Heterogeneous Parallel Programming(异构并行编程)学习笔记(二)
这里讲讲二维数据和内存模型
1. 二维参数设置
前面已经说过,CUDA支持多维的Grid和Block,以方便处理多维数据,那么在调用Kernel时函数也会有所不同。假定需要处理一张76x62像素的图片,采用16x16的Block,则参数设置如下:
#define TILE_WIDTH 16
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH, 1);
dim3 dimGrid(75 / TILE_WIDTH + 1, 61 / TILE_WIDTH + 1, 1);
这样就能确保Thread覆盖到了每一个像素,如下图所示:
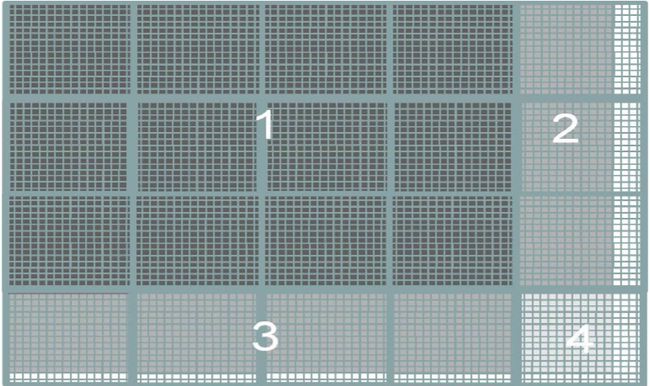
其中1区域的Block每一个Thread都对应有像素,而2、3、4则不然。这会产生影响,后面再讨论。
2. 二维数组定位
在实际使用中,我们常常用行主导的一维数组代替二维数组,即,twoDim[2, 3] = oneDim[2 * numCol + 3]。
用一个矩阵相乘的例子能很好的说明:
__global__
void matMulti(float *A, float *B, float *C, int n)
{
// use 2D Idx
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// C = A * B
if (row < n && col < n)
{
float value = 0;
for (int i = 0; i < n; i++)
{
value += A[row * n + i] * B[i * n + col];
}
C[row * n + col] = value;
}
}
稍后会看到,上述代码可以被优化。
3. Block大小选择、Warp
在硬件中,Block被分配给Streaming Multiprocessor来执行。以Fermi SM为例,每一个SM最多可以容纳8个Block或者1536个Thread。在选择Block大小时需要考虑到这些因素。例如,若Block大小为8x8,则一个SM装载的Thread为8 * 8 * 8 = 512个,仅仅使用了1/3的能力;而如果Block大小为16x16,则一个SM可以装载6个Block,从而达到最大能力。
每一个Block被连续地分成若干个Warp执行,Warp通常大小为32Thread,即Thread0-Thread31属于Warp0,Thread32-Thread63属于Warp2,依此类推。Warp是SM调度的单位,一个Warp中的所有Thread一定是在执行同一指令。
4. 控制发散
前面提到,一个Warp中的所有Thread执行同一指令。但是,由于不同Thread的数据不同,如果有基于数据的判断,就可能产生不同的结果。这时,就会产生多路径问题即发散,意味着Thread需要执行不同的指令。SM处理的方式是多次执行,每次沿着一条路径,直到所有路径都执行完毕。所以,控制发散直接关系到程序的性能。
以上面图片处理的图为例,每个Thread的有一个条件判断:
if (row < numRow && col < numCol)
区域1的Thread全部为True,而2、3、4则有部分Thread返回False。下面来简单的分析一下:
已知Warp大小为32,Thread连续划分,且采用的是行主导的方式。Block的大小为16x16。那么,Warp2(区域2的第一行)包含了Block[0, 4][0]的16个Thread(返回False)和Block[1, 0][1]的16个Thread(返回True),它是发散的。然而区域3中的Thread并不发散,这是因为区域3倒数第二行正好是从Warp150开始,所有的Thread返回均为False。所以,发散的Warp一共有60个。
5. 内存模型与变量类型
Grid的结构如下图所示:
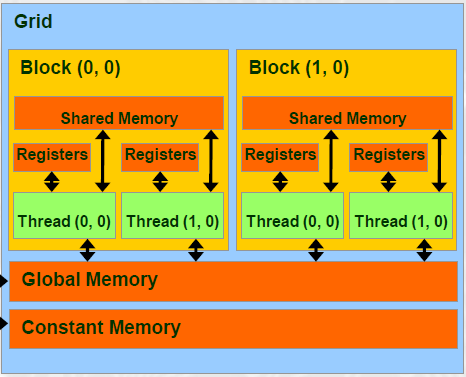
其中,Register的读写速度最快,约为1个周期,但容量相当有限;Shared Memory的读写速度约为5个周期;而Global Memory的读写速度约为500个周期。由此可见,尽量少地使用Global Memory能优化整个程序的性能。稍后将用这种方法优化之前的矩阵乘法。
对应于存储类型,CUDA的变量也分为四种类型,如下所示:

其中__shared__和__constant__前面的__device__声明是可以省略的。注意寄存器变量和共享变量的生命周期,如果要记录其结果,则需用另外的全局变量保存。
6. 优化矩阵乘法与同步
考虑前面的矩阵乘法,A、B、C都是在程序初始化时分配的Device内存,也就是Grid的Global Memory。每次Thread都要到Global Memory取数据;同时,很多Thread都会读取相同的数据,例如计算C[0]和C[1]都用到A[0]-A[numCol - 1]的数据;如下图所示:
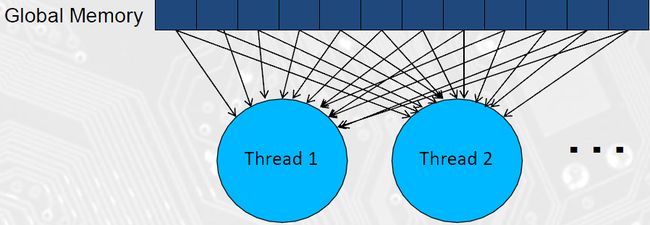
这里正是使用Shared Memory的场合。如果在头一次读取时就把数据存入Shared Memory中,让需要这些数据的Thread处理完成,再去Global Memory读取下一批数据,就能使程序性能提高很多;如下图所示:
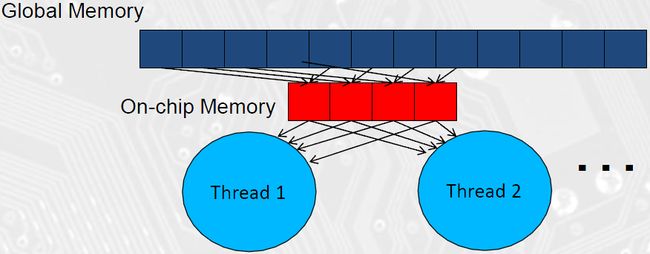
采用上述的方法,就产生了对时序的依赖。我们要确保在数据读取到Shared Memory之前Thread保持等待;且读取下一批数据到Shared Memory之前所有Thread都要处理完成。CUDA本身不会对Thread间的时序关系作出任何假设或保证,因此我们需要强制程序同步,所用到的函数是__syncthreads()。
7. 例:矩阵乘法
#define TILE_WIDTH 16
__global__
void matMulti(float *A, float *B, float *C, int n)
{
__shared__ float d_A[TILE_WIDTH][TILE_WIDTH];
__shared__ float d_A[TILE_WIDTH][TILE_WIDTH];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float value = 0;
// divided into tiles to compute
for (int i = 0; i < n / TILE_WIDTH, i++)
{
// loading data from global memory to shared memory
d_A[threadIdx.y][threadIdx.x] = A[row*n + i*TILE_WIDTH + threadIdx.x];
d_B[threadIdx.y][threadIdx.x] = B[(i * TILE_WIDTH + threadIdx.y) * n + col];
__syncthreads();
for (int j = 0; j < TILE_WIDTH; j++)
{
value += A[threadIdx.y][j] * B[j][threadIdx.x];
__syncthreads();
}
}
C[row * n + col] = value;
}