机器学习(十四)Libsvm学习笔记

然后解压,

把svm.cpp和svm.h复制出来,因为对于我们做开发的,只需要这两个文件就可以了,然后把这两个文件放到vs的项目文件下,然后进行调用。
本篇博文主要讲,如何调用使用libsvm,我主要是通过两个简单的例子,演示如何调用libsvm。因为有了例子,学起来非常容易。
一、二分类测试案例
svm算法是学习训练算法,因此调用的步骤是:
1、数据归一化,数据归一化这一步libsvm好像没有提供函数,所以这一步要自己手动写一些代码,如果没有进行归一化,有的时候会出现问题。
2、数据训练
训练调用函数:
struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param);只要学会这个函数的调用就可以实现训练了。
这个函数包含两个输入参数,第一个参数prob用于输入训练数据,包括输入特征X,训练数据标签y,训练样本的个数,具体svm_problem结构体的定义如下:
struct svm_problem
{
int l;//训练数据的个数
double *y;//训练数据的标签,y[i]表示第i个样本的标签
struct svm_node **x;//训练数据的特征,x[i][j]表示第i个样本的第j个特征值
};
第二个参数,定义了svm算法的相关初始化参数,比如惩罚因子、核函数等,具体的结构体定义如下:
struct svm_parameter
{
int svm_type;//svm的类型,包括分类、预测拟合等,如果想用svm进行分类那么可以选择C_SVC,如果想用于拟合预测那么可以选择EPSILON_SVR
int kernel_type;//核函数类型,包括线性核函数、高斯核函数、S激活函数、多项式
int degree; /* for poly */
double gamma; /* for poly/rbf/sigmoid */
double coef0; /* for poly/sigmoid */
/* these are for training only */
double cache_size; /* in MB */
double eps; /* stopping criteria *///迭代误差终止条件
double C; /* for C_SVC, EPSILON_SVR and NU_SVR *///惩罚因子
int nr_weight; /* for C_SVC */
int *weight_label; /* for C_SVC */
double* weight; /* for C_SVC */
double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */
double p; /* for EPSILON_SVR */
int shrinking; /* use the shrinking heuristics */
int probability; /* do probability estimates */
};
具体每个参数的含义,在svm.h文件的定义中,都用相关的注释。
因此进行训练的时候,需要对这两个结构体的相关参数非常清晰。
在上面输入训练数据后,我们一般是先调用下面这个函数:
const char *svm_check_parameter(const struct svm_problem *prob, const struct svm_parameter *param);这个函数可以进行检验你输入的参数pro,para的格式是否正确,调用完后,才调用svm_train()函数,这样可以确保输入的数据和svm的参数设置没有错后在进行训练。
3、数据预测分类
通过调用svm_train()函数完成训练过程,将返回参数svm_model模型。接着如果要进行预测分类可以调用如下函数:
double svm_predict(const struct svm_model *model, const struct svm_node *x);这个函数的第一个输入参数就是我们通过训练过程得到的svm_model,第二个参数就是*x就是输入特征,如x[i]表示第i维特征的数值。数据的返回值,如果你是二分类模型,那么将返回数据标签:-1.0,1.0。如果你是用于预测拟合,那么将返回预测到的数值。
开始写代码前,我觉得svm_node的格式需要说明一下:
struct svm_node //储存单一向量的单个特征
{
int index; //索引
double value; //值
};
svm_node是定义特征向量的标准输入格式。假设有三维的特征向量X=(10,1,3),那么就需要使用语句:new svm_node*x=new svm_node[4],来定义一个特征向量,然后特征就可以使用3个svm_node来保存:
| index |
1 |
2 |
3 |
|
-1 |
|
| value |
10 |
1 |
3 |
|
NULL |
最后一个svm_node是结束的标志,其索引值为-1,数值随便。libsvm就是通过判断其索引是否为-1,来判别特征向量结束的。
OK,接着就用例子作为演示示例,下面是一个二分类的例子,通过输入一个人的身高和体重特征,判别其男性还是女性。下面的例子没有经过归一化,所以其实是不规范的,libsvm并没有进行内部归一化,要自己进行外部归一化好后,在调用libsvm,因为我选用了核函数为线性核函数,有没有归一化好像没啥影响,然而如果选择其他的核函数,那就会发现没有归一化会出现的问题了。
下面我先通过win32控制台,进行测试的一个例子:
#include "stdafx.h"
#include "svm/svm.h"
#include <iostream>
svm_parameter Initialize_svm_parameter()
{
svm_parameter svmpara;//svm的相关参数
svmpara.svm_type = C_SVC;
svmpara.kernel_type = LINEAR;
svmpara.degree = 3;
svmpara.gamma = 0; // 默认大小可选择特征的倒数 1/num_features,核函数中的gamma函数设置(只针对多项式/rbf/sigmoid核函数)
svmpara.coef0 = 0;
svmpara.nu = 0.5;
svmpara.cache_size = 1;//缓存块大小
svmpara.C = 1;
svmpara.eps = 1e-3;
svmpara.p = 0.1;
svmpara.shrinking = 1;
svmpara.probability = 0;
svmpara.nr_weight = 0;
svmpara.weight_label = NULL;
svmpara.weight = NULL;
return svmpara;
}
//二分类测试
//下面是通过人体身高和体重,进行性别的判别
int _tmain(int argc, _TCHAR* argv[])
{
/*训练样本选取是学生的身高和体重:
男1:身高:190cm,体重:70kg;
男2:身高:180cm,体重:80kg;
女1:身高:161cm,体重:80kg;
女2:身高:161cm,体重:47kg;*/
int sample_num=4;//训练样本个数为4
int feature_dimn=2;//样本的特征维数为2
double *y=new double[sample_num];
double **x=new double *[sample_num];
for (int i=0;i<sample_num;i++)
{
x[i]=new double[feature_dimn];
}
x[0][0]=190;x[0][1]=70;y[0]=-1;//训练样本1
x[1][0]=180;x[1][1]=80;y[1]=-1;//训练样本2
x[2][0]=161;x[2][1]=80;y[2]=1;//训练样本3
x[3][0]=161;x[3][1]=47;y[3]=1;//训练样本4
//训练数据输入
svm_parameter svmpara=Initialize_svm_parameter();//svm参数初始化
svm_problem svmpro;//svm训练数据
svmpro.l=sample_num;
svmpro.y=y;//训练数据标签
svmpro.x=new svm_node *[sample_num];//训练数据的特征向量
for (int i=0;i<sample_num;i++)
{
svmpro.x[i]=new svm_node[feature_dimn+1];
for (int j=0;j<feature_dimn;j++)
{
svm_node node_ij;
node_ij.index=j+1;//需要注意的是svm_node的第一个数据的索引为1,数值为第一位特征值,我一开始这里搞错了,把索引搞成从0开始
node_ij.value=x[i][j];
svmpro.x[i][j]=node_ij;
}
svm_node node_last;//需要添加最后一维特征的索引为-1
node_last.index=-1;
svmpro.x[i][feature_dimn]=node_last;
}
//验证输入的训练数据、初始化的参数是否有误
const char *error_msg;
error_msg = svm_check_parameter(&svmpro,&svmpara);
if(error_msg)
{
std::cout<<error_msg;
return 0;
}
//数据训练
svm_model *svmmodel=svm_train(&svmpro,&svmpara);
/*预测数据1:身高180cm,体重85kg;
预测数据2:身高161cm,体重50kg;*/
svm_node *testX1=new svm_node[feature_dimn+1];
testX1[0].index=1;
testX1[0].value=180;
testX1[1].index=2;
testX1[1].value=85;
testX1[2].index=-1;
double testY1=svm_predict(svmmodel,testX1);
std::cout<<"测试预测1:"<<testY1<<std::endl;
svm_node *testX2=new svm_node[feature_dimn+1];
testX2[0].index=1;
testX2[0].value=161;
testX2[1].index=2;
testX2[1].value=50;
testX2[2].index=-1;
double testY2=svm_predict(svmmodel,testX2);//分类预测函数
std::cout<<"测试预测2:"<<testY2<<std::endl;
return 0;
}
最后的运行正确结果:
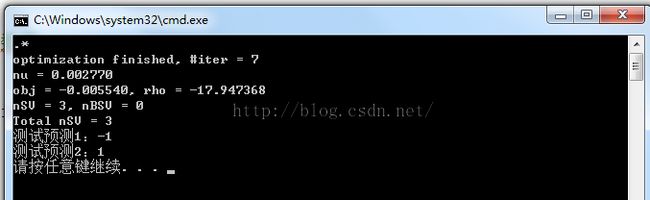
二、数据预测拟合案例
接着这个例子是要演示,使用libsvm进行如下图所示的数据拟合,通过数据输入二维的数据点,然后拟合出曲线,也就是相当于输入特征x,然后预测y值:
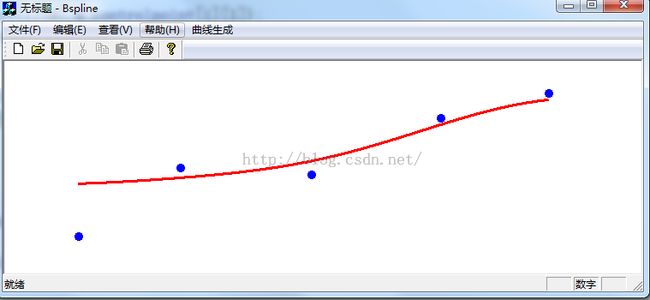
因此这个特征向量X是一维特征向量。
下面是通过svm进行数据拟合预测的类,为了方便我先把它它的调用封装成类,.cpp文件如下:
CLibsvm::CLibsvm(float C,float gamma,float epsilon)
{
m_svmpara=Initialize_svm_parameter(C,gamma,epsilon);
}
CLibsvm::~CLibsvm(void)
{
}
svm_parameter CLibsvm::Initialize_svm_parameter(float C,float gamma,float epsilon)
{
svm_parameter svmpara;//svm的相关参数
svmpara.svm_type = EPSILON_SVR;
svmpara.kernel_type =RBF;
svmpara.degree = 3;
svmpara.gamma = gamma; // 默认大小可选择特征的倒数 1/num_features,核函数中的gamma函数设置(只针对多项式/rbf/sigmoid核函数)
svmpara.coef0 = 0;
svmpara.nu = 0.5;
svmpara.cache_size = 1;//缓存块大小
svmpara.C = C;
svmpara.eps = 1e-3;
svmpara.p = epsilon;
svmpara.shrinking = 1;
svmpara.probability = 0;
svmpara.nr_weight = 0;
svmpara.weight_label = NULL;
svmpara.weight = NULL;
return svmpara;
}
//拟合数据输入
void CLibsvm::TrainModel(vector<vec2>traindata)
{
//Normalizedata(traindata,m_minpt,m_maxpt);
int sample_num=traindata.size();//训练样本个数
int feature_dimn=1;//样本的特征维数为1
double *y=new double[sample_num];
double **x=new double *[sample_num];
for (int i=0;i<sample_num;i++)
{
x[i]=new double[feature_dimn];
}
for (int i=0;i<sample_num;i++)
{
y[i]=traindata[i][feature_dimn];
for (int j=0;j<feature_dimn;j++)
{
x[i][j]=traindata[i][j];
}
}
//训练数据归一化
//获取最大最小值
GetMax_Min(y,sample_num,m_miny,m_maxy);//训练数据y的最大最小值获取
m_minx=new double[feature_dimn];//特征最大最小值获取
m_maxx=new double[feature_dimn];
double *pdata=new double[sample_num];
for (int j=0;j<feature_dimn;j++)
{
for (int i=0;i<sample_num;i++)
{
pdata[i]=x[i][j];
}
GetMax_Min(pdata,sample_num,m_minx[j],m_maxx[j]);
}
//训练数据归一化
for (int i=0;i<sample_num;i++)
{
y[i]=2*(y[i]-m_miny)/(m_maxy-m_miny)-1;
for (int j=0;j<feature_dimn;j++)
{
x[i][j]=2*(x[i][j]-m_minx[j])/(m_maxx[j]-m_minx[j])-1;
}
}
//训练数据输入
svm_problem svmpro;//svm训练数据
svmpro.l=sample_num;
svmpro.y=new double[sample_num];
svmpro.x=new svm_node *[sample_num];//训练数据的特征向量
for (int i=0;i<sample_num;i++)
{
svmpro.y[i]=y[i];//用训练数据的y,作为输入标签
svmpro.x[i]=new svm_node[feature_dimn+1];
for (int j=0;j<feature_dimn;j++)
{
svm_node node_ij;
node_ij.index=j+1;//需要注意的是svm_node的第一个数据的索引为1,数值为第一位特征值,我一开始这里搞错了,把索引搞成从0开始
node_ij.value=x[i][j];
svmpro.x[i][j]=node_ij;
}
svm_node node_last;//需要添加最后一维特征的索引为-1
node_last.index=-1;
svmpro.x[i][feature_dimn]=node_last;
}
//验证输入的训练数据、初始化的参数是否有误
const char *error_msg;
error_msg = svm_check_parameter(&svmpro,&m_svmpara);
if(error_msg)
{
AfxMessageBox(error_msg);
}
//数据训练
m_svmmodel=svm_train(&svmpro,&m_svmpara);
}
void CLibsvm::Predict(float x,float &y)
{
x=2*(x-m_minx[0])/(m_maxx[0]-m_minx[0])-1;
svm_node *testX1=new svm_node[1+1];
testX1[0].index=1;
testX1[0].value=x;
testX1[1].index=-1;
y=(svm_predict(m_svmmodel,testX1)+1)*(m_maxy-m_miny)*0.5+m_miny;
}
//数据归一化
void CLibsvm::GetMax_Min(double*pdata,int data_num,double &minpt,double&maxpt)
{
double minx=1e10;
double maxx=-1e10;
for (int i=0;i<data_num;i++)
{
if (pdata[i]<minx)
{
minx=pdata[i];
}
if (pdata[i]>maxx)
{
maxx=pdata[i];
}
}
minpt=minx;
maxpt=maxx;
}
然后是头文件:
#pragma once
#include "svm/svm.h"
#include "Vec.h"
#include <vector>
class CLibsvm
{
public:
CLibsvm(float C=1,float gamma=1,float epsilon=0.1);
~CLibsvm(void);
void TrainModel(vector<vec2>traindata);//数据训练
void Predict(float x,float &y);//拟合预测函数
private:
svm_parameter Initialize_svm_parameter(float C=1,float gamma=1,float epsilon=0.1);//参数初始化函数
svm_parameter m_svmpara;
svm_problem m_svmprob;
std::vector<vec2>m_traindata;//二维拟合数据
svm_model *m_svmmodel;
void GetMax_Min(double*pdata,int data_num,double &minpt,double&maxpt);//获取数据归一化的最大最小值
double *m_maxx;//归一化用的参数
double *m_minx;
double m_miny;
double m_maxy;
};
OK,接着是封装好的这个类的调用:
//m_controlpoint为训练数据,也就是鼠标输入蓝色的点
CLibsvm csvm(1);
csvm.TrainModel(m_controlpoint);//二维数据点
/*
CLibsvm csvm2(1,1);
csvm2.TrainModel(m_controlpoint);*/
float minx=1e10;
float maxx=0;
for (int i=0;i<m_controlpoint.size();i++)
{
if (m_controlpoint[i][0]<minx)
{
minx=m_controlpoint[i][0];
}
if (m_controlpoint[i][0]>maxx)
{
maxx=m_controlpoint[i][0];
}
}
m_resultcurve.clear();
for (int i=minx;i<maxx;i++)
{
float y=0;
csvm.Predict(i,y);
m_resultcurve.push_back(vec2(i,y));//绘制拟合曲线
float y2=0;
/*
csvm2.Predict(i,y2);
m_resultcurve2.push_back(vec2(i,y2));*/
}
接着分析一下CLibsvm构造函数的三个参数好如何选择:
首先第一个参数是惩罚因子,这个参数越大,拟合出来的曲线自然而然越精确,测试一下,测试代码如下:
//m_controlpoint为训练数据,也就是鼠标输入蓝色的点
CLibsvm csvm(1);
csvm.TrainModel(m_controlpoint);//二维数据点
CLibsvm csvm2(100);
csvm2.TrainModel(m_controlpoint);
float minx=1e10;
float maxx=0;
for (int i=0;i<m_controlpoint.size();i++)
{
if (m_controlpoint[i][0]<minx)
{
minx=m_controlpoint[i][0];
}
if (m_controlpoint[i][0]>maxx)
{
maxx=m_controlpoint[i][0];
}
}
m_resultcurve.clear();
for (int i=minx;i<maxx;i++)
{
float y=0;
csvm.Predict(i,y);
m_resultcurve.push_back(vec2(i,y));//绘制拟合曲线
float y2=0;
csvm2.Predict(i,y2);
m_resultcurve2.push_back(vec2(i,y2));
}
通过分别选用C=1 和C=100的参数,得到如下绿色和红色结果曲线,红色的曲线为C=100得到的结果:
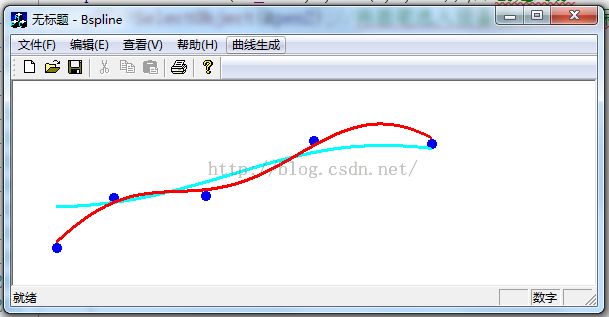
OK,接着测试一下,参数sigma对结果的影响,测试代码如下:
CLibsvm csvm(1,1);
csvm.TrainModel(m_controlpoint);//二维数据点
CLibsvm csvm2(1,100);
csvm2.TrainModel(m_controlpoint);
float minx=1e10;
float maxx=0;
for (int i=0;i<m_controlpoint.size();i++)
{
if (m_controlpoint[i][0]<minx)
{
minx=m_controlpoint[i][0];
}
if (m_controlpoint[i][0]>maxx)
{
maxx=m_controlpoint[i][0];
}
}
m_resultcurve.clear();
for (int i=minx;i<maxx;i++)
{
float y=0;
csvm.Predict(i,y);
m_resultcurve.push_back(vec2(i,y));//绘制拟合曲线
float y2=0;
csvm2.Predict(i,y2);
m_resultcurve2.push_back(vec2(i,y2));
}
上面的代码中,我分别选择sigma=1,sigma=100进行比较,结果如下:
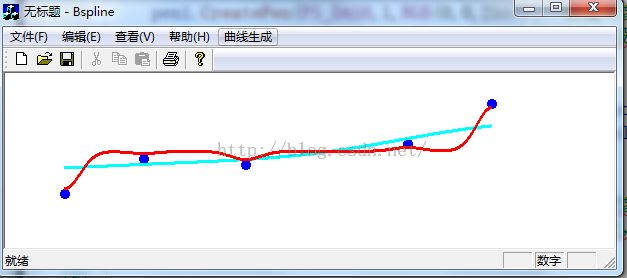
可以看到与C一样,参数越大,对于训练数据,其误差越小。当然我们需要知道,对于机器学习算法来说,训练数据后的误差越小并不是越好,上面的结果其实是过拟合的。
**********作者:hjimce 联系qq:1393852684 更多资源请关注我的博客:http://blog.csdn.net/hjimce 原创文章,版权所有,转载请保留本行信息。******************
参考文献:
1、http://blog.csdn.net/liulina603/article/details/8532837