利用BeatifulSoup包学习爬虫,抓取《今晚看啥》电影评分和标签
最近,突然有想学习下爬虫,其实,在当初看《集体智慧编程》的时候,就接触过爬虫,只不过没怎么深入学习python下工具包:BeatifulSoup。这个包主要用来解析html和xml文件。我们做爬虫主要是就是为了抓取网页中我们需要的信息,利用BeatifulSoup,我们可以很快的解析网页文件,获取网页中我们需要的信息。实际案例,我以百度旗下《今晚看啥》网站为例,抓取电影评分,标签,作者,标题等等。
其中电影阿甘正传的网址:http://kansha.baidu.com/movie/1054。
电影基本信息如下:

这幅图,中我们得到了电影的标题,导演,演员,国家,豆瓣,IMDb评分。
在下面的图,我们知道网友的评分:
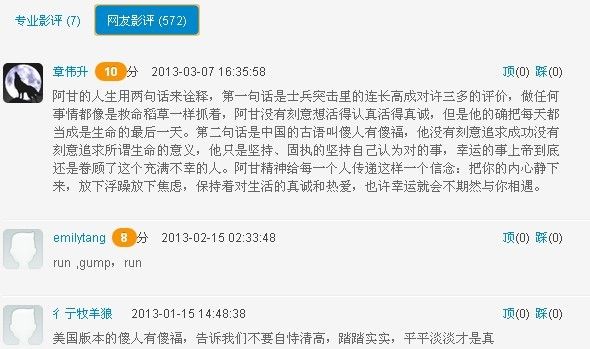
这些信息,就是我们要抓取的信息。
我们根据url,抓取网页信息,通过BeatifulSoup包来解析。值得提的是:网页评论部分,有上下页切换,我们点击切换的时候,url并没有改变。但是,你仔细分析下网页源码,你会发现,其实有个地方是系统隐藏了。实际url:http://kansha.baidu.com/movie/1054?up=n,n表示页数。
下面,我贴出,写的抓取代码:
import urllib2
import string
import re
from BeautifulSoup import BeautifulSoup
# get a movie review score by users;
def get_user_review_score(movie_id):
base_url = 'http://kansha.baidu.com/movie/'
suffix_url = 'http://kansha.baidu.com/movie/' + str(movie_id) + '?up='
raw_url = 'http://kansha.baidu.com/movie/' + str(movie_id)
user_scores = []
try:
c = urllib2.urlopen(raw_url)
except:
print 'can not open this webpage...'
return None
s = BeautifulSoup(c.read())
pages = s.find('a',{"class":"last hidden"})['href'].split('=')[1]
pages = string.atoi(pages)
for i in range(1,pages+1):
url = "%s%d"%(suffix_url,i)
try:
c = urllib2.urlopen(url)
except:
print 'can not open this webpage...'
return None
s = BeautifulSoup(c.read())
review = s.findAll('div',{"class" : "user-review-wide"})
for e in review:
if e.a['href'] != '#' and e.find(attrs = {"class" : "badge badge-warning"}) != None:
print e.a
print e.span.contents[0]
user_id = e.a['href'].split("/")[2]
score_by_user = string.atoi(str(e.span.contents[0]))
user_scores.append((user_id, score_by_user))
print "The %d page"%i
print "crawering is end..."
print user_scores
return user_scores
# tag : directors ,actors, gen_labels, country, douban_review, IMDb_review ;
def get_tags_movie(movie_id):
raw_url = 'http://kansha.baidu.com/movie/' + str(movie_id)
try:
c = urllib2.urlopen(raw_url)
except:
print 'can not open this webpage...'
return None
s = BeautifulSoup(c.read())
directors = s.findAll('a',{'class': 'label label-director normal-tooltip'})
actors = s.findAll('a',{'class': 'label label-actor normal-tooltip'})
genome = s.findAll('a',{'class': 'label label-genome normal-tooltip'})
country = s.findAll('a',{'class': 'label label-country normal-tooltip'})
Douban = s.find(text = u'\u8c46\u74e3')
Douban_score = Douban.next.next.contents
IMDb = s.find(text= 'IMDb')
IMDb_score = IMDb.next.next.contents
print directors,actors,genome,country,[Douban_score, IMDb_score]
directors_names = [elem.contents for elem in directors]
actors_names = [elem.contents for elem in actors]
genome_names = [elem.contents for elem in genome]
country_names = [elem.contents for elem in country]
return [ directors_names, actors_names,genome_names,country_names,[Douban_score,IMDb_score]]
def get_movie_tile(movie_id):
raw_url = 'http://kansha.baidu.com/movie/' + str(movie_id)
try:
c = urllib2.urlopen(raw_url)
except:
print 'can not open this webpage...'
return None
s = BeautifulSoup(c.read())
movie_title = str(s.title.contents).replace(" "," ")
print movie_title
return movie_title
上面主要涉及三个函数:第一个是抓取网友评分:(user_id, score),第二个是抓取电影标签,豆瓣,IMDb的评分,第三个:电影标题。
最后,我想说明下,其实上面的工作很简单,用的也只是BeautifulSoup包里面一小部分东西,并且是针对静态网页来做的。我们知道,现在很多网页里面穿插着js部分,需要模拟一个浏览器行为,才能网页信息。对于,这部分工作,暂时,还没涉及,据说,好像有个工具叫webkit,可以解决这样的问题。这部分工作,留在以后再做吧。