程序员面试题精选100题(49)-复杂链表的复制
题目:有一个复杂链表,其结点除了有一个m_pNext指针指向下一个结点外,还有一个m_pSibling指向链表中的任一结点或者NULL。其结点的C++定义如下:
struct ComplexNode
{
int m_nValue;
ComplexNode* m_pNext;
ComplexNode* m_pSibling;
};
下图是一个含有5个结点的该类型复杂链表。图中实线箭头表示m_pNext指针,虚线箭头表示m_pSibling指针。为简单起见,指向NULL的指针没有画出。
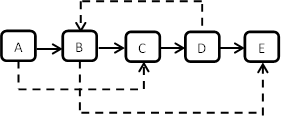
请完成函数 ComplexNode* Clone(ComplexNode* pHead) ,以复制一个复杂链表。
看到这个问题,我的第一反应是分成两步:第一步是复制原始链表上的每个链表,并用m_pNext链接起来。第二步,假设原始链表中的某节点N的m_pSibling指向结点S。由于S的位置在链表上有可能在N的前面也可能在N的后面,所以要定位N的位置我们需要从原始链表的头结点开始找。假设从原始链表的头结点开始经过s步找到结点S。那么在复制链表上结点N的m_pSibling的S’,离复制链表的头结点的距离也是s。用这种办法我们就能为复制链表上的每个结点设置m_pSibling了。
对一个含有n个结点的链表,由于定位每个结点的m_pSibling,都需要从链表头结点开始经过O(n)步才能找到,因此这种方法的总时间复杂度是O(n2)。
由于上述方法的时间主要花费在定位结点的m_pSibling上面,我们试着在这方面去做优化。我们还是分为两步:第一步仍然是复制原始链表上的每个结点N,并创建N’,然后把这些创建出来的结点链接起来。这里我们对<N,N’>的配对信息放到一个哈希表中。第二步还是设置复制链表上每个结点的m_pSibling。如果在原始链表中结点N的m_pSibling指向结点S,那么在复制链表中,对应的N’应该指向S’。由于有了哈希表,我们可以用O(1)的时间根据S找到S’。
第二种方法相当于用空间换时间,以O(n)的空间消耗实现了O(n)的时间效率。
第二种方法的简单代码为:#include<map>
#include<string>
using namespace std;
struct node
{
int data;
node* next;
node* link;
bool operator==(const node& temp) const
{
return (data==temp.data)&&(next==temp.next)&&(link==temp.link)
}
bool operator>(const node& temp) const
{
return data>temp.data;
}
bool operator<(const node& temp) const
{
return data<temp.data;
}
};
node* copyLink(node* p,map<node,node> *a)
{
node* temp=p;
node *t2=new node();
node* headNode=t2;
t2->data=temp->data;
a->insert(make_pair(*temp,*t2));
while(temp->next!=NULL)
{
temp=temp->next;
node* nodetemp=new node();
nodetemp->data=temp->data;
t2->next=nodetemp;
t2=t2->next;
a->insert(make_pair(*temp,*t2));
}
t2->next=NULL;
return headNode;
}
node* createLink()
{
node *p[5]={NULL,NULL,NULL,NULL,NULL};
node* head=new node();
head->data=0;
p[0]=head;
node *temp=head;
for(int i=1;i<5;i++)
{
node* t2=new node();
t2->data=i;
p[i]=t2;
temp->next=t2;
temp=t2;
}
temp->next=NULL;
p[2]->link=p[4];
p[3]->link=p[0];
p[0]->link=NULL;
p[1]->link=NULL;
p[4]->link=NULL;
return head;
}
int main()
{
map<node,node> *a=new map<node,node>();
node *p=createLink();
node *q=copyLink(p,a);
node *temp=p;
node *temp2=q;
while(temp!=NULL)
{
node *link=temp->link;
if(link==NULL)
temp2->link=NULL;
else
temp2->link=&(a->find(*link)->second);
temp=temp->next;
temp2=temp2->next;
}
node *t3=q;
for(;t3!=NULL;t3=t3->next)
{
std::cout<<t3->data<<",";
if(t3->link==NULL)
cout<<""<<endl;
else
cout<<t3->link->data<<endl;
}
system("pause");
}
接着我们来换一种思路,在不用辅助空间的情况下实现O(n)的时间效率。第三种方法的第一步仍然是根据原始链表的每个结点N,创建对应的N’。这一次,我们把N’链接在N的后面。实例中的链表经过这一步之后变成了:

这一步的代码如下:
/////////////////////////////////////////////////////////////////////////////////
// Clone all nodes in a complex linked list with head pHead,
// and connect all nodes with m_pNext link
/////////////////////////////////////////////////////////////////////////////////
void CloneNodes(ComplexNode* pHead)
{
ComplexNode* pNode = pHead;
while(pNode != NULL)
{
ComplexNode* pCloned = new ComplexNode();
pCloned->m_nValue = pNode->m_nValue;
pCloned->m_pNext = pNode->m_pNext;
pCloned->m_pSibling = NULL;
pNode->m_pNext = pCloned;
pNode = pCloned->m_pNext;
}
}
第二步是设置我们复制出来的链表上的结点的m_pSibling。假设原始链表上的N的m_pSibling指向结点S,那么其对应复制出来的N’是N->m_pNext,同样S’也是S->m_pNext。这就是我们在上一步中把每个结点复制出来的结点链接在原始结点后面的原因。有了这样的链接方式,我们就能在O(1)中就能找到每个结点的m_pSibling了。例子中的链表经过这一步,就变成如下结构了:
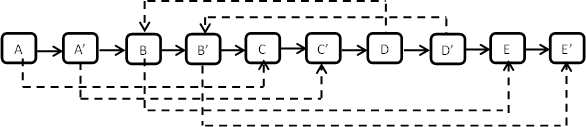
这一步的代码如下:
/////////////////////////////////////////////////////////////////////////////////
// Connect sibling nodes in a complex link list
/////////////////////////////////////////////////////////////////////////////////
void ConnectSiblingNodes(ComplexNode* pHead)
{
ComplexNode* pNode = pHead;
while(pNode != NULL)
{
ComplexNode* pCloned = pNode->m_pNext;
if(pNode->m_pSibling != NULL)
{
pCloned->m_pSibling = pNode->m_pSibling->m_pNext;
}
pNode = pCloned->m_pNext;
}
}
第三步是把这个长链表拆分成两个:把奇数位置的结点链接起来就是原始链表,把偶数位置的结点链接出来就是复制出来的链表。上述例子中的链表拆分之后的两个链表如下:

要实现这一步,也不是很难的事情。其对应的代码如下:
/////////////////////////////////////////////////////////////////////////////////
// Split a complex list into two:
// Reconnect nodes to get the original list, and its cloned list
/////////////////////////////////////////////////////////////////////////////////
ComplexNode* ReconnectNodes(ComplexNode* pHead)
{
ComplexNode* pNode = pHead;
ComplexNode* pClonedHead = NULL;
ComplexNode* pClonedNode = NULL;
if(pNode != NULL)
{
pClonedHead = pClonedNode = pNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode = pNode->m_pNext;
}
while(pNode != NULL)
{
pClonedNode->m_pNext = pNode->m_pNext;
pClonedNode = pClonedNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode = pNode->m_pNext;
}
return pClonedHead;
}
我们把上面三步合起来,就是复制链表的完整过程:
/////////////////////////////////////////////////////////////////////////////////
// Clone a complex linked list with head pHead
/////////////////////////////////////////////////////////////////////////////////
ComplexNode* Clone(ComplexNode* pHead)
{
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
return ReconnectNodes(pHead);
}