The Suspects POJ1611
| Time Limit: 1000MS | Memory Limit: 20000K | |
| Total Submissions: 13311 | Accepted: 6297 |
Description
In the Not-Spreading-Your-Sickness University (NSYSU), there are many student groups. Students in the same group intercommunicate with each other frequently, and a student may join several groups. To prevent the possible transmissions of SARS, the NSYSU collects the member lists of all student groups, and makes the following rule in their standard operation procedure (SOP).
Once a member in a group is a suspect, all members in the group are suspects.
However, they find that it is not easy to identify all the suspects when a student is recognized as a suspect. Your job is to write a program which finds all the suspects.
Input
A case with n = 0 and m = 0 indicates the end of the input, and need not be processed.
Output
Sample Input
100 4 2 1 2 5 10 13 11 12 14 2 0 1 2 99 2 200 2 1 5 5 1 2 3 4 5 1 0 0 0
Sample Output
4 1 1题意:
需找SARS病毒感染者嫌疑人数,凡与感染者0号同学有同组关系的皆为嫌疑人。
分析:
基础并查集应用,将所有同属一大组的同学合并。最后找出0号同学所在组的人数,即为嫌疑人数。
并查集学习:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
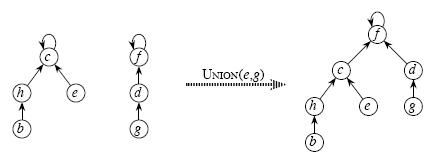
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图
l 并查集的优化
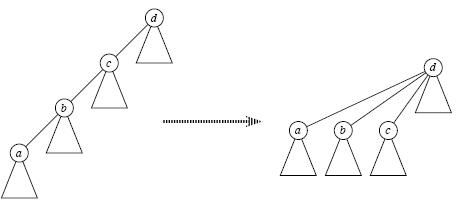
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
源代码如下:
#include <iostream>
using namespace std;
#define MAXN 30000
int father[MAXN],rank[MAXN];
void Init(int n)
{
int i;
for(i=0;i<n;i++)
{
father[i]=i;
rank[i]=1;
}
}
int Find_Set(int x)
{
if(x!=father[x])
{
father[x]=Find_Set(father[x]);
}
return father[x];
}
void Union(int x,int y)
{
x=Find_Set(x);
y=Find_Set(y);
if(x==y)return;
if(rank[x]>=rank[y])
{
father[y]=x;
rank[x]=rank[x]+rank[y];
}else
{
father[x]=y;
rank[y]=rank[y]+rank[x];
}
}
int main()
{
freopen("in.txt","r",stdin);
int n,m,k,first,next;
int i,j;
while(1)
{
cin>>n>>m;
if(n==0 && m==0)break;
Init(n);
for(i=0;i<m;i++)
{
cin>>k>>first;
for(j=1;j<k;j++)
{
cin>>next;
Union(first,next);
}
}
cout<<rank[father[0]]<<endl;
}
return 0;
}