【机器学习基础】梯度提升决策树
引言
上一节中介绍了《随机森林算法》,该算法使用bagging的方式作出一些决策树来,同时在决策树的学习过程中加入了更多的随机因素。该模型可以自动做到验证过程同时还可以进行特征选择。
这一节,我们将决策树和AdaBoost算法结合起来,在AdaBoost中每一轮迭代,都会给数据更新一个权重,利用这个权重,我们学习得到一个g,在这里我们得到一个决策树,最终利用线性组合的方式得到多个决策树组成的G。

1. 加权的决策树算法(Weighted Decision Tree Algorithm)
在引言中介绍了,我们利用AdaBoost的思想,为数据赋予不同的权重,而在将要介绍的Adaptive Boosted Decision Tree中,要建立加权的决策树,所以接下来就要介绍它。
在之前含有权重的算法中,权重作为衡量数据重要性的一项指标,用来评估训练误差,如下面的公式所示:
![]()
上面的公式中,权重是包含在误差的公式中的,也就是说,我们想要构造一个带有权重的决策树算法,需要改造决策树的误差度量函数。然而换一个角度,权重也可以等效于数据的重复次数,重复次数越多的数据,说明其越重要。在广义的随机算法中,我们可以根据权重比例来进行随机采样(比如,如果权重比例是30%,那么采样该数据的概率就是30%),根据这种方式得到一组新的数据,那么这组新的数据中的比例大概就是和权重的比例呈正比的,也就是说它能够表达权重对于数据的意义。

在AdaBoost-DTree中,为了简单起见,我们不去改变AdaBoost的框架,也不去修改决策树的内部细节,而只是通过基于权重的训练数据的采样来实现。

1.1 弱决策树算法
在AdaBoost算法中,我们通过错误率εt来计算单个的g的权重αt,那么如果我们使用决策树作为g的时候,g是一个完全长成的树,该树对整个数据集进行细致的切分导致Ein=0,那么这使得εt=0,但计算得到的权重αt会变成无限大。
其意义是,如果使用一个能力很强的树作为g的话,那么该算法会赋予该树无限大的权重或票数,最终得到了一棵“独裁”的树(因为AdaBoost的哲学意义是庶民政治,就是集中多方的意见,及时有的意见可能是错误的),违背了AdaBoost的宗旨。

上面的问题出在使用了所有的数据和让树完全长成这两方面。针对这两个问题,我们要通过剪枝和部分训练数据得到一个弱一点的树。
所以实际上,AdaBoost-DTree是通过sampling的方式得到部分训练数据,通过剪枝的方式限制树的高度,得到弱一点的决策树。
![]()
1.2 AdaBoost-Stump
什么样是树才是弱决策树呢?
我们这里限制这棵树只有一层,即决策桩(Decision Stump)。这样我们需要让CART树的不纯度(impurity)尽可能低,学习一个决策桩。

所以,使用决策桩作为弱分类器的AdaBoost称为AdaBoost-Stump,它是一种特殊的AdaBoost-DTree。
2. AdaBoost深入解释和最佳化
我们回顾一下AdaBoost算法流程:

其中权重un(t+1)通过◆t对un(t)进行修正得到,由于◆t是一个大于1的数,对错误数据加大权重以让算法更加重视错分的数据。
我们可以用下面的方式来描述un(t+1):

下面的公式是我们将un(T+1)展开,我们看到图中橘色的部分∑αt·gt(xn)是G(x)中的分数,它出现在AdaBoost的权重的表达式中,我们称∑αt·gt(xn)为投票分数(voting score)。

所以,AdaBoost里面每一个数据的权重,和exp(-yn(voting score on xn))呈正比。
![]()
2.1 投票分数(Voting Score)和间隔(Margin)的关系
线性混合(linear blending)等价于将假设看做是特征转换的线性模型:

其中αt·gt(xn)如果换作是wT·φ(xn)可能就更清楚了,这与下面给出的在SVM中的margin表达式对比,我们可以明白投票分数∑αt·gt(xn)的物理意义,即可以看做是没有正规化的边界(margin)。
![]()
所以,yn(voting score)是有符号的、没有正规化的边界距离,从这个角度来说,我们希望yn(voting score)越大越好,因为这样的泛化能力越强。于是,exp(-yn(voting score))越小越好,那么un(T+1)越小越好。

AdaBoost在迭代过程中,是让∑un(t)越来越小的过程,在这个过程中,逐渐达到SVM中最大分类间隔的效果。
2.2 AdaBoost误差函数
上面解释到了,AdaBoost在迭代学习的过程,就是希望让∑un(t)越来越小的过程,那么我们新的目标就是最佳化∑un(T+1):

我们可以画出0/1错误和AdaBoost误差函数err(s,y) = exp(-ys)的函数曲线,我们发现AdaBoost的误差函数(称为exponential error measure)实际上也是0/1错误函数的上限函数,于是,我们可以通过最小化该函数来起到最佳化的效果。

2.3 AdaBoost误差函数的梯度下降求解
为了最小化AdaBoost的误差函数Ein,我们可以将Ein函数在所在点的附近做泰勒展开,我们就可以发现在该点的附近可以被梯度所描述,我们希望求一个最好的方向(最大梯度相反的方向),然后在该方向上走一小步,这样我们就可以做到比现在的函数效果好一点点,依次进行梯度下降,最终达到最小化误差函数的效果。
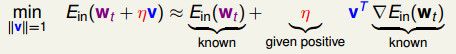
现在我们把gt当做方向,希望去找到这个gt(这里函数方向gt和上面介绍的最大梯度的方向向量没有什么差别,只是表示方式有所不同而已)。
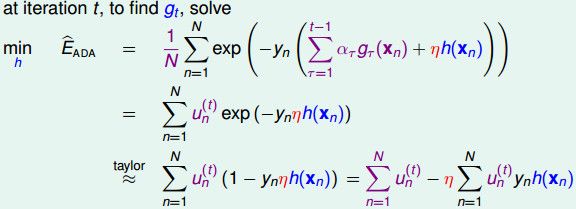
我们解释一下上面的公式:
- 我们需要找到一个新的函数,这里表示为h(xn)和步长η,将这个函数加入到表达式中去;
- 我们将第一个公式中紫色的部分合起来,简化表示为权重un(t);
- 将
exp(-y·η·h(xn))在原点处做泰勒展开,得到(1-yn·η·h(xn));- 然后拆成两部分
∑un(t)和η·∑un(t)·yn·h(xn),第一部分是Ein,第二部分就是要最小化的目标。
我们对∑un(t)·yn·h(xn)整理一下,对于二元分类情形,我们把yn和h(xn)是否同号进行分别讨论:

上面的公式中,我们特意将∑un(t)·yn·h(xn)拆成-∑un(t)和Ein(h)的形式,这里最小化Ein对应于AdaBoost中的A(弱学习算法),好的弱学习算法就是对应于梯度下降的函数方向。
2.4 最佳化步长η
我们要最小化Eada,需要找到好的函数方向gt,但是得打这个gt的代价有些大,梯度下降的过程中,每走一小步,就需要计算得到一个gt。如果转换一下思路,我们现在已经确定了好的gt,我们希望快速找到梯度下降的最低点,那么我们需要找到一个合适的最大步长η。
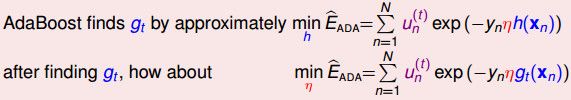
我们这里使用贪心算法来得到最大步长η,称为steepest decent for optimization。

让Eada对η求偏微分,得到最陡时候的ηt,我们发现这时ηt等于AdaBoost的αt。所以在AdaBoost中αt是在偷偷地做最佳化的工作。
2.5 小结
在第二小节中,我们从另外一个角度介绍了AdaBoost算法,它其实是steepest gradient decent。
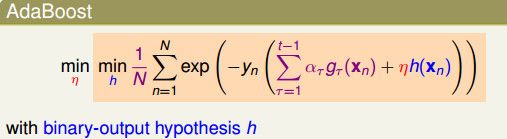
上面的式子很清楚了,我们将AdaBoost的误差函数看做是指数误差函数,AdaBoost就是在这个函数上一步一步做最佳化,每一步求得一个h,并将该h当做是gt,决定这个gt上面要走多长的距离ηt,最终得到这个gt的票数αt。
3. 梯度提升(Gradient Boosting)
梯度提升是对AdaBoost的延伸,它不再要求误差函数是指数误差函数,而可能是任意一种误差函数(因为这里是用梯度下降法来最佳化误差函数,所以这里要求误差函数是平滑的)。
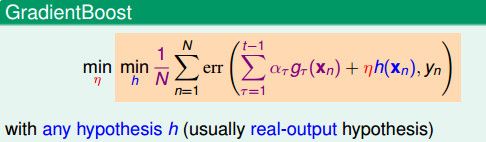
在这个架构下,我们就可以使用不同的假设和模型,来解决分类或者回归的问题。
3.1 梯度提升应用于回归问题
梯度提升应用于回归问题时,误差函数选中均方误差函数。

紧接着,我们对这个误差函数中变量s在sn处进行一阶泰勒展开的近似,我们发现要最小化的实际是∑h(xn)·2(sn-yn),要让该表达式最小,需要h(xn)和(sn-yn)的方向相反:

要求解最佳化问题,需要h(xn)和(sn-yn)的方向相反,而h(xn)的大小其实不是我们关系的问题,因为步长问题是由参数η决定的。
如果将h(xn)强制限制为1或者某个常数的话,那么就得到了一个有条件的最佳化问题,增加了求解的难度。不如我们将惩罚项h(xn)的平方放进最佳化式子中(意思是,如果h(xn)越大,我们就越不希望如此)。
我们可以将平方式子变换一下,得到有关(h(xn)-(yn-sn))^2的式子,所以我们要求一个带惩罚项的近似函数梯度的问题,就等效于求xn和余数(residual)yn-sn的回归问题。

确定步长η:

我们现在确定了gt,接着我们要确定步长η,这里我们可以将误差函数写成余数(yn-sn)的形式,这是一个单变量的线性回归问题,其中输入是用gt转换后的数据,输出是余数(residual)。

4. 梯度提升决策树
综合第三小节的步骤,我们就可以得到梯度提升决策树的算法流程:

- 在每一次迭代过程,解决一个回归问题,这里可以用CART算法来解{xn, (yn-sn)}的回归问题;
- 然后,用gt做转换,做一个{gt(xn), yn-sn}的单变量线性回归问题;
- 更新分数sn;
- 经过T轮迭代,得到G(x)。
这个GBDT算法可以看做是AdaBoost-DTree的回归问题版本。
参考资料
机器学习技法课程,林轩田,台湾大学
决策树模型组合之随机森林与GBDT
机器学习——Gradient Boost Decision Tree(&Treelink)
转载请注明作者Jason Ding及其出处
GitCafe博客主页(http://jasonding1354.gitcafe.io/)
Github博客主页(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
简书主页(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)
Google搜索jasonding1354进入我的博客主页