Shark集群搭建配置
一、Shark简介
Shark是基于Spark与Hive之上的一种SQL查询引擎,官网的架构图及性能测试图如下:(Ps:本人也做了一个性能测试见Shark性能测试报告)
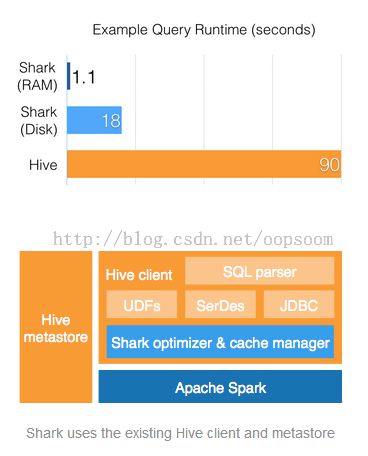
我们涉及到了2个依赖组件,1是Apache Spark, 另外一个是AMPLAB的Hive0.11.
这里注意版本的选择,一定要选择官方的推荐版本:
Spark0.91 + AMPLAB Hive0.11 + Shark0.91
一定要自己编译好它们,适用于自己的集群。
二、Shark集群搭建
1. 搭建Spark集群,这个可以参照:Spark集群搭建。
2. 编译AMPLAB的Hive0.11, 进入到根目录下直接 ant package.
3.编译Shark,这个步骤和编译Spark是一样的,和HDFS的版本记得兼容就行,修改project下面的SharkBuild.scala里面的Hadoop版本号,然后sbt/sbt assembly.
三、启动Spark + Shark
首先,启动Spark,这里要修改spark的配置文件,在Spark-env.sh里面配置:
HADOOP_CONF_DIR=/home/hadoop/src/hadoop/conf SPARK_CLASSPATH=/home/hadoop/src/hadoop/lib/:/app/hadoop/shengli/sharklib/* SPARK_LOCAL_DIRS=/app/hadoop/shengli/spark/data SPARK_MASTER_IP=10.1.8.210 SPARK_MASTER_WEBUI_PORT=7078
接着,配置Spark的spark-defaults.conf
spark.master spark://10.1.8.210:7077 spark.executor.memory 32g spark.shuffle.spill true java.library.path /usr/local/lib spark.shuffle.consolidateFiles true # spark.eventLog.enabled true # spark.eventLog.dir hdfs://namenode:8021/directory # spark.serializer org.apache.spark.serializer.KryoSerializer
10.1.8.210 #这里master节点不会做cache 10.1.8.211 10.1.8.212 10.1.8.213
最后启动集群,sbin/start-all.sh,至此Spark集群配置完毕。
Shark有依赖的Jar包,我们集中将其拷贝到一个文件夹内:
#!/bin/bash
for jar in `find /home/hadoop/shengli/shark/lib -name '*jar'`; do
cp $jar /home/hadoop/shengli/sharklib/
done
for jar in `find /home/hadoop/shengli/shark/lib_managed/jars -name '*jar'`; do
cp $jar /home/hadoop/shengli/sharklib/
done
for jar in `find /home/hadoop/shengli/shark/lib_managed/bundles -name '*jar'`; do
cp $jar /home/hadoop/shengli/sharklib/
done
配置Shark,在shark/conf/shark-env.sh中配置
# format as the JVM's -Xmx option, e.g. 300m or 1g. export JAVA_HOME=/usr/java/jdk1.7.0_25 # (Required) Set the master program's memory #export SHARK_MASTER_MEM=1g # (Optional) Specify the location of Hive's configuration directory. By default, # Shark run scripts will point it to $SHARK_HOME/conf #export HIVE_CONF_DIR="" export HADOOP_HOME=/home/hadoop/src/hadoop # For running Shark in distributed mode, set the following: export SHARK_MASTER_MEM=1g export HADOOP_HOME=$HADOOP_HOME export SPARK_HOME=/app/hadoop/shengli/spark export SPARK_MASTER_IP=10.1.8.210 export MASTER=spark://10.1.8.210:7077 # Only required if using Mesos: #export MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so # Only required if run shark with spark on yarn #export SHARK_EXEC_MODE=yarn #export SPARK_ASSEMBLY_JAR= #export SHARK_ASSEMBLY_JAR= # (Optional) Extra classpath #export SPARK_LIBRARY_PATH="" # Java options # On EC2, change the local.dir to /mnt/tmp # (Optional) Tachyon Related Configuration #export TACHYON_MASTER="" # e.g. "localhost:19998" #export TACHYON_WAREHOUSE_PATH=/sharktables # Could be any valid path name #export HIVE_HOME=/home/hadoop/shengli/hive/build/dest export HIVE_CONF_DIR=/app/hadoop/shengli/hive/conf export CLASSPATH=$CLASSPATH:/home/hadoop/src/hadoop/lib:home/hadoop/src/hadoop/lib/native:/app/hadoop/shengli/sharklib/* export SCALA_HOME=/app/hadoop/shengli/scala-2.10.3 #export SPARK_LIBRARY_PATH=/home/hadoop/src/hadoop/lib/native/Linux-amd64-64 #export LD_LIBRARY_PATH=/home/hadoop/src/hadoop/lib/native/Linux-amd64-64 #spark conf copy here SPARK_JAVA_OPTS=" -Dspark.cores.max=8 -Dspark.local.dir=/app/hadoop/shengli/spark/data -Dspark.deploy.defaultCores=2 -Dspark.executor.memory=24g -Dspark.shuffle.spill=true -Djava.library.path=/usr/local/lib " SPARK_JAVA_OPTS+="-Xmx4g -Xms4g -verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedOops " export SPARK_JAVA_OPTS
接下来配置Shark的集群了,我们要将编译好的Spark,Shark,Hive全部都分发到各个节点,保持同步更新rsync。
rsync --update -pav --progress /app/hadoop/shengli/spark/ [email protected]:/app/hadoop/shengli/spark/ ...... rsync --update -pav --progress /app/hadoop/shengli/shark/ [email protected]:/app/hadoop/shengli/shark/ ...... rsync --update -pav --progress /app/hadoop/shengli/hive/ [email protected]:/app/hadoop/shengli/hive/ ...... rsync --update -pav --progress /app/hadoop/shengli/sharklib/ [email protected]:/app/hadoop/shengli/sharklib/ ...... rsync --update -pav --progress /usr/java/jdk1.7.0_25/ [email protected]:/usr/java/jdk1.7.0_25/ ......
启动Shark,可以在WEBUI上查看集群状态(上面配置的是WEB UI PORT 7078)
进入到SHARK_HOME/bin
drwxr-xr-x 4 hadoop games 4.0K Jun 12 10:01 . drwxr-xr-x 13 hadoop games 4.0K Jun 16 16:59 .. -rwxr-xr-x 1 hadoop games 882 Apr 10 19:18 beeline drwxr-xr-x 2 hadoop games 4.0K Jun 12 10:01 dev drwxr-xr-x 2 hadoop games 4.0K Jun 12 10:01 ext -rwxr-xr-x 1 hadoop games 1.4K Apr 10 19:18 shark -rwxr-xr-x 1 hadoop games 730 Apr 10 19:18 shark-shell -rwxr-xr-x 1 hadoop games 840 Apr 10 19:18 shark-withdebug -rwxr-xr-x 1 hadoop games 838 Apr 10 19:18 shark-withinfo
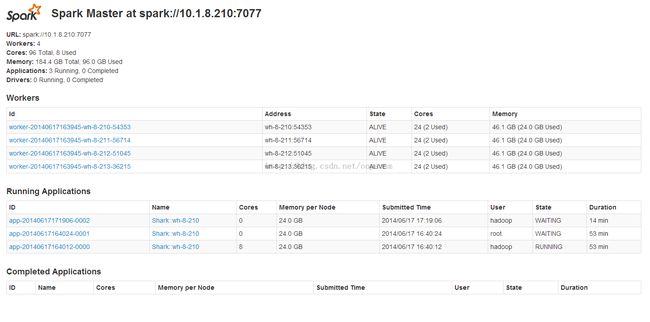
这里shark是直接运行shark
shark-shell类似spark-shell
shark-withdebug是在运行中以DEBUG的log4J模式进入,适合排查错误和理解运行。
shark-withinfo同上。
shark还提供了一种shark-server共享Application中Cacahed RDD概念。
bin/shark -h 10.1.8.210 -p 7100
-h 10.1.8.210 -p 7100 Starting the Shark Command Line Client Logging initialized using configuration in jar:file:/app/hadoop/shengli/sharklib/hive-common-0.11.0-shark-0.9.1.jar!/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_25876@wh-8-210_201406171640_1172020906.txt SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/app/hadoop/shengli/sharklib/slf4j-log4j12-1.7.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/app/hadoop/shengli/sharklib/shark-assembly-0.9.1-hadoop0.20.2-cdh3u5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/app/hadoop/shengli/shark/lib_managed/jars/org.slf4j/slf4j-log4j12/slf4j-log4j12-1.7.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 2.870: [GC 262208K->21869K(1004928K), 0.0274310 secs] [10.1.8.210:7100] shark>
这样就可以用多个client连接这个端口了。
bin/shark -h 10.1.8.210 -p 7100 -h 10.1.8.210 -p 7100 Starting the Shark Command Line Client Logging initialized using configuration in jar:file:/app/hadoop/shengli/sharklib/hive-common-0.11.0-shark-0.9.1.jar!/hive-log4j.properties Hive history file=/tmp/hadoop/hive_job_log_hadoop_28486@wh-8-210_201406171719_457245737.txt SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/app/hadoop/shengli/sharklib/slf4j-log4j12-1.7.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/app/hadoop/shengli/sharklib/shark-assembly-0.9.1-hadoop0.20.2-cdh3u5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/app/hadoop/shengli/shark/lib_managed/jars/org.slf4j/slf4j-log4j12/slf4j-log4j12-1.7.2.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] show ta3.050: [GC 262208K->22324K(1004928K), 0.0240010 secs] ble[10.1.8.210:7100] shark> show tables; Time taken (including network latency): 0.072 seconds
至此,shark启动完毕。
3、测试
来做一个简单的测试,看是否可用,处理一个21g的文件。
[hadoop@wh-8-210 shark]$ hadoop dfs -ls /user/hive/warehouse/log/ Found 1 items -rw-r--r-- 3 hadoop supergroup 22499035249 2014-06-16 18:32 /user/hive/warehouse/log/21gfile
create table log ( c1 string, c2 string, c3 string, c4 string, c5 string, c6 string, c7 string, c8 string, c9 string, c10 string, c11 string, c12 string, c13 string ) row format delimited fields terminated by '\t' stored as textfile;
load data inpath '/user/hive/warehouse/log/21gfile' into table log;
count一下log表:
[10.1.8.210:7100] shark> select count(1) from log > ; 171802086 Time taken (including network latency): 33.753 seconds用时33秒。
将log表全部装在至内存,count一下log_cached:
CREATE TABLE log_cached TBLPROPERTIES ("shark.cache" = "true") AS SELECT * from log;
Time taken (including network latency): 481.96 seconds
shark> select count(1) from log_cached; 171802086 Time taken (including network latency): 6.051 seconds
用时6秒,速度提升了至少5倍。
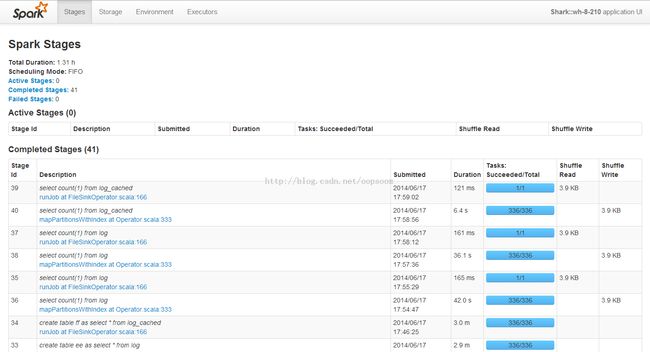
查看Executor以及Task存储状况:
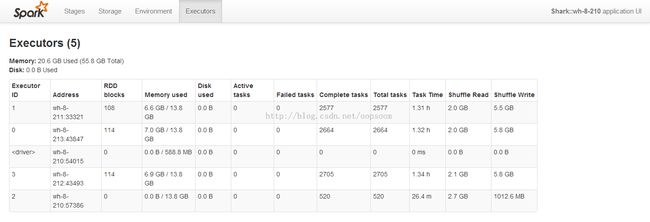
查看存储状况Storage:
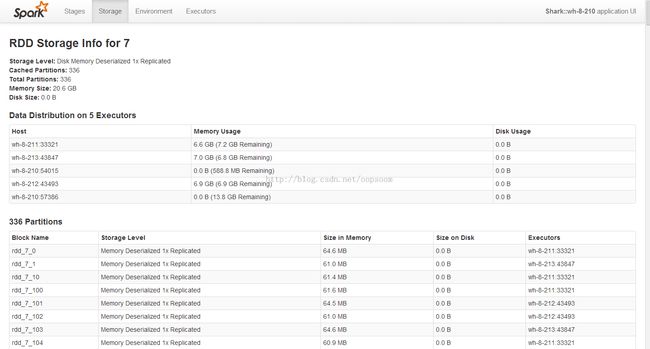
至此,Shark集群搭建和简单的测试已完成。
后续我会写篇环境搭建中常见的问题,以及更详细的Shark测试结论。
注: 原创文章,转载请注明出处,出自:http://blog.csdn.net/oopsoom/article/details/30513929
-EOF-