程序员修炼之路-(4)搜索(中):二叉查找树
2 查找:鱼与熊掌
前面已经介绍了线程查找和二分查找的符号表(symbol table)实现,但现代应用的特点是查找与插入或删除操作交叉在一起,无法预测,并且表非常巨大。因此问题的关键就是我们能否设计出具有对数性能的search和insert/delete操作的数据结构和算法?为了实现高效的插入,我们需要链表结构。但是单链表却又阻止了二分查找的使用,因为二分查找依赖数组的快速访问才能快速定位到每次迭代的中间元素。”为了结合二分查找的高效和链表结构的灵活性,我们需要更加复杂的数据结构,这就是接下来要介绍的二叉查找树和哈希表。这种能够快速search和insert/delete的符号表是算法最重要的贡献之一!”
《算法》中的这一段描述打通了我关于二分查找、链表以及二叉树的理解,三种广泛使用的数据结构和算法之间的关系一下子变得豁然开朗,二分查找的思想无处不在!经典就是经典,简短一段话就已值回整本书钱。也许这也是为什么《编程珠玑》中花了大量篇幅讲解二分查找。下面就是查找功能各种实现的优缺点(pros & cons):

2.1 二叉查找树(BST):二者兼得
2.1.1 查找和插入
二叉查找树的查找和插入过程非常相似,因为插入过程其实就是先进行查找,然后在无法找到时停止查找的那个位置执行插入。

2.1.2 代码实现
下面是树结点TreeNode和BST的定义,使用C++模板泛化Key和Value的类型,核心方法就是find()和put()。

如前所述,find()和put()实现很像,都是利用DFS遍历。首先来看put()方法的实现。如果要插入的结点之前存在则直接更新,否则会遍历到插入位置,此时要将父结点的left或right指针指向一个新建结点,所以需要二级指针才能做到。

在Java这种没有指针的语言中,只能采取另一种解决方案,将新建结点返回。如下,《算法》中提供的实现:

相比之下,find()就很简单了,因为不涉及到要新建结点,所以直接用一级指针遍历树就行了。

2.1.3 遍历
二叉树有三种遍历方式:前序遍历(pre-order), 中序遍历(in-order),后序遍历 (post-order)。要牢记的是所谓的“前中后”指的是:当前结点是在两个子结点之前、之间、之后进行处理。例如,如果对当前结点的处理只是打印的话,三种遍历方式就会产生三种经典的表达式:前缀表达式(不常用)、中缀表达式(我们最熟悉的写法)、后缀表达式(又叫逆波兰表达式,编译器和LISP语言中都采用这种写法)。
2.1.4 缺陷
如果key插入类似于随机模型,二叉查找树简洁的实现就能够提供快速的search和insert,以及rank、select、delete和范围查找等。但现实中,worst-case不是不可能发生,例如客户端完全顺序或逆序插入key。这时算法的性能将退化为N,变成线性查找,所以这种可能性也是我们寻找更好算法和数据结构的原因。
2.2 平衡二叉查找树(AVL)
AVL是一种很古老的BST,大学数据结构课学的就是它,当时快被各种旋转搞吐了,今天再看也还是有些晕。它并不严格要求树必须完全保持平衡(perfectly balanced),而是放松了平衡的条件,即a)任意结点的左右子树高度至多差1就行,同时靠b)旋转(rotation)保持树的平衡。这两点也是决定一颗树是否是AVL树的关键特点,否则从结构上来说,它与后面讲到的红黑树都是平衡二叉树,也都是自调整的(self-adjust)。
2.2.1 Rebalance
旋转的关键在于先确定失去平衡的根结点,再确定是哪种类型:左旋L,右旋R,左右旋LR,右左旋RL。前两种情况比较直观,后两种比较复杂。

2.2.2 缺陷
因为AVL对左右子树高度差的严格要求,所以能保证很好的lookup性能。但插入时要进行log(n)旋转,所以对于频繁修改树结构的应用场景来说,AVL的插入性能会成为瓶颈。但对于很少修改但大量查询的应用,AVL树是个不错的选择。所以能够看出,任何数据结构都是有其应用场景的,有其擅长和不擅长,不能一概而论!
2.3 平衡2-3查找树
所谓平衡2-3查找树,就是将标准BST的包含两条链接和一个key的结点(2-node)扩展为可以至多拥有三条链接和两个key(3-node)。而让查找树保持平衡的关键就在于:允许每个结点包含多于一个key,于是将新插入的结点灵活地保存到已有结点中,从而不破坏树的平衡。
2.3.1 Rebalance
新插入一个结点时,有三种情况,其中头两种情况比较简单:
Ø 插入位置能够容纳:这种情况最简单,直接将新插入结点与插入位置的结点放在一起产生一个3-node就行了。(见下面图示)
Ø 不能容纳,但父结点是2-node:这种情况因为父结点可以再容纳一个key所以比较简单。具体过程是提升-分离:1)先产生一个临时4-node,2)然后将中间key提到父结点,3)再将剩余两个key分离成两个结点。

Ø 不能容纳,但父结点是3-node:这种情况相对复杂,4)要不断执行上面的提升-分离过程,直到某个父结点可以容纳下key。如果前面的提升过程一直到根节点都没有遇到2-node,那么就会导致根结点变成一个临时4-node,只能分离根结点才能让树保持平衡了。5)如果一直到根结点都是3-node,最后就需要分离根结点,才能保持2-3树的性质:

2.3.2 完整例子
现在来看一个完整的例子,在一个不断的插入过程看一下上面三种情况是如何处理的:

2.3.3 性能分析
平衡2-3查找树的高度应该介于![]() 之间,即树结点都是3-node或者树结点都是2-node。所以查找和插入操作都应该至多访问lgN个结点。此外,平衡2-3查找树的另一个特点是自底向上“生长”,而不像其他BST那样自上而下。
之间,即树结点都是3-node或者树结点都是2-node。所以查找和插入操作都应该至多访问lgN个结点。此外,平衡2-3查找树的另一个特点是自底向上“生长”,而不像其他BST那样自上而下。
2.3.4 红黑树
前面讲到的2-3树插入算法不难理解,也不难实现,红黑树就是一种的简单的表示,不用多少代码就能完成。然后理解代码是为什么又是怎样实现前面2-3树平衡的是需要仔细研究领悟的。红黑树背后的基本思想是:用一些额外信息将标准BST编码成2-3树。将连接分为两种类型:用红线连接两个结点代表2-node,用黑线连接成2-3树,红色链接必须在左侧。所谓红色结点可以理解为父结点与它之间的链接是红色。之前BST的查找方法不需要修改就可以直接使用。这种实现红黑树的方式是《算法》作者Sedgewick与2008年提出的一种简化版本(难怪看起来比其他算法书的实现要简单呢),叫做LLRB左倾红黑树。详见维基百科上的红黑树历史:
“In 2008, Sedgewick introduced a simpler version of the red–black tree called the left-leaning red–black tree[7] by eliminating a previously unspecified degree of freedom in the implementation. The LLRB maintains an additional invariant that all red links must lean left except during inserts and deletes.”

首先确定一个前提:新插入结点一定是红色的,因为新插入结点总是会与之前结点组成3-node或临时4-node。现在让我们来一边对比2-3树的调整方法,一边学习红黑树是如何实现的:
Ø 插入位置能够容纳:最简单的情况。不需要分离结点,但是因为新插入结点都是红色,如果插入位置是右孩子,要左旋转结点,保持红色link都在左孩子一侧的红黑树性质。

Ø 不能容纳,但父结点是2-node:首先通过至多两次rotate调整结点顺序,然后通过flip分离4-node并提升中间key。注意,前面提到的第一种情况其实就是这三种情况中的第一种leftRotate。

Ø 不能容纳,但父结点是3-node:同2-3树规则一样,不断地执行上面的过程,直到能够容纳。如果一直到根结点都不能,就分离根结点。
2.3.5 红黑树C++实现
树结点表示
比BST实现多了一个color成员变量,默认构造时会初始化为RED。因为前面提到了,所有新插入结点都是RED:

Rotate和Flip
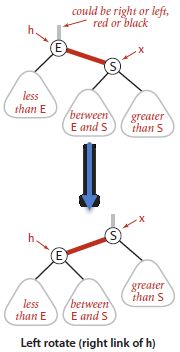
旋转实际上影响的主要是根结点h,左/右孩子x,中间结点x->right/left。

但是旋转后,一定要将x置为h颜色,h置为RED。如下图,这样做的原因很自然,就是使E和S之间是RED链接,同时保持之前E与父结点之间的链接颜色。
插入
前面提到的三种case都在代码中有所体现,首先//1.Locate部分递归定位到插入点,然后//2.Rebalance部分进行三种子情况的后处理,对应了“插入位置能够容纳”和“不能容纳,但父结点是2-node”的case。当处理完成返回时,会递归地处理路径上的所有父结点,包括根,并且最终会将根置为BLACK,不管是否分离了根,这对应“不能容纳,但父结点是3-node”的case。

实现时要注意的细节问题还不少:
1) root未初始化,导致put()中的if判断失效(C++令人崩溃,像Java那样自动初始化成员变量的话能节省我很多调试时间)。
2) isRed()不能放到RBTreeNode中实现,因为当子结点为NULL时也认为它是BLACK,也会触发旋转。
3) rotate()中,使用返回值返回新插入或者旋转后的新根结点,避免使用二级指针。
简单测试
测试一下最极端的情况,即顺序插入一组key。控制台输出的上半部分是BST的,可以看到二叉树退化为链表,而下半部分是RBT红黑树的。

附一:B树家族
具体请参见我的《高性能MySQL》读书笔记。
附二:二叉树的其他用途
除了搜索查找,二叉树在编译领域有着非常重要的作用,那就是表达式树!