Solr III——schema.xml的配置
schema.xml用于定义文档的字段、字段类型以及其他相关信息。以下是一个schema.xml的示例,转自http://blog.csdn.net/jediael_lu/article/details/37937339
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="nutch" version="1.5">
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true"
omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0"
omitNorms="true" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0"
omitNorms="true" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0"
omitNorms="true" positionIncrementGap="0"/>
<fieldType name="text" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="1" catenateNumbers="1" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="url" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"/>
</analyzer>
</fieldType>
</types>
<fields>
<field name="id" type="string" stored="true" indexed="true"/>
<!-- core fields -->
<field name="batchId" type="string" stored="true" indexed="false"/>
<field name="digest" type="string" stored="true" indexed="false"/>
<field name="boost" type="float" stored="true" indexed="false"/>
<!-- fields for index-basic plugin -->
<field name="host" type="url" stored="false" indexed="true"/>
<field name="url" type="url" stored="true" indexed="true"
required="true"/>
<field name="content" type="text" stored="false" indexed="true"/>
<field name="title" type="text" stored="true" indexed="true"/>
<field name="cache" type="string" stored="true" indexed="false"/>
<field name="tstamp" type="date" stored="true" indexed="false"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
<!-- fields for index-anchor plugin -->
<field name="anchor" type="string" stored="true" indexed="true"
multiValued="true"/>
<!-- fields for index-more plugin -->
<field name="type" type="string" stored="true" indexed="true"
multiValued="true"/>
<field name="contentLength" type="long" stored="true"
indexed="false"/>
<field name="lastModified" type="date" stored="true"
indexed="false"/>
<field name="date" type="date" stored="true" indexed="true"/>
<!-- fields for languageidentifier plugin -->
<field name="lang" type="string" stored="true" indexed="true"/>
<!-- fields for subcollection plugin -->
<field name="subcollection" type="string" stored="true"
indexed="true" multiValued="true"/>
<!-- fields for feed plugin (tag is also used by microformats-reltag)-->
<field name="author" type="string" stored="true" indexed="true"/>
<field name="tag" type="string" stored="true" indexed="true" multiValued="true"/>
<field name="feed" type="string" stored="true" indexed="true"/>
<field name="publishedDate" type="date" stored="true"
indexed="true"/>
<field name="updatedDate" type="date" stored="true"
indexed="true"/>
<!-- fields for creativecommons plugin -->
<field name="cc" type="string" stored="true" indexed="true"
multiValued="true"/>
<!-- fields for tld plugin -->
<field name="tld" type="string" stored="false" indexed="false"/>
</fields>
<uniqueKey>id</uniqueKey>
<defaultSearchField>content</defaultSearchField>
<solrQueryParser defaultOperator="OR"/>
</schema>
在schema.xml的内容,共分为六个主要部分。分别是:field、copyField、fieldType、uniqueKey、defaultSearchField、solrQueryParser。下面一一介绍这六块内容。
field
field是用来定义具体的字段的信息的。一个field标签的示例如下:
<field name="tag" type="string" stored="true" indexed="true" multiValued="true"/>
field标签中的各个属性说明如下表所示:
|
属性名称
|
说明
|
|
name
|
字段的名称
|
|
type
|
字段的类型,该类型需要在fieldType元素中定义,具体定义方法参见本文对fieldType的定义
|
|
stored
|
该属性代表该字段的值是否会被存储。未被存储的话,在查询的时候是不会显示出来的。假设现在有一个叫user的core,其中包含name、age、birthday三个字段。其中,birthday的stored属性为false。则查询所有user信息的时候,只有name、age这两个字段的值会被显示出来,而查询结果是不会显示birthday字段的。
|
|
indexed
|
该属性代表该字段是否可以用于索引。若为true,则在条件查询时,可以以该字段为查询条件。例如,假设现在有条数据,其name字段的值是tom。若indexed属性为true,则在查询时,可以通过q=name:tom的查询条件查到该条数据。若indexed为false,即便这条name值是tom是确实存在的,但通过q=name:tom的查询条件也查不到该条数据。 另外还需注意的是,如果该字段可能被用于排序、分组等操作,indexed属性也需要是true |
|
multiValued
|
若一个字段中可能会存储多个值,则该属性需要为true
|
|
required
|
该属性代表非空。
|
copyField
在以下两种情况下,建议使用copyField:
1.将多个字段复制到一个单一的字段中,方便搜索;
2.对同一个字段进行多次不同的分析处理;
在这里,由于我目前只对第一条有些许的了解,故只说第一条。copyField例:
<field name="name" type="string" indexed="true" stored="true"/> <field name="identityID" type="string" indexed="true" stored="true"/> <field name="text" type="string" indexed="true" stored="false" multiValued="true"/> 略…… <copyField source="name" dest="text"/> <copyField source="identityID" dest="text"/>
在本例中,分别有三个字段:name、identityID、text。前两者是实际需要的字段,但是text字段并非用于存储实际值,而是将name、identityID字段的值生成索引,以供查询。若不创建text这个字段。如果想查一条name=tom、identityID=123xxx的数据的话,查询条件应该这么写:name:tom AND identityID:123xxx。在搜索的时候,会反复轮询两遍全部数据,并从中晒出符合条件的记录。但是如果通过copyField字段将这两个字段的值复制过来并生成索引,再做同样的查询的时候,只需要对text进行查询就可以了。
fieldType
一个常见的fieldType配置如下所示:
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
name属性就是给fieldType的名称,也是<field>标签中type属性应该填的值。
class属性是该类型对应的java类。class值以solr开始的,是个简写,代表着org.appache.solr.analysis包。
sortMissingLast属性和sortMissingFirst属性是一对相对应的属性,当sortMissingLast为true时,代表若某条数据的该字段没有值时,在排序时该条数据应该排在所有该字段有值的数据之后。sortMissingFirst则与之想法,应该排在最前面。这两个属性的默认值都是false。
在fieldType中还可以配置分词器,在这里只介绍如何配置中文的分词器。目前常见的分词器中,mmseg4j和ik-analyzer这两个分词器比较常见,在本文中只介绍如何配置mmseg4j。
mmseg4j的版本应该是与solr版本有比较严格的对应关系的,如果版本不符合要求,则会报错,但是这一点我并没有亲自验证过。
本文中用到的solr版本是4.10.4。用到的mmseg4j相关的jar包的版本为
:
mmseg4j-analysis-1.9.1.jar、mmseg4j-core-1.9.1.jar、mmseg4j-solr-2.2.0.jar。只要是solr4.10.x都可以通用我所提到的这些mmseg4j JAR包。
首先下载与Solr4.10匹配的mmseg4j JAR包,URL:http://download.csdn.net/detail/u010997403/9111515
然后将mmseg4j-analysis-1.9.1.jar、mmseg4j-core-1.9.1.jar、mmseg4j-solr-2.2.0.jar这三个jar包全部拷贝到tomcat中的solr/WEB-INF/lib中。
之后配置schema.xml。配置的代码如下所示:
<field name="content" type="text_zh" indexed="true" stored="true" multiValued="true"/> 略…… <fieldType name="text_zh" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex"/> </analyzer> </fieldType>配置完成后,就可以重启solr服务器,向该字段中添加值了。首先先来看一眼经过该分词器分词的效果:
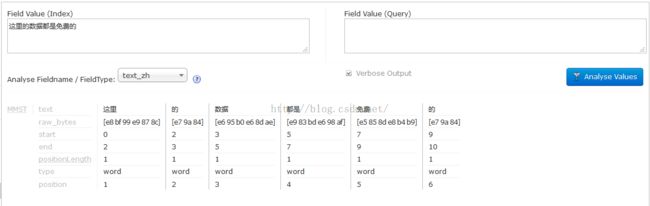
由图中可见,分词效果还是比较理想的。那么现在,就把“这里的数据都是免费的”这句话存入索引中,通过条件查询来看一下分词的效果。
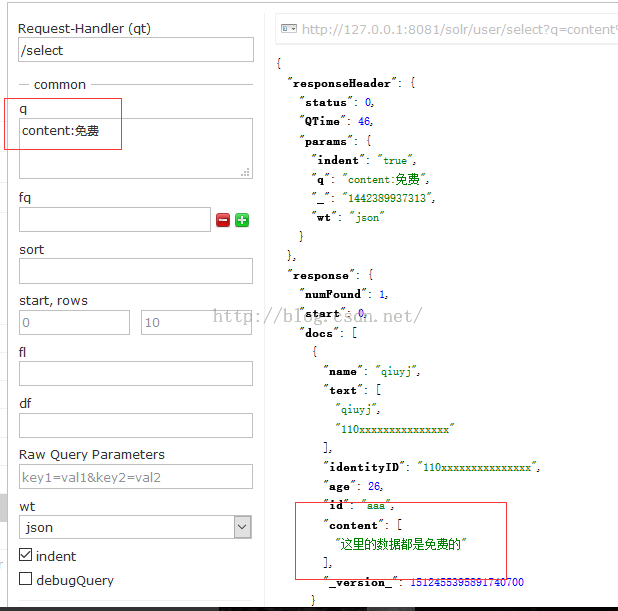
从查询结果可以看出,虽然查询的时候并没有用到模糊搜索,但是也能通过“免费”这个词把一整条数据都给查出来。