data-intensive text processing with mapreduce-MapReduce Algorithm Design
MapReduce Algorithm Design
in-mapper combining
Main idea:通过借用Map手动实现聚集,在Mapper中实现Combiner。
Example:WordCount

Reason:
1.Hadoop的Combiner机制不管key的分布,都会执行combine,如很多key都只有唯一的value与他对应,则Combiner就没有作用,而且在combine之前,还会有排序等操作。
2.对象的序列化与反序列化会耗费系统资源。
Disadvantages:
1.破坏了MapReduce函数编程思想,但效率大大提高。
2.内存瓶颈,由于借用的Map中的key可能数量巨大,最后可能导致Map不能完全放在内存当中。
Solve the disadvantages:处理N个key-value对之后,或者Map的size达到一定量级就写出一次,但是N和size是很难确定的量。
Summary:With local aggregation (either combiners or in-mapper combining), we substantially reduce the number of values associated with frequently-occurring terms,which alleviates the reduce straggler problem.
the correctness of the aggravated algorithm
Main idea:一些聚集函数(mean)不满足结合律和交换律,需要做适当变换,以满足结合律和交换率
Example:Mean

Optimize:结合之前的in-mapper combiner,进一步提高效率。

Pairs and Strips
Main idea:Pairs:将key用组合形式表示;Strips:针对一个特定的key将value用Map表示。
Examples:语料库中单词同现次数。
Pairs:

Strips:

Discussion:
1.Pairs产生的key-value对数量远大于Strips,Strips的数据压缩更紧密,但是Strips序列化和反序列化的操作较多。
2.虽然Pairs和Strips都可以用Combiner来优化,但是Strips优化的效率更高(key的数量更小)。
3.pairs方法记录了同时出现的事件,然而strips记录了事件a发生时的所有事件。
4.折中的方式是先strips为一定桶,每一个桶内再pairs
Pairs和Strips代码:
package PairsAndStrips;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
import java.util.List;
/**
* Created with IntelliJ IDEA.
* User: ubuntu
* Date: 13-11-7
* Time: 下午8:10
* To change this template use File | Settings | File Templates.
*/
public class WholeFileInputFormat extends FileInputFormat {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeFileRecordReader recordReader = new WholeFileRecordReader();
// recordReader.initialize(split,context);
return recordReader;
}
}
package PairsAndStrips;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: ubuntu
* Date: 13-11-7
* Time: 下午8:13
* To change this template use File | Settings | File Templates.
*/
public class WholeFileRecordReader extends RecordReader<NullWritable,BytesWritable> {
private FileSplit split;
private boolean taskProcessed = false;
private BytesWritable value = new BytesWritable();
private TaskAttemptContext context;
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.split = (FileSplit) split;
this.context = context;
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (taskProcessed == false) {
byte[] bytes = new byte[(int) split.getLength()];
FileSystem fileSystem = FileSystem.get(context.getConfiguration());
FSDataInputStream fsDataInputStream = fileSystem.open(split.getPath());
try {
IOUtils.readFully(fsDataInputStream,bytes,0,bytes.length);
} catch (IOException e) {
e.printStackTrace(); //To change body of catch statement use File | Settings | File Templates.
} finally {
IOUtils.closeStream(fsDataInputStream);
}
value.set(bytes,0, bytes.length);
taskProcessed = true;
return true;
}
return false; //To change body of implemented methods use File | Settings | File Templates.
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get(); //To change body of implemented methods use File | Settings | File Templates.
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value; //To change body of implemented methods use File | Settings | File Templates.
}
@Override
public float getProgress() throws IOException, InterruptedException {
return taskProcessed ? 1 : 0; //To change body of implemented methods use File | Settings | File Templates.
}
@Override
public void close() throws IOException {
//To change body of implemented methods use File | Settings | File Templates.
}
}
package PairsAndStrips;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: ubuntu
* Date: 13-11-7
* Time: 下午7:49
* To change this template use File | Settings | File Templates.
*/
public class Pairs extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new Pairs(), args);
System.exit(exitCode);
}
public static class Pair implements WritableComparable {
private Text left;
private Text right;
public Pair() {
left = new Text();
right = new Text();
}
public Text getLeft() {
return left;
}
public void setLeft(Text left) {
this.left = left;
}
public Text getRight() {
return right;
}
public void setRight(Text right) {
this.right = right;
}
@Override
public int compareTo(Object o) {
Pair that = (Pair) o;
int cmp = this.getLeft().compareTo(that.getLeft());
if(cmp != 0) {
return cmp;
}
return this.getRight().compareTo(that.getRight());
}
@Override
public void write(DataOutput out) throws IOException {
left.write(out);
right.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
left.readFields(in);
right.readFields(in);
}
@Override
public int hashCode() {
return left.hashCode()*13+ right.hashCode();
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Pair) {
Pair that = (Pair)obj;
return this.getLeft().equals(that.getLeft()) && this.getRight().equals(that.getRight());
}
return false;
}
@Override
public String toString() {
return left.toString()+"-"+right.toString();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Pairs");
job.setJarByClass(Pairs.class);
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Pair.class);
job.setOutputValueClass(IntWritable.class);
WholeFileInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
/* Configuration conf = new Configuration();
Job job = new Job(conf, "Pairs");
job.setJarByClass(Pairs.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;*/
}
public static class MyMapper extends Mapper<NullWritable, BytesWritable, Pair, IntWritable> {
private Pair outKey = new Pair();
private IntWritable outValue = new IntWritable(1);
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
String[] tokens =new String(value.getBytes(),0,value.getLength()).split(" ");
// String[] tokens = value.toString().split(" ");
// System.out.println(tokens[0]+tokens[1]);
for (int i = 0; i < tokens.length - 1; i++) {
outKey.setLeft(new Text(tokens[i]));
outKey.setRight(new Text(tokens[i + 1]));
System.out.println(outKey);
context.write(outKey, outValue);
}
}
}
// public static class MyMapper extends Mapper<LongWritable,Text, Text, IntWritable> {
// private Text outKey = new Text();
// private IntWritable outValue = new IntWritable(1);
//
// @Override
// protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// String[] strings = value.toString().split(" ");
// for (int i = 0; i < strings.length; i++) {
// outKey.set(strings[i]);
// context.write(outKey ,outValue);
// }
// }
// }
public static class MyReducer extends Reducer<Pair, IntWritable, Pair, IntWritable> {
private IntWritable outValue = new IntWritable();
@Override
protected void reduce(Pair key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outValue.set(sum);
context.write(key, outValue);
}
}
/*public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outValue.set(sum);
context.write(key, outValue);
}
}*/
}
package PairsAndStrips;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Created with IntelliJ IDEA.
* User: Jack
* Date: 13-11-10
* Time: 上午10:17
* To change this template use File | Settings | File Templates.
*/
public class Strips extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new Strips(), args);
System.exit(exitCode);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Strips");
job.setJarByClass(Strips.class);
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(StripsMapper.class);
job.setReducerClass(StripsReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Strip.class);
return job.waitForCompletion(true) ? 0 : 1; //To change body of implemented methods use File | Settings | File Templates.
}
public static class StripsMapper extends Mapper<NullWritable, BytesWritable, Text, Strip> {
private HashMap<String, Strip> wordStripHashMap = new HashMap<String, Strip>();
private Strip strip;
private Text outkey = new Text();
private Strip outvalue = new Strip();
/* @Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
String[] tokens = new String(value.getBytes(), 0, value.getLength()).trim().split(" ");
*//* for (int i = 0; i < tokens.length; i++) {
System.out.println(tokens[i]);
outkey.set(tokens[i]);
// outvalue = new Strip();
outvalue.put(tokens[i],1);
System.out.println(outkey+"-----------------------"+outvalue);
context.write(outkey, outvalue);
}*//*
System.out.println(tokens.length);
for (int i = 0; i < tokens.length; i++) {
System.out.println(tokens[i]);
outkey.set(tokens[i]);
outvalue.put(tokens[i], tokens[i].length());
//outvalue.getStripMap().put(tokens[i],1);
context.write(outkey, outvalue);
System.out.println(i + "+" + outkey + "*" + outvalue);
outvalue.clear();
}
}*/
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
String[] tokens = new String(value.getBytes(), 0, value.getLength()).trim().split(" ");
for (int i = 0; i < tokens.length - 1; i++) {
if (false == wordStripHashMap.containsKey(tokens[i])) {
wordStripHashMap.put(tokens[i], new Strip());
}
strip = wordStripHashMap.get(tokens[i]);
mapPlus(strip.getStripMap(), tokens[i + 1]);
}
for (Map.Entry<String, Strip> stringStripEntry : wordStripHashMap.entrySet()) {
outkey.set(stringStripEntry.getKey());
outvalue.set(stringStripEntry.getValue());
context.write(outkey, outvalue);
System.out.println(outkey + "====================" + outvalue);
}
}
private Integer mapPlus(HashMap<String, Integer> hashMap, String key) {
if (hashMap.containsKey(key)) {
return hashMap.put(key, hashMap.get(key) + 1);
} else {
return hashMap.put(key, 1);
}
}
}
public static class StripsReducer extends Reducer<Text, Strip, Text, Strip> {
private Strip strip = new Strip();
@Override
protected void reduce(Text key, Iterable<Strip> values, Context context) throws IOException, InterruptedException {
System.out.println("+-------------------------------------------------------------------------------+");
for (Strip value : values) {
System.out.println(key + "+" + value);
Set<Map.Entry<String, Integer>> entries = value.getStripMap().entrySet();
for (Map.Entry<String, Integer> entry : entries) {
mapPlus(strip, entry.getKey(), entry.getValue());
}
}
context.write(key, strip);
System.out.println(key + "****" + strip);
strip.clear();
System.out.println(strip.size());
}
// @Override
// protected void reduce(Text key, Iterable<Strip> values, Context context) throws IOException, InterruptedException {
// for (Strip value : values) {
// System.out.println(key+"-----"+value);
// context.write(key,value);
// }
// }
private Integer mapPlus(Strip strip, String key, int num) {
HashMap<String, Integer> hashMap = strip.getStripMap();
if (hashMap.containsKey(key)) {
return hashMap.put(key, hashMap.get(key) + num);
} else {
return hashMap.put(key, num);
}
}
}
}
class Strip implements WritableComparable {
@Override
public int compareTo(Object o) {
Strip that = (Strip) o;
return this.size() > that.size() ? 1 : this.size() < that.size() ? -1 : 0;
}
private HashMap<String, Integer> stripMap;
public Strip() {
stripMap = new HashMap<String, Integer>();
}
@Override
public int hashCode() {
return stripMap.hashCode() * 131 + stripMap.size();
}
@Override
public boolean equals(Object obj) {
return stripMap.equals(((Strip) obj).getStripMap()); //To change body of overridden methods use File | Settings | File Templates.
}
@Override
public String toString() {
String outString = "";
for (String s : stripMap.keySet()) {
outString += s + "-" + stripMap.get(s) + "||";
}
return outString;
}
HashMap<String, Integer> getStripMap() {
return stripMap;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(stripMap.size());
for (String s : stripMap.keySet()) {
dataOutput.writeUTF(s);
dataOutput.writeInt(stripMap.get(s));
}
}
@Override
public void readFields(DataInput dataInput) throws IOException {
stripMap.clear();
int size = dataInput.readInt();
for (int i = 0; i < size; i++) {
stripMap.put(dataInput.readUTF(), dataInput.readInt());
}
}
public int size() {
return stripMap.size();
}
public Integer put(String key, int value) {
return stripMap.put(key, value);
}
public int get(Object key) {
return stripMap.get(key);
}
public void set(Strip value) {
this.stripMap = value.getStripMap();
}
public void clear() {
stripMap.clear();
}
}
写代码过程中的主要问题 Strip反序列化时需要clear,put(K,V)需要返回V对象,不能因为是Integer写成int,否则会有空指针异常。
Computing Relative Frequencies
MainIdea:利用Hadoop内部机制实现顺序反转,提高计算性能
Example:计算相对词频矩阵
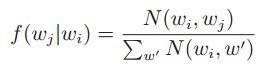
Strips:比较方便,直接在reduce端进行求边缘值(类似于概率中的边缘概率分布),再计算相对词频。

Pairs:借用Hadoop内部机制实现,map每产生一个key-value对,附带产生一个(left,*)-1,用于统计left出现的次数;自定义partiticon,将left相同的key-value划分到同一个reduce;自定义排序方式将(left,*)排在第一个。reduce得到的输入如下:

第一个key-value对用于计算边缘值,后续的value/边缘值即可得到相对词频。
具体代码如下:
package PairsAndStrips;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: ubuntu
* Date: 13-11-7
* Time: 下午7:49
* To change this template use File | Settings | File Templates.
*/
public class PairRelativeCal extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new PairRelativeCal(), args);
System.exit(exitCode);
}
public static class Pair implements WritableComparable {
private Text left;
private Text right;
public Pair() {
left = new Text();
right = new Text();
}
public Text getLeft() {
return left;
}
public void setLeft(Text left) {
this.left = left;
}
public Text getRight() {
return right;
}
public void setRight(Text right) {
this.right = right;
}
@Override
public int compareTo(Object o) {
Pair that = (Pair) o;
int cmp = this.getLeft().compareTo(that.getLeft());
if (cmp != 0) {
return cmp;
}
if (this.getRight().toString().equals("*") && that.getRight().toString().equals("*")) {
return 0;
} else if (this.getRight().toString().equals("*")) {
return -1;
} else if (that.getRight().toString().equals("*")) {
return 1;
} else {
return this.getRight().compareTo(that.getRight());
}
}
@Override
public void write(DataOutput out) throws IOException {
left.write(out);
right.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
left.readFields(in);
right.readFields(in);
}
@Override
public int hashCode() {
return left.hashCode() * 13 + right.hashCode();
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Pair) {
Pair that = (Pair) obj;
return this.getLeft().equals(that.getLeft()) && this.getRight().equals(that.getRight());
}
return false;
}
@Override
public String toString() {
return left.toString() + "-" + right.toString();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Pairs");
job.setJarByClass(Pairs.class);
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(MyMapper.class);
job.setPartitionerClass(MyPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Pair.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Pair.class);
job.setOutputValueClass(DoubleWritable.class);
WholeFileInputFormat.addInputPath(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static class MyMapper extends Mapper<NullWritable, BytesWritable, Pair, IntWritable> {
private Pair outKey = new Pair();
private IntWritable outValue = new IntWritable(1);
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
String[] tokens = new String(value.getBytes(), 0, value.getLength()).trim().split(" ");
// String[] tokens = value.toString().split(" ");
// System.out.println(tokens[0]+tokens[1]);
for (int i = 0; i < tokens.length - 1; i++) {
outKey.setLeft(new Text(tokens[i]));
outKey.setRight(new Text(tokens[i + 1]));
System.out.println(outKey);
context.write(outKey, outValue);
outKey.setRight(new Text("*"));
context.write(outKey, outValue);
System.out.println(outKey);
}
}
}
public static class MyPartitioner extends Partitioner<Pair, IntWritable> {
@Override
public int getPartition(Pair pair, IntWritable intWritable, int numPartitions) {
return (pair.getLeft().hashCode() * 13) % numPartitions;
}
}
public static class MyReducer extends Reducer<Pair, IntWritable, Pair, DoubleWritable> {
private DoubleWritable outValue = new DoubleWritable();
private double count;
@Override
protected void reduce(Pair key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println(key);
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
if (key.getRight().toString().equals("*")) {
count = sum;
} else {
outValue.set(sum / count);
context.write(key, outValue);
}
}
}
}
Discussion:Strips有内存瓶颈问题,而Pairs就不存在该问题。下图是原书对Pairs方法的总结,与上述的实现方式一致。

Secondary Sorting
MainIdea:"value-to-key conversion" design pattern:The basic idea is to move part of the value into the intermediate key to form a composite key, and let the MapReduce execution framework handle the sorting.(原本按key排序后再按照value排序,将key和value组合成新的key,利用hadoop内部机制排序)
Discussion:不会存在内存瓶颈,但是会产生更多的key,充分利用hadoop对key排序的机制。另一实现方式是 象书中提到的基于Group的二次排序
Relational Joins
Reduce-side Join
MainIdea: 将待join的两个数据集重新划分,然后在reduce阶段执行join
Example:
one-to-one:一个S对应一个T,外键作为key,其余的属性作为值
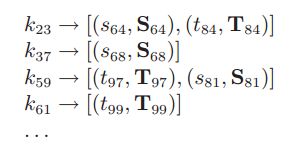
one-to-many:一个S对应多个T,用value-to-key的模式,将来源编号作为key的一部分,并且自定义key的排序规则,让来源为S的项排在来源为T的项之前,另外,还需要自定义partitioner。
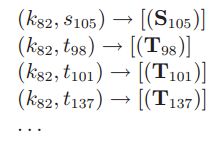
many-to-many:S与T是多对多的关系,方法与one-to-many类似,排序规则是将规模较小的数据排在前面。(内存瓶颈)

Map-Side Join
MainIdea:通常Map-Side Join的输入数据是其他MapReduce作业的输出结果,这些输入数据要满足同一个区间范围的S和T对应,并且内部有序。(若直接链接在其他reduce后面,定义适当的partitioner?),若从文件读取,可能需要自定义inputformat实现
Memory-Backed Join
MainIdea:将较小的数据S,写入分布式缓存中,在Mapper的setup阶段生成一个hashmap,用map处理较大的数据,查询hashmap,执行join。在hashmap无法完全存放于内存时,可以借用分布式内存数据库(memecache)实现。
Summary
1.构造复杂的key和value。
2.充分利用setup与close。
3.保存map和reduce的数据来源状态。
4.控制中间结果的顺序。
5.控制中间结果的partition。
6.构造辅助的 适当key-value对,如Pairs的相对词频时使用的 (key,*)-n
待续