 缓存调度器
*/
private CacheDispatcher mCacheDispatcher;
/**
* 任务完成监听器队列
*/
private List<RequestFinishedListener> mFinishedListeners =
new ArrayList<RequestFinishedListener>();
属性很多,而且耦合的类也比较多,我挑重要的讲,这里大家只要先记住某个属性是什么就可以,至于它的具体实现我们先不管
1,首先看List<RequestFinishedListener> mFinishedListeners任务完成监听器队列,这个队列保留了很多监听器,这些监听器都是监听RequestQueue请求队列的,而不是监听单独的某个请求。RequestQueue中每个请求完成后,都会回调这个监听队列里面的所有监听器。这是RequestQueue的统一管理的体现。
2,AtomicInteger mSequenceGenerator原子类,对java多线程熟悉的朋友应该知道,这个是为了线程安全而创造的类,不了解的朋友,可以把它认识是int类型,用于记录当前队列中的请求数目
3,PriorityBlockingQueue<Request<?>> mCacheQueue缓存队列,用于存放向请求缓存的request,线程安全,有阻塞功能,也就是说当队列里面没有东西的时候,线程试图从队列取请求,这个线程就会阻塞
4,PriorityBlockingQueue<Request<?>> mNetworkQueue网络队列,用于存放准备发起网络请求的request,功能同上
5,CacheDispatcher mCacheDispatcher缓存调度器,继承了Thread类,本质是一个线程,这个线程将会被开启进入一个死循环,不断从mCacheQueue缓存队列取出请求,然后去缓存Cache中查找结果
6,NetworkDispatcher[] mDispatchers网络调度器数组,继承了Thread类,本质是多个线程,所以线程都将被开启进入死循环,不断从mNetworkQueue网络队列取出请求,然后去网络Network请求数据
7,Set<Request<?>> mCurrentRequests记录队列中的所有请求,也就是上面mCacheQueue缓存队列与mNetworkQueue网络队列的总和,用于统一管理
8,Cache mCache缓存对象,面向对象的思想,把缓存看成一个实体
9,Network mNetwork网络对象,面向对象的思想,把网络看成一个实体
10,ResponseDelivery mDelivery分发器,就是这个分发器,负责把响应发给对应的请求,分发器存在的意义之前已经提到了,主要是为了耦合更加送并且能在主线程中操作UI
11,Map<String, Queue<Request<?>>> mWaitingRequests等候缓存队列,重复请求集结map,每个queue里面都是相同的请求。为什么需要这个map呢?map的key其实是request的url,如果我们有多个请求的url都是相同的,也就是说请求的资源是相同的,volley就把这些请求放入一个队列,在用url做key将队列放入map中。
因为这些请求都是相同的,可以说结果也是相同的。那么我们只要获得一个请求的结果,其他相同的请求,从缓存中取就可以了。
所以等候缓存队列的作用就是,当其中的一个request获得响应,我们就将这个队列放入缓存队列mCacheQueue中,让这些request去缓存获取结果就好了。
这是volley处理重复请求的思路。
其实看懂上面的属性就可以了解RequestQueue类的作用,大家结合上面的属性,看一下流程图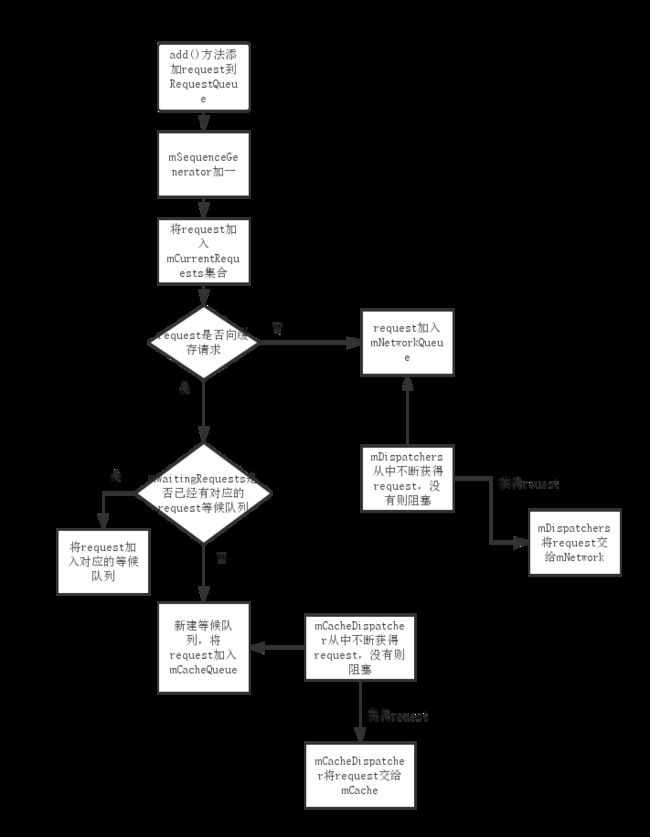
ok,我们还是从构造函数开始看起吧
/**
* Creates the worker pool. Processing will not begin until {@link #start()} is called.
* 创建一个工作池,在调用start()方法以后,开始执行
* @param cache A Cache to use for persisting responses to disk
* @param network A Network interface for performing HTTP requests
* @param threadPoolSize Number of network dispatcher threads to create
* @param delivery A ResponseDelivery interface for posting responses and errors
*/
public RequestQueue(Cache cache, Network network, int threadPoolSize,
ResponseDelivery delivery) {
mCache = cache;//缓存,用于保留响应到硬盘
mNetwork = network;//网络接口,用于执行http请求
mDispatchers = new NetworkDispatcher[threadPoolSize];//根据线程池大小,创建调度器数组
mDelivery = delivery;//一个分发接口,用于响应和错误
}
/**
* Creates the worker pool. Processing will not begin until {@link #start()} is called.
*
* @param cache A Cache to use for persisting responses to disk
* @param network A Network interface for performing HTTP requests
* @param threadPoolSize Number of network dispatcher threads to create
*/
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}对于RequestQueue来说,必须有的参数是缓存,网络,分发器,网络线程的数目
对应上面的属性可以知道,原来这些东西都是外部传进来的,参照本专栏的开篇,可以知道,是在Volley这个类里面传进来的,同时在外部,我们也是通过Volley.newRequestQueue()方法来创建并且开启queue队列的。
紧接着来看start()方法,这个方法用于启动队列
/**
* Starts the dispatchers in this queue.
*/
public void start() {
stop(); //保证当前所有运行的分发停止 Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
//创建新的缓存调度器,并且启动它
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// Create network dispatchers (and corresponding threads) up to the pool size.
//创建网络调度器,并且启动它们
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
可以看到,所谓启动队列,就是创建了CacheDispatcher缓存调度器,和mDispatchers[]网络调度器数组,根据前面的介绍我们知道,它们都是线程,所以start()方法里面,其实就是调用了它们的start()方法。也就是说RequestQueue启动的本质,是这些调度器的启动,这些调度器启动以后,会进入死循环,不断从队列中取出request来进行数据请求。
由于Dispatcher调度器的数目有限(是根据我们给构造方法传入的参数threadPoolSize决定的),意味着Volley框架,同时在执行数据请求的线程数目是有限的,这样避免了重复创建线程所带来的开销,同时可能会带来效率的下降。
所以threadPoolSize对不同的应用,设置的大小大家不同,大家要根据自己项目实际情况,经过测试来确定这个值。
说完开启,我们再来看RequestQueue的关闭
/**
* Stops the cache and network dispatchers.
* 停止调度器(包括缓存和网络)
*/
public void stop() {
if (mCacheDispatcher != null) {
mCacheDispatcher.quit();
}
for (int i = 0; i < mDispatchers.length; i++) {
if (mDispatchers[i] != null) {
mDispatchers[i].quit();
}
}
}对比开启,其实stop()的本质也是关闭所有的调度器,调用了它们的quit()方法,至于这个方法做的是什么,很容易想到,是把它们内部while循环的标志设成false
再来看add()方法,这方法用于将request加入队列,也是一个非常重要方法
/**
* Adds a Request to the dispatch queue.
* @param request The request to service
* @return The passed-in request
* 向请求队列添加请求
*/
public <T> Request<T> add(Request<T> request) {
// Tag the request as belonging to this queue and add it to the set of current requests.
request.setRequestQueue(this);//为请求设置其请求队列
synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
}
// Process requests in the order they are added.
request.setSequence(getSequenceNumber());//设置请求序号
request.addMarker("add-to-queue");
// If the request is uncacheable, skip the cache queue and go straight to the network.
//如果该请求不缓存,添加到网络队列
if (!request.shouldCache()) {
mNetworkQueue.add(request);
return request;
}
//如果该请求要求缓存
// Insert request into stage if there's already a request with the same cache key in flight.
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
if (mWaitingRequests.containsKey(cacheKey)) {
// There is already a request in flight. Queue up.
//如果已经有一个请求在工作,则排队等候
Queue<Request<?>> stagedRequests = mWaitingRequests.get(cacheKey);
if (stagedRequests == null) {
stagedRequests = new LinkedList<Request<?>>();
}
stagedRequests.add(request);
mWaitingRequests.put(cacheKey, stagedRequests);
if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);
}
} else {
// Insert 'null' queue for this cacheKey, indicating there is now a request in
// flight.
//为该key插入null,表明现在有一个请求在工作
mWaitingRequests.put(cacheKey, null);
mCacheQueue.add(request);
}
return request;
}
}对于一个request而言,首先它会被加入mCurrentRequests,这是用于request的统一管理
然后,调用shouldCache()判断是从缓存中取还是网络请求,如果是网络请求,则加入mNetworkQueue,然后改方法返回
如果请求缓存,根据mWaitingRequests是否已经有相同的请求在进行,如果是,则将该request加入mWaitingRequests
如果不是,则将request加入mCacheQueue去进行缓存查询
到目前为止,我们知道了调度器会从队列里面拿请求,至于具体是怎么请求的,我们还不清楚。这也体现了volley设计的合理性,通过组合来分配各个职责,每个类的职责都比较单一。
我们提到,RequestQueue的一个重要作用,就是对request的统一管理,其实所谓的管理,更多是对request的关闭,下面我来看一下这些方法
/**
* Called from {@link Request#finish(String)}, indicating that processing of the given request
* has finished.
* 在request类的finish()方法里面,会调用这个方法,说明该请求结束
* <p>Releases waiting requests for <code>request.getCacheKey()</code> if
* <code>request.shouldCache()</code>.</p>
*/
public <T> void finish(Request<T> request) {
// Remove from the set of requests currently being processed.
synchronized (mCurrentRequests) {//从当前请求队列中移除
mCurrentRequests.remove(request);
}
synchronized (mFinishedListeners) {//回调监听器
for (RequestFinishedListener<T> listener : mFinishedListeners) {
listener.onRequestFinished(request);
}
}
if (request.shouldCache()) {//如果该请求要被缓存
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
Queue<Request<?>> waitingRequests = mWaitingRequests.remove(cacheKey);//移除该缓存
if (waitingRequests != null) {//如果存在缓存等候队列
if (VolleyLog.DEBUG) {
VolleyLog.v("Releasing %d waiting requests for cacheKey=%s.",
waitingRequests.size(), cacheKey);
}
// Process all queued up requests. They won't be considered as in flight, but
// that's not a problem as the cache has been primed by 'request'.
// 处理所有队列中的请求
mCacheQueue.addAll(waitingRequests);//
}
}
}
}
finish()用于表示某个特定的request完成了,只有将要完成的request传进来就好了,然后会在各个队列中移除它
这里需要注意,一个request完成以后,会将waitingRequests里面所有相同的请求,都加入到mCacheQueue缓存队列中,这就意味着,这些请求从缓存中取出结果就好了,这样就避免了频繁相同网络请求的开销。这也是Volley的亮点之一。
然后我们再来看一些取消方法
/**
* A simple predicate or filter interface for Requests, for use by
* {@link RequestQueue#cancelAll(RequestFilter)}.
* 一个简单的过滤接口,在cancelAll()方法里面被使用
*/
public interface RequestFilter {
public boolean apply(Request<?> request);
}
/**
* Cancels all requests in this queue for which the given filter applies.
* @param filter The filtering function to use
* 根据过滤器规则,取消相应请求
*/
public void cancelAll(RequestFilter filter) {
synchronized (mCurrentRequests) {
for (Request<?> request : mCurrentRequests) {
if (filter.apply(request)) {
request.cancel();
}
}
}
}
/**
* Cancels all requests in this queue with the given tag. Tag must be non-null
* and equality is by identity.
* 根据标记取消相应请求
*/
public void cancelAll(final Object tag) {
if (tag == null) {
throw new IllegalArgumentException("Cannot cancelAll with a null tag");
}
cancelAll(new RequestFilter() {
@Override
public boolean apply(Request<?> request) {
return request.getTag() == tag;
}
});
}
上面的设计可以说是非常巧妙的,为了增加取消的灵活性,创建了一个RequestFilter来自定义取消request的规则
在cancelAll(RequestFilter filter)方法里面,我们传入过滤器,就可以根据需要取消我想要取消的一类request,这种形式类似文件遍历的FileFilter
而这种形式,volley还为我们提供了一个具体的实现cancelAll(final Object tag),来根据标签取消request,这里我们也就明白了request<T>类中mTag属性的用处了
可以说volley处处都体现了设计模式的美感。
Ok,RequestQueue介绍到这里,就介绍了整个的基本结构,剩下的困惑,是CacheDispatcher,networkDispatcher怎么从队列里面取出request的问题了,但是这些问题跟队列的关系没有那么紧,也就是说具体实现的任务,又交到了这两个类的身上,总而言之,这里也体现了单一责任原则。
接下来的文章,将会分类讲述这两个功能的实现。