sparkSQL1.1入门之八:sparkSQL之综合应用
Spark之所以万人瞩目,除了内存计算,还有其ALL-IN-ONE的特性,实现了One stack rule them all。下面简单模拟了几个综合应用场景,不仅使用了sparkSQL,还使用了其他Spark组件:
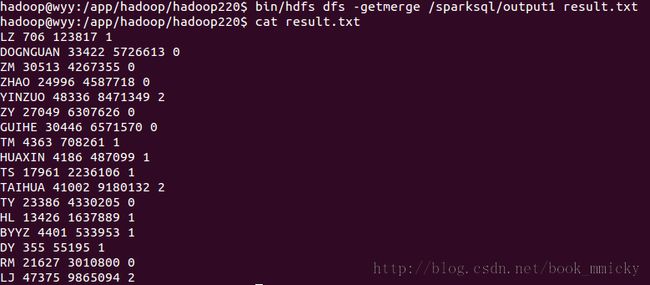
运行完毕,使用getmerge将结果转到本地文件,并查看结果:
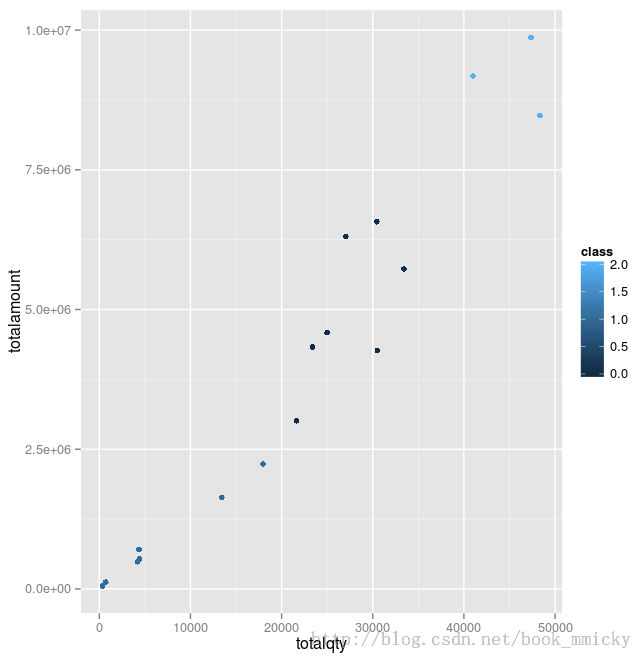
最后使用R做示意图,用3种不同的颜色表示不同的类别。

- 店铺分类,根据销售额对店铺分类,使用sparkSQL和MLLib
- PageRank,计算最有价值的网页,使用sparkSQL和GraphX
前者将使用sparkSQL+MLlib的聚类算法,后者将使用sparkSQL+GraphX的PageRank算法。本实验采用IntelliJ IDEA调试代码,最后生成doc.jar,然后使用spark-submit提交给集群运行。
1:店铺分类
分类在实际应用中非常普遍,比如对客户进行分类、对店铺进行分类等等,对不同类别采取不同的策略,可以有效的降低企业的营运成本、增加收入。机器学习中的聚类就是一种根据不同的特征数据,结合用户指定的类别数量,将数据分成几个类的方法。下面举个简单的例子,对第五小结中的hive数据,按照销售数量和销售金额这两个特征数据,进行聚类,分出3个等级的店铺。
在IDEA中建立一个object:SQLMLlib
package doc
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.catalyst.expressions.Row
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
object SQLMLlib {
def main(args: Array[String]) {
//屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//设置运行环境
val sparkConf = new SparkConf().setAppName("SQLMLlib")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
//使用sparksql查出每个店的销售数量和金额
hiveContext.sql("use saledata")
hiveContext.sql("SET spark.sql.shuffle.partitions=20")
val sqldata = hiveContext.sql("select a.locationid, sum(b.qty) totalqty,sum(b.amount) totalamount from tblStock a join tblstockdetail b on a.ordernumber=b.ordernumber group by a.locationid")
//将查询数据转换成向量
val parsedData = sqldata.map {
case Row(_, totalqty, totalamount) =>
val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
Vectors.dense(features)
}
//对数据集聚类,3个类,20次迭代,形成数据模型
//注意这里会使用设置的partition数20
val numClusters = 3
val numIterations = 20
val model = KMeans.train(parsedData, numClusters, numIterations)
//用模型对读入的数据进行分类,并输出
//由于partition没设置,输出为200个小文件,可以使用bin/hdfs dfs -getmerge 合并下载到本地
val result2 = sqldata.map {
case Row(locationid, totalqty, totalamount) =>
val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
val linevectore = Vectors.dense(features)
val prediction = model.predict(linevectore)
locationid + " " + totalqty + " " + totalamount + " " + prediction
}.saveAsTextFile(args(0))
sc.stop()
}
}编译打包后,复制到spark安装目录下运行:
cp /home/mmicky/IdeaProjects/doc/out/artifacts/doc/doc.jar . bin/spark-submit --master spark://hadoop1:7077 --executor-memory 3g --class doc.SQLMLlib doc.jar /sparksql/output1
运行过程,可以发现聚类过程都是使用20个partition:
bin/hdfs dfs -getmerge /sparksql/output1 result.txt
2:PageRank
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名,是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法。目前很多重要的链接分析算法都是在PageRank算法基础上衍生出来的。PageRank是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。在揉合了诸如Title标识和Keywords标识等所有其它因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中令网站排名获得提升,从而提高搜索结果的相关性和质量。
Spark GraphX引入了google公司的图处理引擎pregel,可以方便的实现PageRank的计算。下面实例采用的数据是wiki数据中含有Berkeley标题的网页之间连接关系,该数据集已经经过ETL,最终为两个文件:graphx-wiki-vertices.txt和graphx-wiki-edges.txt ,可以分别用于图计算的顶点和边。
首先,启动bin/spark-sql,将这两个文件定义为表:
//启动spark-sql,运行下列语句创建表 CREATE TABLE vertices(ID BigInt,Title String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA INPATH '/sparksql/graphx-wiki-vertices.txt' INTO TABLE vertices; CREATE TABLE edges(SRCID BigInt,DISTID BigInt) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA INPATH '/sparksql/graphx-wiki-edges.txt' INTO TABLE edges;
然后,在IDEA中建立一个object:SQLGraphX
package doc
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.graphx._
import org.apache.spark.sql.catalyst.expressions.Row
object SQLGraphX {
def main(args: Array[String]) {
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//设置运行环境
val sparkConf = new SparkConf().setAppName("PageRank").setMaster("local")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
//使用sparksql查出每个店的销售数量和金额
hiveContext.sql("use saledata")
val verticesdata = hiveContext.sql("select id, title from vertices")
val edgesdata = hiveContext.sql("select srcid,distid from edges")
//装载顶点和边
val vertices = verticesdata.map { case Row(id, title) => (id.toString.toLong, title.toString)}
val edges = edgesdata.map { case Row(srcid, distid) => Edge(srcid.toString.toLong, distid.toString.toLong, 0)}
//构建图
val graph = Graph(vertices, edges, "").persist()
//pageRank算法里面的时候使用了cache(),故前面persist的时候只能使用MEMORY_ONLY
println("**********************************************************")
println("PageRank计算,获取最有价值的数据")
println("**********************************************************")
val prGraph = graph.pageRank(0.001).cache()
val titleAndPrGraph = graph.outerJoinVertices(prGraph.vertices) {
(v, title, rank) => (rank.getOrElse(0.0), title)
}
titleAndPrGraph.vertices.top(10) {
Ordering.by((entry: (VertexId, (Double, String))) => entry._2._1)
}.foreach(t => println(t._2._2 + ": " + t._2._1))
sc.stop()
}
}
编译打包后,复制到spark安装目录下运行:
cp /home/mmicky/IdeaProjects/doc/out/artifacts/doc/doc.jar . bin/spark-submit --master spark://hadoop1:7077 --executor-memory 3g --class doc.SQLGraphX doc.jar
运行结果:
3:小结
在现实数据处理过程中,这种涉及多个系统处理的场景很多。通常各个系统之间的数据通过磁盘落地再交给下一个处理系统进行处理。对于Spark来说,通过多个组件的配合,可以以流水线的方式来处理数据。从上面的代码可以看出,程序除了最后有磁盘落地外,都是在内存中计算的。避免了多个系统中交互数据的落地过程,提高了效率。这才是spark生态系统真正强大之处:One stack rule them all。另外sparkSQL+sparkStreaming可以架构当前非常热门的Lambda架构体系,为CEP提供解决方案。也正是如此强大,才吸引了广大开源爱好者的目光,促进了spark生态的高速发展。