WebKit内核源代码分析(五)
红心地瓜([email protected])
摘要:本文分析WebKit中html的解析过程,DOM节点树的建立。
关键词:WebKit,html解析,html tree construction,WebCore,
DOM节点树,dlmu2001
1. HTML解析模型

图1 HTML解析模型图
上图是HTML解析模型图,HTML解析分成Tokeniser和Tree Construction两个步骤,在”WebKit中的html词法分析”
(http://blog.csdn.net/dlmu2001/archive/2010/11/09/5998130.aspx)一文中,我们已经对Tokeniser这一步进行了分析,本文的目标是Tree Construction这一步。
Tree Construction输入是token流,输出是DOM节点树。
2. DOM树
HTML DOM定义了一套标准来将html文档结构化,它定义了表示和修改文档所需的对象、这些对象的行为和属性以及对象之间的关系,可以把它理解为页面上数据和结构的一个树形表示。
Node是DOM模型中的基础类,它可以分成13类(见NodeType),在HTML解析中,最常见的是Document,Element,Text三类。
l Document是文档树的根节点,在HTML文档中,他派生为HTMLDocument。
l 在文档中,所有的标签转化为Element类,一般它有标签名,并根据标签名继承为特定的子类。
l Element之间的原始文本转化成Text类。
以一个简单的html页面为例:
<html>
<head>
<title>test</title>
</head>
<body>
<h1>hl1</h1>
<h2>hl2</h2>
<h3>hl3</h3>
</body>
</html>
经过解析后的节点树如下(忽略换行符):
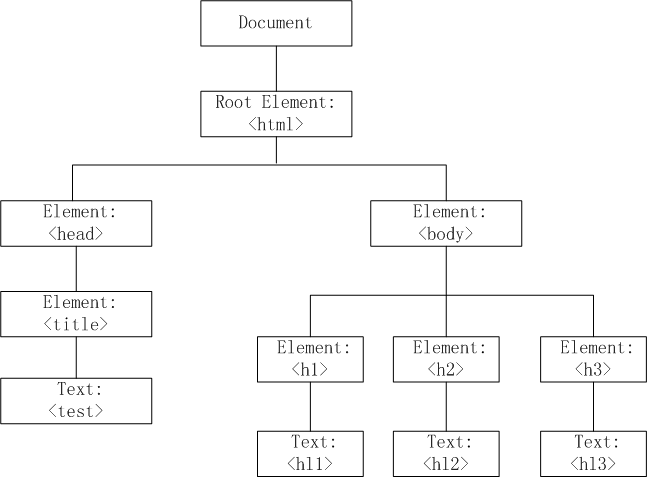
图2 HTML DOM节点树示例
如果没有忽略换行符,则每个换行符就是一个Value为”\n”的Text节点。
3. Tree Construction原理
将图二中的节点树以WebKit中的类具体化(同样忽略换行符)。

图3 Webkit HTML DOM节点树示例
看到这里,你是不是觉得仿佛看到了一个呼之欲出的Tree Construction轮廓?是的,最简化的情况就是这样,根据输入的token,创建出相应的Element派生类,然后添加到DOM树中合适的位置,这就是Tree Construction干的事情。当然,添加到合适的位置,这个需要一系列复杂的规则,另外,WebKit将Render树的创建也放到了Tree Construction阶段中来,再加上CSS,Javascript,所以,这就是你看到的复杂的代码。
放出两个函数原型,热热身,培养培养感情。
PassRefPtr<Element> HTMLConstructionSite::createHTMLElement(AtomicHTMLToken& token);
void HTMLConstructionSite::insertHTMLElement(AtomicHTMLToken& token);
Tree Construction流程由一个状态“Insertion Mode”进行控制,它影响token的处理以及是否支持CDATA部分,HTML5中给出了详细的规则(http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html#the-insertion-mode)。它也控制了在特定状态下能够处理的token,比如在head里面,再出现head标签,显然是不应该处理的。
4. 开放元素堆栈
为了维护即将解析的标签同已解析的标签之间的关系(此时即将解析的标签还没有加入到DOM树中),引入了开放元素堆栈m_openElements,初始状态下,这个堆栈是空的,它是向下增长的,所以最上面的节点是最早加入到堆栈中的,在html文档中,最上面的节点就是html元素,最底部的节点就是最新加入到堆栈中的。Tree Builder的时候,每碰到一个StartTag的token,就会往m_opnElements中压栈,碰到EndTag的token,则出栈。像Character这样的token,则不需要进行压栈出栈的动作,只有可以包含子节点的tag,才做压栈出栈的动作。Html5的文档中对开放元素堆栈也有说明,http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html#the-stack-of-open-elements。
对于正在解析的token,除了根节点html,它必然是堆栈底部元素(m_openElements.top())的子节点,所以在形成DOM树的时候,就可以通过ContainerNode::parserAddChild这样的接口加入到DOM节点树中。
除了正常的堆栈和压栈,对于html,head,body元素,栈结构(HTMLElementStack)中有专门的成员m_htmlElement,m_headElement,m_bodyElement记录,主要是用于检错纠错处理。
在本文的html范例中,当解析到<h2>hl2</h2>的hl2这个character的token的时候,它的开放元素堆栈如下,HTMLHeadingElement是堆栈的top,所以它是hl2这个Text节点的parent。

图4 开放元素堆栈示例
此时的DOM节点树如下:
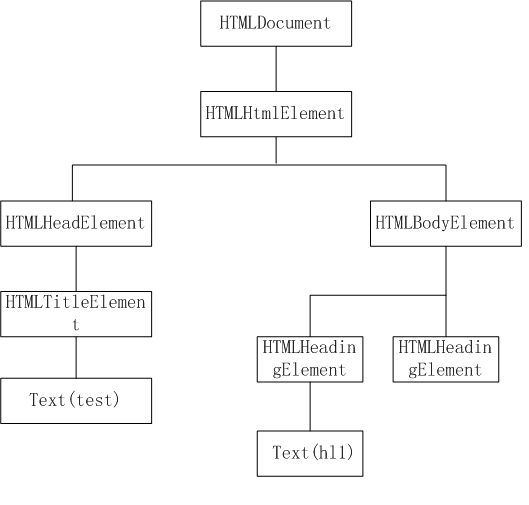
图5 Webkit DOM节点数示例
5. 元素的创建
HTMLElementFactory类提供了元素的创建方法createHTMLElement。传入为对应的标签名,所属的document,所属的form(如果属于form),在parser的时候,最后一个参数为true。
PassRefPtr<HTMLElement> HTMLElementFactory::createHTMLElement(const QualifiedName& qName, Document* document, HTMLFormElement* formElement, bool createdByParser);
在HTMLElementFactory中,通过一个Hash Map将tag name和对应的元素构造函数对应起来(gFunctionMap)。tag一般对应一个派生于HTMLElement的类。如下是HTMLHeadingElement的类层次结构图。
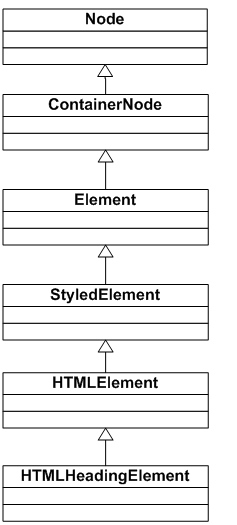
图6 HTMLHeadingElement类层次图
6. 其它
HTMLConstructionSite::attach中的attach一词,地瓜理解主要是attach到DOM节点数上,当然,它同时调用了Element::attach,Element类的attach主要是attach到Render树上,它会创建对应该Element的RendrObject。
除了m_openElements,HTMLConstructionSite同时维护了Format 元素列表m_activeFormattingElements,Formating元素就是那些格式化标签,包括a,b,big,code,em,font,I,fot,I,nobr,s,small,strike,strong,tt,u。为了处理这些Formatting元素的嵌套关系(此时它们可能不是父子关系,而是平级,不加入到m_openElements),HTML5引入了这个列表(http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html#list-of-active-formatting-elements)。
使用gdb调试的童子,可以运行Tools/gdb/webkit.py脚本,在print结构体的时候得到易于理解的表示,还可以打印出节点树,具体参考http://trac.webkit.org/wiki/GDB。