EM算法原理详解与高斯混合模型
借助于machine learning cs229和文章【1】中的内容把EM算法的过程顺一遍,加深一下印象。
关于EM公式的推导,一般会有两个证明,一个是利用Jesen不等式,另一个是将其分解成KL距离和L函数,本质是类似的。
下面介绍Jensen EM的整个推导过程。
Jensen不等式
回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x, f′′(x)≥0 ,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的( H≥0 ),那么f是凸函数。如果 f′′(x)>0 或者 H>0 ,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么
E[f(x)]≥f(E[x])
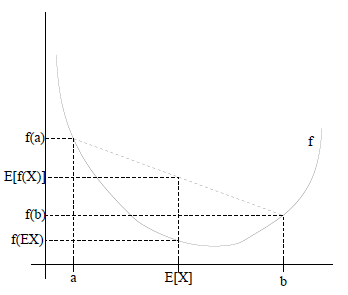
特别地,如果f是严格凸函数,那么
E[f(x)]>f(E[x])当且仅当 p(X=E(X))=1 ,也就是说X是常量。这里我们将 f(E[X]) 简写为 f(EX) 。
如果用图表示会很清晰:
图中,实线 f 是凸函数, X 是随机变量,有 0.5 的概率是 a ,有 0.5 的概率是 b 。(就像掷硬币一样)。 X 的期望值就是 a 和 b 的中值了,图中可以看到
E[f(x)]≥f(E[x])成立。当 f 是(严格)凹函数当且仅当 −f 是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向,也就是 E[f(x)]≤f(E[x]) 。
EM算法
给定的训练样本是 {x(1),...,x(m)} ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求 θ 一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。既然不能直接最大化 l(θ) ,我们可以不断地建立 l(θ) 的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i,让 Qi 表示该样例隐含变量z的某种分布, Qi 满足的条件是 ∑zQi(z)=1,Qi(z)≥1 。(如果z是连续性的,那么clip_image032[2]是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
可以由前面阐述的内容得到下面的公式:
(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式,考虑到 log(x) 是凹函数(二阶导数小于0),而且
就是 p(x(i),z(i);θ)Qi(z(i)) 的期望(回想期望公式中的Lazy Statistician规则)
设Y是随机变量X的函数 y=g(x) (g是连续函数),那么
(1) X是离散型随机变量,它的分布律为 P(X=xk)=pk,k=1,2,... .若 ∑∞k=1g(xk)pk 绝对收敛,则有
E(Y)=E[g(X)]=∑∞k=1g(xk)pk
(2) X是连续型随机变量,它的概率密度为 f(x) ,若 ∫∞−∞g(x)f(x)dx 绝对收敛,则有
E(Y)=E[g(X)]=∫∞−∞g(x)f(x)dx
对应于上述问题,Y是 p(x(i),z(i);θ)Qi(z(i)) ,X是 z(i) , Qi(z(i)) 是 pk ,g是 z(i) 到 p(x(i),z(i);θ)Qi(z(i)) 的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:
可以得到(3)。
这个过程可以看作是对 l(θ) 求了下界。对于 Qi 的选择,有多种可能,那种更好的?假设 θ 已经给定,那么 l(θ) 的值就决定于 Qi(z(i)) 和 p(x(i),z(i)) 了。我们可以通过调整这两个概率使下界不断上升,以逼近 l(θ) 的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于 l(θ) 了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
c为常数,不依赖于 z(i) 。对此式子做进一步推导,我们知道 ∑zQi(z(i))=1 ,那么也就有 ∑zp(x(i),z(i);θ)=c ,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
至此,我们推出了在固定其他参数 θ 后, Qi(z(i)) 的计算公式就是后验概率,解决了 Qi(z(i)) 如何选择的问题。这一步就是E步,建立 l(θ) 的下界。接下来的M步,就是在给定 Qi(z(i)) 后,调整 l(θ) ,去极大化 l(θ) 的下界(在固定 Qi(z(i)) 后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
循环重复直到收敛 {
(E步)对于每一个i,计算
(M步)计算
那么究竟怎么确保EM收敛?假定 θt 和 θt+1 是EM第t次和t+1次迭代后的结果。如果我们证明了 l(θt)≤l(θt+1) ,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定 θ(t) 后,我们得到E步
Qi(z(i))=p(z(i);x(i)θ)
这一步保证了在给定 θ(t) 时,Jensen不等式中的等式成立,也就是
然后进行M步,固定 Qi(z(i)) ,并将 θ(t) 视作变量,由EM的操作可以推导出以下式子成立:
等式(4)成立是由于琴生不等式,等式(5)成立是由于我们在M步取得是max操作。
如果我们定义
从前面的推导中我们知道 l(θ)≥J(Q,θ) ,EM可以看作是J的坐标上升法,E步固定 θ ,优化 Q ,M步固定 Q 优化 θ 。
重新审视混合高斯模型
我们已经知道了EM的精髓和推导过程,再次审视一下混合高斯模型。之前提到的混合高斯模型的参数 Φ 和 μ ,为了简单,这里在M步只给出 Φ 和 μ 的推导方法。
E步很简单,按照一般EM公式得到:
简单解释就是每个样例i的隐含类别 z(i) 为j的概率可以通过后验概率计算得到。 ϕ 是每个类的概率。
在M步中,我们需要在固定 Qi(z(i)) 后最大化最大似然估计,也就是
这是将 z(i) 的k种情况展开后的样子,未知参数 ϕj , μj 和 Σj 。
固定 ϕj ,和 Σj ,对 μj 求导得
等于0时,得到
μj=∑mi=1w(i)jx(i)Σmi=1w(i)j
这就是我们之前模型中的 μ 的更新公式。
然后推导 ϕ 的更新公式。看之前得到的
分子和分母上与 ϕ 无关的常数都可以通过log提取出来,,实际上需要优化的公式是:
需要知道的是, ϕj 还需要满足一定的约束条件就是 Σkj=1ϕj=1 。
这个优化问题我们很熟悉了,直接构造拉格朗日乘子。
还有一点就是 ϕj>0 ,但这一点会在得到的公式里自动满足。
求导得,
∂∂ϕjL(ϕ)=∑mi=1w(i)jϕj+β
等于0,得到
ϕj=∑mi=1w(i)j−β
也就是说 ϕj∝∑mi=1w(i)j 再次使用 ∑kj=1ϕj=1 ,得到
−β=∑mi=1∑kj=1w(i)j=Σmi=11=m
这样就神奇地得到了 β 。
那么就顺势得到M步中 ϕj 的更新公式:
ϕj=1m∑mi=1w(i)j
Σ 的推导也类似,不过稍微复杂一些,毕竟是矩阵。结果在之前的混合高斯模型中已经给出。
关于EM证明的补充,一般情况下可以通过Jensen不等式得到 ∑mi=1logp(x;θ) 的下界来求解,但是将该公式展开似乎更直观一些。
首先是将 p(x;θ) 拆分开来,我们注意到 p(x,z;θ)=p(x;θ)p(z|x;θ) 这里有联合概率,x的生成概率,z的后验概率,取 log 然后做一下变换
同时乘以 q(z) 并对 q(z) 求和得到
由于z与 p(x;θ) 独立,并且 σz(q)=1 ,所以又
写作
看到这里应该很明白了,在NG的推导中放缩掉的是这里的KL距离,最后得到的是这里的 L(q;θ) ,当 q(z) 和 p(z;x,θ) 相等时KL距离为0,前面的推导的等式成立。
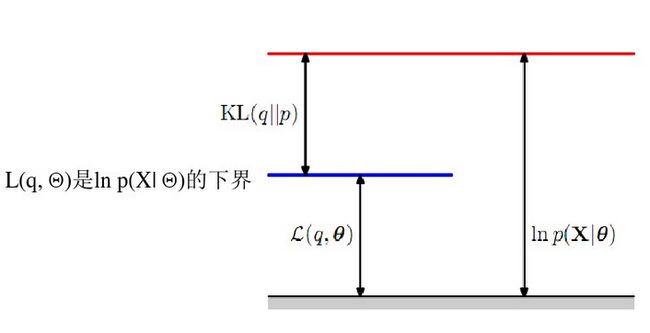
E-step
假设当前的参数为 θold ,则Estep可以被描述为:固定 θold 找一个分布 q(z) ,使得 L(q,θold) 最大
由于 lnp(x;θold 与z无关则使 L(q,θold) 最大姐使KL(q||p)最小(=0),也就是说 q(z)=p(z;x,θold)
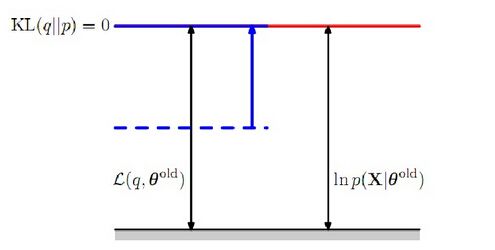
回想高斯混合分布,用 p(z;x,μ,σ,π) 去求 E[z] ,这个时候 KL(q||p)=0
M-step:固定 q(z) 找一组参数 θnew ,使得 L(q,θnew) 最大,
lnp(x;θ) 的增大可能来自两部分 L(q,θnew) 和 KL(q||p) (因为此时 p(z;x,θnew) )而 q(z;x,θold),p≠q


这里可以看到,L的下届提高了, ln(p(x;θ) 的下届也提高了。
参考:
【1】
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html#2831962
【2】http://wenku.baidu.com/view/d5e6973a87c24028915fc361.html
【3】http://cs229.stanford.edu/materials.html
【4】http://freemind.pluskid.org/machine-learning/regularized-gaussian-covariance-estimation/