Spark SQL and DataFrame Guide(1.4.1)——之Data Sources
数据源(Data Sources)
Spark SQL通过DataFrame接口支持多种数据源操作。一个DataFrame可以作为正常的RDD操作,也可以被注册为临时表。
1. 通用的Load/Save函数
默认的数据源适用所有操作(可以用spark.sql.sources.default设置默认值)

之后,我们就可以使用hadoop fs -ls /user/hadoopuser/在此目录下找到namesAndFavColors.parquet文件。
- 手动指定数据源选项
我们可以手动指定数据源选项,需要使用全限定名(例如,org.apache.spark.sql.parquet),但是对于内置数据源也可以使用短名称(json,parquet,jdbc)。
df = sqlContext.read.load("examples/src/main/resources/people.json", format="json")
df.select("name", "age").write.save("namesAndAges.parquet", format="parquet")- 存储模式(Save Modes)
Save操作可以选择SaveMode,指定如何处理已存在的数据。但是这些Save mode没有使用任何的锁机制而且不具有原子性。因此在多个writer同时向一个位置写的时候是不安全的。此外,在执行Overwrite的时,数据将在写入新数据之前被删除。
| Scala/Java | Python | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists (default) | “error” (default) | 保存DataFrame到数据源,当数据已经存在时,抛出错误 |
| SaveMode.Append | “append” | 保存DataFrame到数据源,当数据或表已存在时,DataFrame中的数据会append到已有的数据中 |
| SaveMode.Overwrite | “overwrite” | 保存DataFrame到数据源,当数据或表已存在时,DataFrame中的数据会覆盖原有的数据 |
| SaveMode.Ignore | “ignore” | Ignore模式意味着,保存DataFrame到数据源,当数据或表已存在时,不会保存DataFrame中的数据。即不改变原来的数据;有点类似SQL中的CREATE TABLE IF NOT EXISTS |
- 存储到持久化表中
在使用HiveContext的时候,DataFrames可以被保存为持久化表,使用saveAsTable命令而不是registerTempTable命令。saveAsTable将会物化DataFrame的内容并创建一个指针指向HiveMetastore中的数据。只要你连接着同一个metastore,持久化表在你的Spark程序重启后将仍然存在。
在SQLContext中调用将表名称作为参数的table方法可以创建一个持久化表的DataFrame。这里我们用先创建一个临时表模拟下:
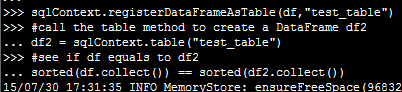
对比的结果显然是True
通常saveAsTable将创建一个“managed table”,这样数据的位置将被metastore掌控,Managed table将在一个表被drop后删掉所有的数据。
2.Parquet Files
parquet 是一个列存储格式,Spark Sql支持读写Parquet文件并自动保存原始数据的Schema。
- 程序加载数据
# sqlContext from the previous example is used in this example.
schemaPeople # The DataFrame from the previous example.
# DataFrames can be saved as Parquet files, maintaining the schema information.
schemaPeople.write.parquet("people.parquet")
# Read in the Parquet file created above. Parquet files are self-describing so the schema is preserved.
# The result of loading a parquet file is also a DataFrame.
parquetFile = sqlContext.read.parquet("people.parquet")
# Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile");
teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenNames = teenagers.map(lambda p: "Name: " + p.name)
for teenName in teenNames.collect():
print teenName- 发现分区
对表进行分区在像Hive这样的系统中是一个常见的优化方法。在一个分区表中,数据被存放在不同的目录中,使用分区列的值编码每个分区目录的路径。Parquet数据源能够自动发现并推断分区信息。例如,我们可以存储之前使用的数据到一个分区表,使用如下目录结构,用两个额外的列gender 和country作为分区列:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...使用 SQLContext.read.parquet 或者 SQLContext.read.load 进入路径 path/to/table ,Spark SQL能自动从路径中抽取分区信息。返回的DataFrame的Schema变为:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)注意:分区列的数据类型是自动推断的,目前只支持string和数字类型。
- 合并Schema
和ProtocolBuffer, Avro, Thrift 一样,Parquet 支持Schema演进。用户起初可以创建一个简单的Schema并逐渐根据需要加入更多的列。这样,最终会得到多个Parquet文件,他们带有不同但是相互兼容的Schema。Parquet数据源目前能自动探测这种情况并合并所有文件的Schema。
# sqlContext from the previous example is used in this example.
# Create a simple DataFrame, stored into a partition directory
df1 = sqlContext.createDataFrame(sc.parallelize(range(1, 6))\
.map(lambda i: Row(single=i, double=i * 2)))
df1.save("data/test_table/key=1", "parquet")
# Create another DataFrame in a new partition directory,
# adding a new column and dropping an existing column
df2 = sqlContext.createDataFrame(sc.parallelize(range(6, 11))
.map(lambda i: Row(single=i, triple=i * 3)))
df2.save("data/test_table/key=2", "parquet")
# Read the partitioned table
df3 = sqlContext.load("data/test_table", "parquet")
df3.printSchema()
# The final schema consists of all 3 columns in the Parquet files together
# with the partitioning column appeared in the partition directory paths.
# root
# |-- single: int (nullable = true)
# |-- double: int (nullable = true)
# |-- triple: int (nullable = true)
# |-- key : int (nullable = true)- 配置
配置Parquet可以使用SQLContext中的 setconf 命令或者SQL中运行 SET key=value 命令。
| 属性名 | 默认值 | 含义 |
|---|---|---|
| spark.sql.parquet.binaryAsString | false | 一些使用Parquet的系统,特别是Impala和老版本的Spark SQL,在写入Parquet Schema的时候不会区分二进制数据和string数据。此标志告诉Spark SQL将二进制数据解释为String以提供兼容性。 |
| spark.sql.parquet.int96AsTimestamp | True | 一些使用Parquet的系统,特别是Impala将Timestamp 存储成INT96。Spark为了避免纳米级的精度丢失也会将Timestamp 存储成INT96。此标志告诉Spark SQL将INT96数据解释为timestamp 以提供兼容性。 |
| spark.sql.parquet.cacheMetadata | True | Turns on caching of Parquet schema metadata.能够加快静态数据的查询速度。 |
| spark.sql.parquet.compression.codec | gzip | 设置写入Parquet文件时的压缩编码。可以设为:uncompressed, snappy, gzip, lzo |
| spark.sql.parquet.filterPushdown | false | Turn on Parquet filter pushdown optimization.默认是关闭的,由于已知的bugin Parquet 1.6.0rc3 (PARQUET-136)。但如果你的表不包含任何可为空的string或者二进制列,打开此开关仍然是安全的。 |
| spark.sql.parquet.convertMetastoreParquet | true | 当设置为false,Spark SQL 将会对parquet tables 使用 Hive SerDe 而不是内置的支持。 |