sparkSQL1.1入门之四:深入了解sparkSQL运行计划
前面两章花了不少篇幅介绍了SparkSQL的运行过程,很多读者还是觉得其中的概念很抽象,比如Unresolved LogicPlan、LogicPlan、PhysicalPlan是长得什么样子,没点印象,只知道名词,感觉很缥缈。本章就着重介绍一个工具hive/console,来加深读者对sparkSQL的运行计划的理解。

在控制台的scala提示符下,输入:help可以获取帮助,输入Tab键会陈列出当前可用的方法、函数、及变量。下图为按Tab键时显示的方法和函数,随着用户不断使用该控制态,用户定义或使用过的变量也会陈列出来。
2:常用操作



2.5 查看优化后的LogicalPlan





查询parquetQuery的整个运行计划:
查看hiveQuery的整个运行计划:

从上面可以看出,来自jsonFile、parquetFile、hive数据的物理计划还有有很大区别的。




上面的查询,在Optimized的过程中,将age>=19和age<30这两个Filter合并了,合并成((age>=19) && (age<30))。其实上面还做了一个其他的优化,就是project的下推,子查询使用了表的所有列,而主查询使用了列name,在查询数据的时候子查询优化成只查列name。

在Optimized的过程中,将常量表达式直接累加在一起,用新的列名来表示。

最后,使用自定义优化函数进行优化:

可以看到两个Filter合并在一起了。

然后,直接用transform将自定义的rule:

该transform在LogicPlan的主查询和子查询的project相同时合并project。
1:hive/console安装
sparkSQL从1.0.0开始提供了一个sparkSQL的调试工具hive/console。该工具是给开发者使用,在编译生成的安装部署包中并没有;该工具需要使用sbt编译运行。要使用该工具,需要具备以下条件:
- spark1.1.0源码
- hive0.12源码并编译
- 配置环境变量
1.1:安装hive/cosole
下面是笔者安装过程:
A:下载spark1.1.0源码,安装在/app/hadoop/spark110_sql目录
B:下载hive0.12源码,安装在/app/hadoop/hive012目录,进入src目录后,使用下面命令进行编译:
ant clean package -Dhadoop.version=2.2.0 -Dhadoop-0.23.version=2.2.0 -Dhadoop.mr.rev=23
C:配置环境变量文件~/.bashrc后,source ~/.bashrc使环境变量生效。
export HIVE_HOME=/app/hadoop/hive012/src/build/dist export HIVE_DEV_HOME=/app/hadoop/hive012/src export HADOOP_HOME=/app/hadoop/hadoop220D:启动
切换到spark安装目录/app/hadoop/spark110_sql,运行命令:
sbt/sbt hive/console
经过一段漫长的sbt编译过程,最后出现如下界面:
1.2:hive/console原理
hive/console的调试原理很简单,就是在scala控制台装载了catalyst中几个关键的class,其中的TestHive预定义了表结构并装载命令,这些数据是hive0.12源码中带有的测试数据,装载这些数据是按需执行的;这些数据位于/app/hadoop/hive012/src/data中,也就是$HIVE_DEV_HOME/data中。
/*源自 sql/hive/src/main/scala/org/apache/spark/sql/hive/TestHive.scala */
// The test tables that are defined in the Hive QTestUtil.
// /itests/util/src/main/java/org/apache/hadoop/hive/ql/QTestUtil.java
val hiveQTestUtilTables = Seq(
TestTable("src",
"CREATE TABLE src (key INT, value STRING)".cmd,
s"LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv1.txt")}' INTO TABLE src".cmd),
TestTable("src1",
"CREATE TABLE src1 (key INT, value STRING)".cmd,
s"LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv3.txt")}' INTO TABLE src1".cmd),
TestTable("srcpart", () => {
runSqlHive(
"CREATE TABLE srcpart (key INT, value STRING) PARTITIONED BY (ds STRING, hr STRING)")
for (ds <- Seq("2008-04-08", "2008-04-09"); hr <- Seq("11", "12")) {
runSqlHive(
s"""LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv1.txt")}'
|OVERWRITE INTO TABLE srcpart PARTITION (ds='$ds',hr='$hr')
""".stripMargin)
}
}),
......
)因为要使用hive0.12的测试数据,所以需要定义两个环境变量:HIVE_HOME和HIVE_DEV_HOME,如果使用hive0.13的话,用户需要更改到相应目录:
/*源自 sql/hive/src/main/scala/org/apache/spark/sql/hive/TestHive.scala */
/** The location of the compiled hive distribution */
lazy val hiveHome = envVarToFile("HIVE_HOME")
/** The location of the hive source code. */
lazy val hiveDevHome = envVarToFile("HIVE_DEV_HOME")
另外,如果用户想在hive/console启动的时候,预载更多的class,可以修改spark源码下的 project/SparkBuild.scala文件
/* 源自 project/SparkBuild.scala */
object Hive {
lazy val settings = Seq(
javaOptions += "-XX:MaxPermSize=1g",
// Multiple queries rely on the TestHive singleton. See comments there for more details.
parallelExecution in Test := false,
// Supporting all SerDes requires us to depend on deprecated APIs, so we turn off the warnings
// only for this subproject.
scalacOptions <<= scalacOptions map { currentOpts: Seq[String] =>
currentOpts.filterNot(_ == "-deprecation")
},
initialCommands in console :=
"""
|import org.apache.spark.sql.catalyst.analysis._
|import org.apache.spark.sql.catalyst.dsl._
|import org.apache.spark.sql.catalyst.errors._
|import org.apache.spark.sql.catalyst.expressions._
|import org.apache.spark.sql.catalyst.plans.logical._
|import org.apache.spark.sql.catalyst.rules._
|import org.apache.spark.sql.catalyst.types._
|import org.apache.spark.sql.catalyst.util._
|import org.apache.spark.sql.execution
|import org.apache.spark.sql.hive._
|import org.apache.spark.sql.hive.test.TestHive._
|import org.apache.spark.sql.parquet.ParquetTestData""".stripMargin
)
}
下面介绍一下hive/console的常用操作,主要是和运行计划相关的常用操作。在操作前,首先定义一个表people和查询query:
//在控制台逐行运行
case class Person(name:String, age:Int, state:String)
sparkContext.parallelize(Person("Michael",29,"CA")::Person("Andy",30,"NY")::Person("Justin",19,"CA")::Person("Justin",25,"CA")::Nil).registerTempTable("people")
val query= sql("select * from people")
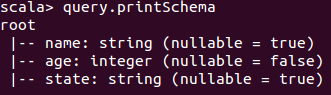
2.1 查看查询的schema
query.printSchema
2.2 查看查询的整个运行计划
query.queryExecution
2.3 查看查询的Unresolved LogicalPlan
query.queryExecution.logical
2.4 查看查询的analyzed LogicalPlan
query.queryExecution.analyzed
2.5 查看优化后的LogicalPlan
query.queryExecution.optimizedPlan
2.6 查看物理计划
query.queryExecution.sparkPlan
2.7 查看RDD的转换过程
query.toDebugString
2.8 更多的操作
更多的操作可以通过Tab键陈列出来,也可以参开sparkSQL的API,也可以参看源代码中的方法和函数。
3:不同数据源的运行计划
上面常用操作里介绍了源自RDD的数据,我们都知道,sparkSQL可以源自多个数据源:jsonFile、parquetFile、hive。下面看看这些数据源的schema:
3.1 json文件
json文件支持嵌套表,sparkSQL也可以读入嵌套表,如下面形式的json数据,经修整(去空格和换行符)保存后,可以使用jsonFile读入sparkSQL。
{
"fullname": "Sean Kelly",
"org": "SK Consulting",
"emailaddrs": [
{"type": "work", "value": "[email protected]"},
{"type": "home", "pref": 1, "value": "[email protected]"}
],
"telephones": [
{"type": "work", "pref": 1, "value": "+1 214 555 1212"},
{"type": "fax", "value": "+1 214 555 1213"},
{"type": "mobile", "value": "+1 214 555 1214"}
],
"addresses": [
{"type": "work", "format": "us",
"value": "1234 Main StnSpringfield, TX 78080-1216"},
{"type": "home", "format": "us",
"value": "5678 Main StnSpringfield, TX 78080-1316"}
],
"urls": [
{"type": "work", "value": "http://seankelly.biz/"},
{"type": "home", "value": "http://seankelly.tv/"}
]
}去空格和换行符后保存为/home/mmicky/data/nestjson.json,使用jsonFile读入并注册成表jsonPerson,然后定义一个查询jsonQuery:
jsonFile("/home/mmicky/data/nestjson.json").registerTempTable("jsonPerson")
val jsonQuery = sql("select * from jsonPerson")
查看jsonQuery的schema:
jsonQuery.printSchema
查看jsonQuery的整个运行计划:
jsonQuery.queryExecution
3.2 parquet文件
parquet文件读入并注册成表parquetWiki,然后定义一个查询parquetQuery:
parquetFile("/home/mmicky/data/spark/wiki_parquet").registerTempTable("parquetWiki")
val parquetQuery = sql("select * from parquetWiki")
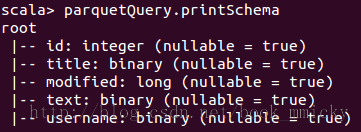
查询parquetQuery的schema:
parquetQuery.printSchema
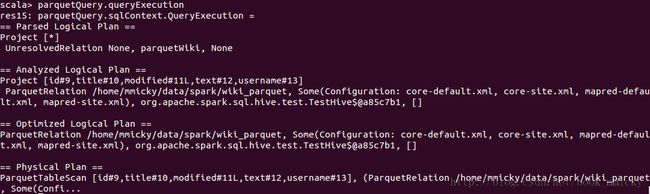
查询parquetQuery的整个运行计划:
parquetQuery.queryExecution
3.3 hive数据
之前说了,TestHive类中已经定义了大量的hive0.12的测试数据的表格式,如src、sales等等,在hive/console里可以直接使用;第一次使用的时候,hive/console会装载一次。下面我们使用sales表看看其schema和整个运行计划。首先定义一个查询hiveQuery:
val hiveQuery = sql("select * from sales")
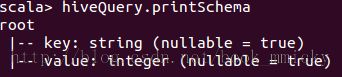
查看hiveQuery的schema:
hiveQuery.printSchema
查看hiveQuery的整个运行计划:
hiveQuery.queryExecution
从上面可以看出,来自jsonFile、parquetFile、hive数据的物理计划还有有很大区别的。
4:不同查询的运行计划
为了加深理解,我们列几个常用查询的运行计划和RDD转换过程。
4.1 聚合查询
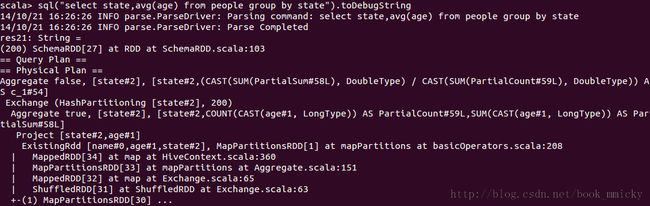
sql("select state,avg(age) from people group by state").queryExecution
sql("select state,avg(age) from people group by state").toDebugString
4.2 join操作
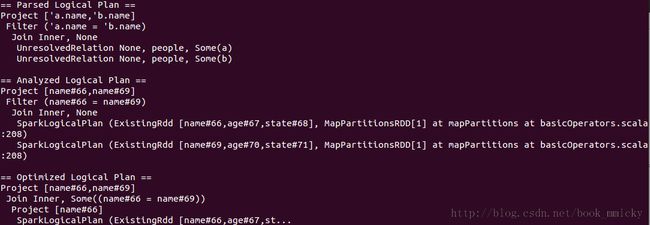
sql("select a.name,b.name from people a join people b where a.name=b.name").queryExecution
sql("select a.name,b.name from people a join people b where a.name=b.name").toDebugString
4.3 Distinct操作
sql("select distinct a.name,b.name from people a join people b where a.name=b.name").queryExecution
sql("select distinct a.name,b.name from people a join people b where a.name=b.name").toDebugString
5:查询的优化
上面的查询比较简单,看不出优化的过程,下面看几个例子,可以理解sparkSQL的优化过程。
5.1 CombineFilters
CombineFilters就是合并Filter,在含有多个Filter时发生,如下查询:
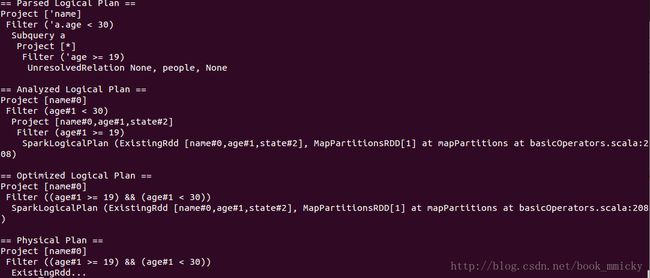
sql("select name from (select * from people where age >=19) a where a.age <30").queryExecution
上面的查询,在Optimized的过程中,将age>=19和age<30这两个Filter合并了,合并成((age>=19) && (age<30))。其实上面还做了一个其他的优化,就是project的下推,子查询使用了表的所有列,而主查询使用了列name,在查询数据的时候子查询优化成只查列name。
5.2 PushPredicateThroughProject
PushPredicateThroughProject就是project下推,和上面例子中的project一样。
sql("select name from (select name,state as location from people) a where location='CA'").queryExecution
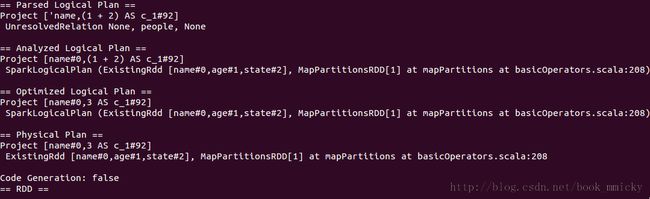
5.3 ConstantFolding
ConstantFolding是常量叠加,用于表达式。如下面的例子:
sql("select name,1+2 from people").queryExecution
在Optimized的过程中,将常量表达式直接累加在一起,用新的列名来表示。
5.4 自定义优化
在sparkSQL中的Optimizer中定义了3类12中优化方法,这里不再一一陈列。对于用于自定义的优化,在hive/console也可以很方便的调试。只要先定义一个LogicalPlan,然后使用自定义的优化函数进行测试就可以了。下面就举个和CombineFilters一样的例子,首先定义一个函数:
object CombineFilters extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case Filter(c1, Filter(c2, grandChild)) =>
Filter(And(c1,c2),grandChild)
}
}
然后定义一个query,并使用query.queryExecution.analyzed查看优化前的LogicPlan:
val query= sql("select * from people").where('age >=19).where('age <30)
query.queryExecution.analyzed
最后,使用自定义优化函数进行优化:
CombineFilters(query.queryExecution.analyzed)
可以看到两个Filter合并在一起了。
甚至,在hive/console里直接使用transform对LogicPlan应用定义好的rule,下面定义了一个query,并使用query.queryExecution.analyzed查看应用rule前的LogicPlan:
val hiveQuery = sql("SELECT * FROM (SELECT * FROM src) a")
hiveQuery.queryExecution.analyzed
然后,直接用transform将自定义的rule:
hiveQuery.queryExecution.analyzed transform {
case Project(projectList, child) if projectList == child.output => child
}
该transform在LogicPlan的主查询和子查询的project相同时合并project。
经过上面的例子,加上自己的理解,相信大部分的读者对sparkSQL中的运行计划应该有了比较明确的了解。