Hadoop Streaming
Hadoop版本:Hadoop-0.20.204
Hadoop的Streaming框架允许任何程序语言实现的可执行程序或者脚本在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。Streaming的原理是用Java实现一个包装用户程序的MapReduce程序,该程序负责调用MapReduce Java接口获取key/value对输入,创建一个新的进程启动包装的用户程序,将数据通过管道传递给包装的用户程序处理,然后调用MapReduce Java接口将用户程序的输出切分成key/value对输出。Mapper重-input中读入数据(默认是一行一行读),然后提交到output。
如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-streaming-0.20.204.0.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \
-reducer /bin/wc
上面的四个参数是最基本的,
-input myInputDirs:指定作业输入,myInputDirs可以是文件或者目录,可以使用*通配符,-input选项可以使用多次指定多个文件或目录作为输入。 -output myOutputDir:指定作业输出目录,myOutputDir必须不存在,而且执行作业的用户必须有创建该目录的权限,-output只能使用一次。 -mapper:指定mapper可执行程序或脚本,当然也可以是java类,必须指定且唯一。 -reducer:指定reducer可执行程序或脚本,同样也可以是java类,必须指定且唯一。
其他更详细的参数如下:

其中:
-file, -cacheFile, -cacheArchive:分别用于向计算节点分发本地文件(特别是当可执行文件在本地时,一定要记得指定)、HDFS文件和HDFS压缩文件。 -inputformat, -outputformat:指定inputformat和outputformat Java类,用于读取输入数据和写入输出数据,分别要实现InputFormat和OutputFormat接口。如果不指定,默认使用TextInputFormat和TextOutputFormat。 -numReduceTasks:指定reducer的个数,如果设置-numReduceTasks 0或者-reducer NONE则没有reducer程序,mapper的输出直接作为整个作业的输出。 -combiner:指定combiner Java类,对应的Java类文件打包成jar文件后用-file分发。 -partitioner:指定partitioner Java类,Streaming提供了一些实用的partitioner实现。 -cmdenv NAME=VALUE:给mapper和reducer程序传递额外的环境变量,NAME是变量名,VALUE是变量值。
也可以通过改变"-D<property>=<value>"来增加一些其他的配置,比如:
-D dfs.data.dir=/tmp -D mapred.reduce.tasks=0 -D mapred.local.dir=/tmp/local -D mapred.system.dir=/tmp/system -D mapred.temp.dir=/tmp/temp
下面举个C++的统计单词个数的例子:
Mapper函数:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str;
while(cin>>str)
cout<<str<<"\t"<<"1"<<endl;
return 0;
}
Reducer函数:
#include <iostream>
#include <map>
using namespace std;
int main() {
map<string,int> wordMap;
map<string,int>::iterator it;
string key;
int value;
int count;
while(cin>>key>>value) {
wordMap[key] +=value;
}
for(it=wordMap.begin();it != wordMap.end();it++) {
cout<<it->first<<"\t"<<it->second<<endl;
}
return 0;
}
然后运行脚本:
bin/hadoop fs -rmr stream-c++-output bin/hadoop jar contrib/streaming/hadoop-streaming-0.20.204.0.jar -file cTest/C++/Mapper -mapper "cTest/C++/Mapper" -file cTest/C++/Reducer -reducer "cTest/C++/Reducer" -input input -output stream-c++-output
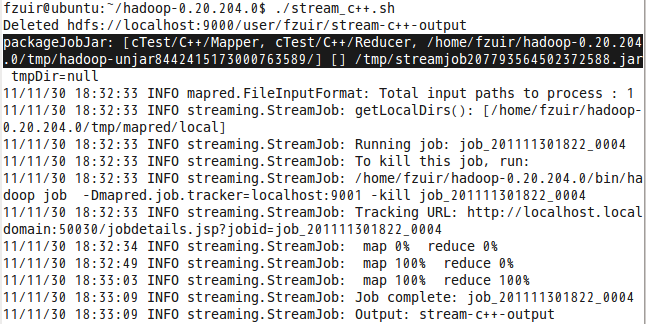
我们看到上图中,有一个packageJobJar的过程,该过程就是讲Mapper和Reducer任务打包,并分发给子节点。另外:运行的时候因为Mapper和Reducer的程序是在本地,所以要加上-file,之前没加,一直build jof failed。
参考资料:
http://hadoop.apache.org/common/docs/r0.20.204.0/streaming.html