kmeans算法原理及opencv中的实现
算法的目的:
数据分类,聚类,识别
对象和标准:
输入:n个数据对象
输出:k个类别, 且满足方差最小的k个聚类,聚类方差度量
每个对象与聚类的相似度:一般是采用各个对象到聚类中心(一般是均值中心)的距离,距离哪个中心近,就是与哪个类的相似度高。
聚类的紧密度度量(聚类好坏的度量):所有对象到各自聚类中心的方差和。
基本算法步骤:
初始化:从 n个数据对象任意选择 k 个对象作为初始聚类中心;
迭代:
1. 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行分类;
2. 由新的分类数据,重新计算每个(有变化)聚类的均值(中心对象);
3. 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则循环执行。如opencv中,每次迭代,最大的聚类中心位移max_center_shift < criteria.epsilon小于精度要求时,就结束迭代。以及迭代次数超过设定的最大值时,也结束 iter >= criteria.maxCount。
结束。计算方差,及labels每个对象的分类结果,返回。
算法的时间复杂度上界为O(n*k*t), 其中t是迭代次数。属于非监督学习方法。
OpenCV中增加了参数:
attempts:使用不同的初始化条件,进行分类的次数
flag: KMEANS_RANDOM_CENTERS, KMEANS_PP_CENTERS, KMEANS_USE_INITIAL_LABELS
KMEANS_PP_CENTERS是采用Arthur & Vassilvitskii (2007) k-means++: The Advantages of Careful Seeding获取初始化种子点。
其思想是:
在直觉上,k个初始聚类中心应该远离彼此,所以第一簇中心均匀地选择随机从正在群集的数据点,之后,每个后续的群集中心应该从剩余的数据点中选择,且剩余点:
the remaining data points with probability proportional to its distance squared to the point's closest cluster center.(这句话没理解了)
opencv对新的中心选取,多次尝试,取最好的结果,如下:
ci是随机获取的新的数据中心。
其聚类精度明显优于传统的随机选择种子的方法,且计算速度也比较快。而对于更大型的数据集,kmeans++需要进一步扩展,才能获取更好的表现,即kmeans是高度可扩展的。
数据分类,聚类,识别
对象和标准:
输入:n个数据对象
输出:k个类别, 且满足方差最小的k个聚类,聚类方差度量
每个对象与聚类的相似度:一般是采用各个对象到聚类中心(一般是均值中心)的距离,距离哪个中心近,就是与哪个类的相似度高。
聚类的紧密度度量(聚类好坏的度量):所有对象到各自聚类中心的方差和。
基本算法步骤:
初始化:从 n个数据对象任意选择 k 个对象作为初始聚类中心;
迭代:
1. 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行分类;
2. 由新的分类数据,重新计算每个(有变化)聚类的均值(中心对象);
3. 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则循环执行。如opencv中,每次迭代,最大的聚类中心位移max_center_shift < criteria.epsilon小于精度要求时,就结束迭代。以及迭代次数超过设定的最大值时,也结束 iter >= criteria.maxCount。
结束。计算方差,及labels每个对象的分类结果,返回。
算法的时间复杂度上界为O(n*k*t), 其中t是迭代次数。属于非监督学习方法。
OpenCV中增加了参数:
attempts:使用不同的初始化条件,进行分类的次数
flag: KMEANS_RANDOM_CENTERS, KMEANS_PP_CENTERS, KMEANS_USE_INITIAL_LABELS
增加以上参数的目的,是防止kmeans算法陷入局部最优,即分类的结果不是最好的。局部最优的示例:
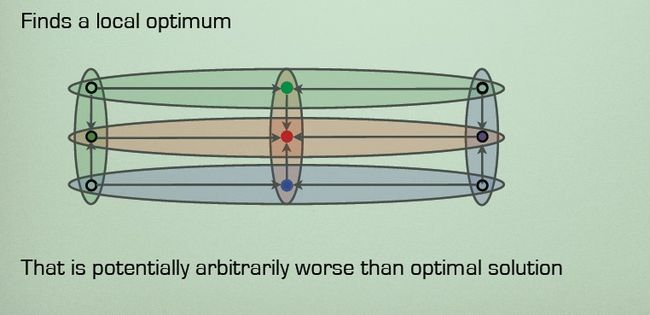
横向分类,纵向分类分别是两种分类结果。显然,横向分类是局部最优。
KMEANS_PP_CENTERS是采用Arthur & Vassilvitskii (2007) k-means++: The Advantages of Careful Seeding获取初始化种子点。
其思想是:
在直觉上,k个初始聚类中心应该远离彼此,所以第一簇中心均匀地选择随机从正在群集的数据点,之后,每个后续的群集中心应该从剩余的数据点中选择,且剩余点:
the remaining data points with probability proportional to its distance squared to the point's closest cluster center.(这句话没理解了)
opencv对新的中心选取,多次尝试,取最好的结果,如下:
ci是随机获取的新的数据中心。
for( k = 1; k < K; k++ ) // k个中心
{
double bestSum = DBL_MAX;
int bestCenter = -1;
for( j = 0; j < trials; j++ ) // 多次尝试,选取最优,trials参数一般选取3
{
double p = (double)rng*sum0, s = 0;
for( i = 0; i < N-1; i++ )
if( (p -= dist[i]) <= 0 )
break; // 上面4行代码,逐行不理解他们的意思。整体看起来意思是随机选取一个新的中心,不知道是否有更深含义?
int ci = i;
for( i = 0; i < N; i++ )
{
tdist2[i] = std::min(distance(data + step*i, data + step*ci, dims), dist[i]); // 新、旧中心距离比较,取小的距离
s += tdist2[i]; // 求和,累加,计算出整体分类的紧密度(聚类的紧密度度量(聚类好坏的度量):所有对象到各自聚类中心的方差和),这里只有新旧两个类中心
}
if( s < bestSum ) // 保存最优结果
{
bestSum = s;
bestCenter = ci;
std::swap(tdist, tdist2);
}
}
centers[k] = bestCenter; // 计算出第k个结果
sum0 = bestSum;
std::swap(dist, tdist);
}
其聚类精度明显优于传统的随机选择种子的方法,且计算速度也比较快。而对于更大型的数据集,kmeans++需要进一步扩展,才能获取更好的表现,即kmeans是高度可扩展的。
KMEANS_USE_INITIAL_LABELS是第一次采用用户自己设置的初始化的中心点进行运算,而后面的尝试则采用随机算法(或半随机)选取的中心。
并查集,用于划分数据,分类的标准是它们在同一个有联系的集合中(或它们的联系能形成一个树):
http://www.cnblogs.com/cherish_yimi/archive/2009/10/11/1580839.html
http://baike.baidu.com/view/521705.htm
Father仅仅是一个 指示 根节点 的数组,father[x]意思是 第x个元素的根节点是 father[x]