主流行式数据库评测:DB2 9.7企业版
主流行式数据库评测:DB2 9.7企业版
【IT168 专稿】DB2拥有悠久的历史,70年代初,当时在IBM工作的埃德加·科德(E.F.Codd)博士描述了关系型数据库理论,DB2的前身System R和SQL语言就是基于此理论实现的,1983年,IBM发布了DATABASE 2(DB2)for MVS,这是第一个以DB2命名的版本。DB2发展到现在,已经成为一个涵盖多个平台的数据库族。它主要的执行环境为UNIX、Linux、z/OS,以及Windows服务器操作系统。版本包括Express、Express-C、Workgroup和Enterprise版本。基于Linux/UNIX/Windows的最复杂的版本是DB2 Data Warehouse Enterprise Edition,缩写为DB2 DWE。这个版本的偏重于混合工作负荷(在线事务处理和数据仓库)和商业智能的实现。DB2 DWE包括一些商业智能的特性例如ETL、数据挖掘、OLAP加速以及in-line analytics。Express-C是免费版本,只能使用2个CPU内核和2GB的内存。2006年IBM发布DB2 9,和Oracle相比,DB2的版本进化较慢,目前最新的版本是10 for z/OS和9.8 pureScale,而官方网站上能下载到的最新的试用版本是9.7版。本文就是基于DB2 9.7版本展开评测!
一、数据库安装
IBM在其DB2官网上提供了各种版本DB2软件的下载,我们选择最新的IBM DB2 9.7 Data Server Trial版本。和大多数试用软件一样,这个试用版有90天的试用期限制。通过版本说明我们了解到,企业版具有更多的高级功能,比如:分区、并行查询等,也具有更大的扩展性。因此我们采用9.7企业版来做评测,以最大限度地了解这个产品的全部功能。在上述网站注册一个免费用户就可以下载安装文件。这里有db2补丁下载,列出了目前仍然支持的所有版本,补丁也可以直接作为安装盘安装,没有lic文件自动变成90天评估版。这点比Oracle做得好,后者必须是付费用户才能下载补丁。有趣的是,虽然db2 9.8版没有提供下载,但它的补丁却可以下载,也可以进行安装,不过由于9.8版安装对软硬件有特殊要求,一般用户难以满足,因此暂不讨论。感兴趣的读者可阅读此文档了解更多信息。
IBM提供了DB2文档在线浏览和英文文档下载地址、翻译文档地址,其中也包括简体中文版,但某些文档只有英文版本,如SQL说明书,另一个FTP方式的文档下载地址。
DB2 9.7支持的操作平台有为Windows 32位/64位, Linux,Solaris、HP-UX 、AIX等。本次测试基于 Intel Xeon 7550*8的PC服务器上用VMWare VSphere 4.1管理的虚拟机,虚拟机的逻辑CPU个数是 8,内存 100GB,存储为8个300GB SAS本地磁盘,采用一块512M缓存RAID卡,按RAID5方式组成磁盘阵列。操作系统采用和RHEL 5相同的核心级别的RedFlag Asian Linux Sever 3.0 x64。因此选用的安装文件是64位x86 Linux版本,v9.7_linuxx64_server.tar.gz ,安装文件大约700M,需解压缩到一个目录才能执行安装。DB2的安装过程比较复杂,虽然不像Oracle那样某些步骤不得不用到图形界面,基本都可以在命令行完成,但还是有不少陷阱,一不小心就会掉进去。因此本文在详细地介绍安装的每个步骤时,专门指出易错的关键步骤。更详细的步骤,参考官方安装文档。简体中文版是上述地址下的DB2InstallingServers-db2isc972.pdf。
安装步骤如下:
1.安装前准备工作
将下载的安装文件上传到待安装的LINUX机器,解压缩到某个目录,产生了一个名为Server的子目录,进入子目录,可以看到有多个可执行的脚本,其中db2prereqcheck是先决条件检查,db2setup是图形界面安装程序,db2_install是命令行方式安装。还有一个db2目录,保存了需要安装的二进制文件。执行db2prereqcheck,如果没有返回任何结果,表明系统符合DB2安装的先决条件,可以进入下一步安装。如果返回信息,请按信息提示修改配置,然后再次运行,直到没有错误提示。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
2.安装DB2数据库软件
以操作系统root用户执行db2_install,根据提示操作,设定安装目录和要安装的版本等以后,耐心等待安装任务完成。DB2用一个安装包包括了同一操作系统平台各个版本的功能,只要在安装类型选择企业版即可,这里我们输入ESE。要注意,由于操作系统默认语言为简体中文,安装界面也是中文提示的,而且,必须输入中文"是"才能更改安装目录。和大多数unix下的软件一样,软件安装只是整个安装过程很小的一步,要使软件能正常工作,大量的配置和管理任务还在后头。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
3.注册license
本安装因为是评估版无须这一步。用户可以在90天内完全测试全部功能。对于购买了企业版等版本license的用户,需要注册license才能长期使用。
4.创建DB2运行所需要的用户组和用户
DB2没有独立的用户管理系统,必须借用OS用户来提供安全性认证,所以这里需要创建 LINUX用户和组。一共创建了3个组,每个组一个用户。其作用和含义分别是:
数据库管理服务器DAS用户 dasusr1 组名: dasadm1
管理实例的用户 db2inst1 组名:db2iadm1
受防护用户 db2fenc1 组名: db2fadm1
其中管理实例的用户 db2inst1是最常用的,我们为它设置口令db2,以便下面步骤的正常操作。创建完成后,执行如下命令查看/etc/group和/etc/passwd,检查用户组和用户是否创建成功。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
5.创建实例
需要以root用户创建das和实例。分别用下面2个命令:
dascrt创建的是DB2 adminstration server,每台服务器只有一个这种server,为进行DB2管理(比如运行控制中心)所必须,同时指定其管理用户是db2das;
db2icrt 创建的是实例,其名字一般和管理用户名一样,这里均为db2inst1;
创建成功以后,系统在db2das和db2inst1相应的home目录下产生了一个子目录。/home/db2inst1/sqllib目录中包括了一个db2profile文件,包括了设定各个db2实例中用到的环境变量,如DB2INSTANCE和各种命令的搜索路径,库的路径等,必须执行它,才能进行各种操作,或者将. ~/sqllib/db2profile一行加入/home/db2inst1/.profile文件(因为创建db2inst1用户时指定了shell类型是/bin/sh,如果是其他shell,则采用不同的profile文件,比如bash则采用.bash_profile),这样当切换到db2inst1用户时就会自动执行这个脚本。db2das用户的设置脚本文件位于/home/db2das/das/dasprofile,同样需要执行这个脚本,才能执行db2admin等命令。用db2ilist命令可以查出当前已创建的实例名。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
6.启动DB2实例
切换到db2das用户,执行db2admin start启动DB2管理服务器。
切换到db2inst1用户,执行db2start启动数据库实例。
root用户也可以执行db2admin start命令。如果首次执行,则会提示如下横线以下信息。一般出现在刚刚用dascrt命令创建das之后。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
7.创建和访问数据库
首先要启动数据库实例,切换到 db2inst1用户,执行db2start命令启动数据库实例。
若需要,首先用db2stop命令停止实例,如果db2stop命令不能成功执行,可运行下面的命令来关闭数据库实例。首先在db2inst1用户下强制关闭实例上的所有应用程序。
$ db2 force applications all
$ db2stop关闭数据库实例。
上述步骤也可以简化为改用db2stop force命令。
启动数据库实例后用db2 create database 命令创建数据库,可以设定字符集、页大小等数据库选项。
数据库创建成功后,可以用db2 connect to命令连接数据库。然后就可以进行创建表、查询等操作了。
如果要尽快测试db2数据库的功能,也可以用命令创建db2自带的sample数据库。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
注意:如果创建数据库时没有指定创建位置,默认创建在/home/db2inst1/实例名下,在此目录下包括系统表空间、用户表空间的数据文件,通常这个目录下的空间不会太大,当需要导入大量数据时,会发生磁盘空间不足的错误,解决方法是在其他目录创建表空间,然后在创建表时指定表空间,或者在数据库关闭状态下,将此目录移动到其他空间足够的目录,再用Linux的ln -s命令将其他位置映射到此目录下。更好的办法是在一开始做好容量规划,将数据库创建目录指定到大容量的目录,具体命令行写法参考文档。软连接的例子如下:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
8.设置DB2自启动
使用root用户执行db2iauto命令,设置对db2inst1实例在 LINUX启动时自动启动。这一步是可选的。用户应该按自己的实际需要决定是否设置。选项-on表示自动启动,-off表示不随操作系统启动自动启动。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
9. 配置网络
DB2软件在创建实例的过程中,自动在操作系统中增加了相关的服务,并指定了相应的端口号。但db2并没有自动设定为通过TCP/IP协议访问,需要手工配置。
首先查看/etc/services中db2各个服务的端口号,这里DB2_db2inst1默认端口就是60000。
切换到db2inst1用户。修改DB2连接方式为TCPIP,然后可通过JDBC、ODBC等访问本DB2服务器上的数据库,安装了DB2客户端的其它机器也可访问数据库。
$ db2set DB2COMM=TCPIP,设定完成后,可以通过不带参数的db2set命令查看结果。
修改DB2的服务端口为上述默认端口号。db2 update dbm cfg using SVCENAME命令提示,需要重新启动实例,再用clpplus命令验证网络设置成功。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
这里的服务名和端口也可以不采用系统自动创建的值,但需要人工额外多一步操作,以root用户利用vi文本编辑器在/etc/services中按如下格式添加一行,保存修改。然后再执行上述步骤,同时db2 update dbm cfg using SVCENAME命令后面要用自定义的服务名。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
因为db2 9.74的clpplus修改了默认运行方式为图形方式,增加-nw参数用于文本方式。如果不加这个参数,则无法在文字终端中使用。
注意:对于需要网络访问,包括jdbc方式访问数据库,这一步必不可少。否则,虽然不影响db2,db2batch等命令在服务器端本地执行,但不能用clpplus这类通过jdbc的命令访问db2数据库。
至此,安装过程结束。
二、DB2功能简介
1. 几个概念
在前面安装配置过程中,我们已经接触到一些DB2数据库的概念,其中有些概念与其它数据库有所区别。下面着重解释一下系统、数据库软件、实例和数据库的关系。
(1) 数据库软件
官方文档中称为DB2 副本,也就是数据库软件的一个拷贝,包括软件安装的二进制可执行文件和其他文件。
可以在单台机器上安装多个DB2 产品。每个DB2 副本可以处于相同代码级别,也可以处于不同代码级别,即不同版本。
DB2 产品的 root 用户安装可安装到您选择的安装路径中。缺省安装路径,对于 Linux 操作系统为:/opt/ibm/db2/V9.7
当缺省安装路径已经在使用时,如果安装一个新的 DB2 副本,那么必须指定安装路径,比如/opt/ibm/db2/V9.7_1。仅在使用“DB2 安装”向导安装 DB2 副本时,缺省路径的序号才会自动递增。无论使用哪种安装方法,都不能将另一个完整产品安装在另一个 DB2 副本所在的路径中(例如,/opt/ibm/db2/V9.7),也不支持安装到现有 DB2 副本的子目录中。
可使用 db2ls 命令可帮助您跟踪已安装的 DB2 产品及其安装路径。运行 db2ls 命令以找到安装在系统上的 DB2 产品。
(2) 实例
实例是逻辑数据库管理器环境,您可以在此环境中对数据库进行编目和设置配置参数。根据需要,可以在同一台物理服务器上创建多个实例,该服务器为每个实例提供唯一的数据库服务器环境。可使用多个实例优化每个实例的数据库管理器配置。并限制实例失败所带来的影响。如果一个实例失败,那么只影响一个实例。其他实例可继续正常运行。
在 Linux操作系统上以非 root 用户身份安装时,在安装 DB2 产品期间将创建单个实例。不能创建其他实例。
对于多个实例来说:
• 每个实例都需要额外的系统资源(虚拟内存和磁盘空间)。
• 由于要管理其他的实例,因此增加了管理工作量。
• 实例目录存储着与一个数据库实例相关的所有信息。实例目录一旦创建,就不能更改其位置。该目录包含:
数据库管理器配置文件
系统数据库目录
节点目录
节点配置文件(db2nodes.cfg)
包含调试信息的其他文件
可以在同一 DB2 副本或不同 DB2 副本中同时运行多个实例。要使用同一 DB2 副本中的多个实例,必须创建所有实例或者将它们升级到同一个 DB2 副本。在对要使用的实例发出命令之前,将 DB2INSTANCE 环境变量设置为该实例的名称。
要阻止实例访问另一实例的数据库,可在与实例同名的目录下为实例创建数据库文件。有关更多信息,请参阅 dftdbpath 数据库管理器配置参数。
要在具有多个 DB2 副本的系统中使用实例,要使用选择的特定 DB2 副本的正确环境变量设置该命令窗口。 方法是从命令窗口中运行db2envar脚本文件。
(3) 数据库
DB2 数据库是关系数据库。数据库将所有数据存储在彼此相关的表中。在这些表之间建立关系,以便可以共享数据并使重复项最少。
关系数据库是被视为一组表并按照关系数据模型操作的数据库。它包含一组用来存储、管理和访问数据的对象。这种对象示例包括表、视图、索引、函数、触发器和程序包。对象可以由系统(系统定义的对象)或用户(用户定义的对象)定义。
分布式关系数据库包含一组表和其他对象,它们分布在不同但内部相连的计算机系统中。每个计算机系统都有一个关系数据库管理器,用于管理其环境中的表。数据库管理器相互间的通信和合作方式允许给定数据库管理器在另一个计算机系统上执行 SQL 语句。
分区关系数据库是在多个数据库分区中管理其数据的关系数据库。这种将数据分布在多个数据库分区中的方式对大多数 SQL 语句来说是透明的。但是,某些数据定义语言 (DDL) 语句会考虑数据库分区信息,例如,CREATE DATABASE PARTITION GROUP。
联合数据库是其数据存储在多个数据源(例如,不同的关系数据库)中的关系数据库。这些数据看起来就像都位于单个大型数据库中一样,并且可以通过传统 SQL 查询来访问。对数据所作的更改可以显式定向至适当的数据源。
从上边的描述可知,一个系统可以包括多个DB2副本,每个副本可以包括多个实例,每个实例可以有多个数据库,通过改变当前环境变量,可以访问某个副本的某个实例下的不同数据库。分布式和联合数据库则是跨数据库访问的。
在我们的主测试环境中,目前只有一个DB2数据库软件,创建了一个实例,实例中创建了默认的sample数据库和兼容Oracle的oracle数据库。
(4) 用户和模式(Schema)
和Oracle不同,DB2没有自己的用户管理系统,db2的用户就是操作系统下的用户。
模式(schema)是用于在数据库中创建的数据库对象的一个高级限定符。它是数据库对象,例如表、视图、索引或触发器的一个集合。它提供了数据库对象的一个逻辑分类。
模式是用来组织数据库中对象的一种方式,可以把它理解为目录。所有同一个目录下的内容属于一个模式,要访问某个对象,就需要同时指定模式名和对象名,可以设定当前目录,那么此目录下的所有对象可以不带模式名访问。
在创建对象时,可以使用模式将这些对象进行分组。一个对象只能属于一种模式。使用 CREATE SCHEMA 语句来创建模式。有关模式的信息保存在连接的数据库的系统目录表中。
要创建模式,并且要使另一个用户成为该模式的所有者(可选),您需要 DBADM 权限。即使您不具有 DBADM 权限,也仍可以使用您自己的授权标识来创建模式。作为 CREATE SCHEMA 语句的一部分创建的任何对象的定义者是模式所有者。此所有者可以授予和撤销其他用户的模式特权。
2.功能与操作
(1)对模式的操作
要通过命令行来创建模式,请输入以下语句:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
其中 是模式的名称。此名称在目录中已记录的模式内必须唯一,并且不能以 SYS 开头。如果指定了可选 AUTHORIZATION 子句,那么 将成为模式所有者。如果未指定此子句,那么发出此命令的授权标识将成为模式所有者。
在删除模式之前,必须删除该模式中的所有对象或将它们移至另一个模式。
使用命令行来删除模式,输入:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
在以下示例中,删除了模式“joeschma”:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
注意:模式默认和同名的用户相关联,比如创建了tpch模式,用tpch用户连接,则自动将当前模式设定为tpch,并自动有权在当前模式下创建对象,但如果用不是模式所有者的其他用户(比如db2inst1)创建了该模式下的对象,则模式所有者tpch无权访问这样的对象,除非tpch也拥有DBADM权限或者让有权限的用户显式授权,这点和Oracle的用户自动拥有模式下表权限有所不同。以下是一个简单的例子。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
(2) 对实例和数据库的操作
开始连接实例之前,必须存在多个实例。
要使用命令行来与实例连接,输入:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
例如,要连接至节点目录中先前编目的称为 testdb2 的实例:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
例如,在对 testdb2 实例执行维护活动后,要使用命令行从实例拆离,输入:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
对于数据库的操作,除了前面提到过的create database和connect to,还有drop database命令删除数据库,terminate命令断开和数据库的连接。
(3)db2命令行工具(CLP)
通过前面的描述,大家对于它已经很熟悉了。它包括单行命令方式和交互方式。在2种方式之间可以共享当前状态,比如db2 connect 连接了数据库,那么db2进入交互方式后不用再次connect,同样在交互方式下设置了set schema当前模式,那么退出交互以后仍然生效。
利用db2工具除了能够执行SQL语句,还可以完成数据库管理参数和数据库参数的动态配置,前者是实例级,后者是数据库级的。方法是:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
比如可以设置分区内并行和增加日志文件的大小。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
(4)db2batch批量测试工具
这个是db2提供的专门用于基准测试的工具,基准测试是从各种不同方面(例如数据库响应时间、cpu 和内存使用情况)对应用程序进行评测的一个过程。基准测试基于一个可重复的环境,以便能够在相同的条件下运行相同的测试。之后,对测试收集到的结果可以进行评估和比较。
db2batch以一组 SQL 和/或 XQuery 语句作为输入,动态地准备语句和描述语句,依次执行每个语句并返回一个报告。取决于命令中的选项,结果集可返回这些语句的执行时间、从准备到查询完成中各个阶段所花费的具体时间,CPU 时间,以及返回的记录关于内存使用情况(例如缓冲池)的数据库管理器快照和缓存信息。
db2batch 命令格式
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
对于执行 db2batch 时一些详细的设置可以通过 -o 参数指定,也可以在 SQL 文件中指定,譬如可以在1.sql文件中使用下面的配置参数:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
其中 ROWS_FETCH 和 ROWS_OUT 定义了从查询的结果集中读取记录数和打印到输出文件中的记录数,PERF_DETAIL设置了收集性能信息的级别,DELIMITER 则指定了多个查询间的间隔符。如果用--#BGBLK和--#EOBLK定义执行块,那么最后的总结报告用块为单位统计,因此,若需要将每个SQL语句重复执行,那么必须在每个语句前后定义块。
执行命令:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
db2batch还允许在输入文件中定义SQL程序块,并且可以定义这个块重复执行的次数,这个功能对于基准测试很有用,可以得出多次执行的平均值,消除一部分偶然性的影响。
由于db2命令行没有提供类似Oracle的sqlplus的set timing on功能。利用显示系统时间,然后计算时间间隔的办法过于复杂,利用date;db2 …;date命令来显示命令执行前后的时间存在着同样的问题。这个工具恰好满足了我们的要求,所以下面的TPCH测试就主要利用这个工具进行。
(5)db2expln执行计划输出工具
这个工具将指定语句的执行计划输出到终端屏幕或一个文件。下面举例说明db2expln命令格式和输出如下:-d指定数据库名,-q是一个SQL语句,也可以用-f指定某个保存了SQL的文件。-u可以指定用户名和口令。-t表示输出到终端,-o可以输出到文件。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
(6) db2 9.7兼容oracle的特性
这是为了熟悉Oracle的用户向db2迁移而设计的功能,号称可以做到百分之几十的代码不需要修改就能在db2中运行原来的Oracle应用,但实际效果还是要亲自使用才知道。
设置步骤
首先要用db2set命令在注册变量中设定兼容模式,然后重新启动实例,再发出create database命令,如果在db2set设定前创建的数据库,则不能完全用到db2兼容Oracle的功能,因为兼容不但需要提供模拟Oracle的命令,还需要创建一系列系统表,比如类似Oracle的dict等数据字典表。兼容oracle的数据库可以用到oracle的一些特有的命令,比如connect by语法。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
这里执行计划的输出速度较慢,好像和SQL查询的时间相当,要快速输出,还是用前面的db2expln工具。
(7)clpplus工具
前面我们已经多次用到了这个工具,从命令名的字面看它就是瞄准Oracle的sqlplus开发的,也是为了方便Oracle的开发人员尽快掌握db2的开发技术,它支持在命令行编辑PL/SQL存储过程或函数,而前面的db2工具是不支持的,还有一些oracle的专用命令,比如set timing on计时,也得到了实现,这样就方便了对SQL的运行计时,但db2的实现离真正的sqlplus还是有区别的,比如对输出SQL语句的执行计划就不能计时,另外,要注意clpplus中只能输入SQL语句,PL/SQL语句和clpplus命令,不能输入db2的命令,比如runstats。工具本身也存在一些问题,比如将代码粘贴到clpplus命令行时,有时候会丢失字符。Db2的兼容oracle的特性也在不断发展中,某些功能在9.72版本中还不具备,到9.74版本就有了,比如数据字典,查看执行计划和set autotrace功能。下载的pdf文档的信息不是最新的,最新的信息还是参考在线文档。
三、TPCH测试
和前几次测试一样,主要测试数据加载和查询性能,也对数据压缩进行测试。
1.准备工作
构造测试环境,首先建立一个名为tpch的模式,并设置它为当前模式。然后执行创建表的脚本。注意tpch原始脚本包含多行,需要在db2命令行中设置-t选项,表示默认以分号而不是回车作为一个SQL语句结束的分隔符。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
2.数据加载
DB2的文本数据文件导入有2种方式,第一种import命令导入,相当于oracle的 sqlldr的常规路径,import工具读入文本文件,按照规则分配到各个列,然后拼成一个INSERT语句执行插入操作,这个命令的优点是出错可以回滚。第二种是load命令装入,类似于Oracle 的sqlldr的直接路径,import工具读入文本文件,按照规则分配到各个列,然后不通过SQL引擎,直接将格式化的页写入数据库。这种方法的优点是避免了语句解释和记录日志的开销,速度比import快,但是不可回滚。因为我们这个测试是一次性的,出错后可以重新再来,因此选用较快的load方式。MESSAGES /tmp/msg.tmp选项表示将导入过程中产生的信息保存到文件,这样可以在出错时查阅这个文件找到出错的数据并改正。
使用load命令需要注意,它默认的列分隔符是逗号,而tpch的dbgen产生的文件的列分隔符是“|”,需要进行转换,这里提供2种方式:
第1种,通过Linux管道命令sed将原始的分隔符进行替换,但是存在一个问题,某些列的内容中包括逗号,这样替换以后,某些记录就有超过列数的逗号,其中有些并不是分隔符,这样导入会产生错误,必须先将原来的逗号替换为其它符号,这样2次替换虽然能成功导入,但导入的数据已经产生变化了。而且全文替换的代价也很大,严重影响导入速度,因此不太可行。如下面的part表,200万行数据用了1分半钟,时间不能令人满意。但是,至少说明一点,load命令是支持命名管道文件导入的。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
第2种,通过load命令提供的modified by coldel选项指定分隔符。更多选项见文档。另外要注意的一点,我们tpch数据文件的分隔符“|”恰好是Linux的管道符,直接使用会报错,这时我们需要用coldel的另一种形式,x加分隔符的16进制ascii码,在这里也就是“X7C”,导入成功,同样200万行只需要3秒钟。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
其它7个表装载的时间分别是13秒、27秒、159秒、3秒、0秒、0秒、0秒,总时间205秒。每分钟装载的数据约3GB,速度较快。
如果因为某种原因,load中断,在下次重新load时需要首先用terminate参数终止上次不成功的操作,然后才能重新装载或作其他操作,否则系统提示错误,拒绝执行操作。
注意默认表空间的创建位置在/home/db2inst1,如果数据量较大,该目录可能会空间不足,这时候需要在其他目录创建表空间,并且把表创建到指定的表空间。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
在某次Load命令提示信息的开始部分,说明了分给DATA BUFFER的内存量限制了并行装载,并行度是3。如果加大,是否能有更好的效果?下面也来测试一下。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
data buffer的取值受限于UTIL_HEAP_SZ,我们看到UTIL_HEAP_SZ已经达到最大值了,因此改变data buffer 设定只能小于上述值,改变为256000对加载速度基本没有影响。可见默认值已经足够了。
3.测试数据和查询语句的产生步骤
主要步骤参照本系列第一篇文章《Oracle 11g R2企业版评测》。然后需要针对db2的特性作修改。
Db2对SQL语句的特殊要求主要有2点:
(1)取前若干行的语法。传统的db2语法不支持rownum伪列,需要修改为分析函数rownumber()over()或用fetch first n rows only子句,其中n是整数,9.7版本开始也支持Oracle的rownum写法。需要按前面描述的步骤启动兼容Oracle模式。
(2)日期间隔的表达式。不支持interval 'n' year/month等写法,要改为 n year/month。
4.数据压缩测试
对表进行压缩有2种方法,一种是在创建表的时候指定压缩属性,再加载数据,另一种是对已经包含数据的非压缩表进行修改压缩属性的操作,然后重新整理表。另外db2也提供了inspect功能,可以预测一个表压缩后的大小,供人作决定前参考。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
从上面表的占用空间可见,对于TPC-H数据,因为dbgen生成的数据比较随机,又是符合第3范式的,冗余较少,压缩的效果不太明显。除了很小的表至少占用一个数据页没有压缩外,平均压缩为原来的1/3,和gzip的压缩率差不多,已经很不错了。
5.数据查询
需要说明的是,虽然TPC-H测试中每个表都有唯一键,表之间有引用关系,TPC-H规范并不要求测试表定义中必须包含主键和外键定义。而允许测试的数据库自行决定。我们在测试过程中发现,如果不创建这些主键和外键,即使做了统计分析,某些查询的时间非常长,估计是优化器没有办法得出良好的执行计划。因此,以下测试均在创建主键和外键后进行。原始tpch脚本dss.ri中创建外键的语法不符合DB2的格式要求,需要做相应的修改。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
为了比较不同条件下的查询结果,我们进行了4种组合的查询。分别是:单进程不压缩,并行不压缩,单进程压缩,并行压缩,每种测试做2遍,取较快的一遍的结果。
测试工具选用db2batch。
虽然理论上也可以用clpplus执行tpch的查询脚本,但目前版本的clpplus在处理%、$等特殊字符方面还有缺陷,因此不完全适用,还是采用db2特有的db2batch工具。在修改完成的包含22个查询语句的sql脚本前端和每个查询前面加上如下参数,就可以方便地进行多次测试。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
执行测试的命令行如下:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
以下是调整过的某次执行的报告。删除了一些多余信息。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
除了第8,9查询语句有错没有执行以外,其余9个查询的时间和输出行数都列举了。
如果是需要强制并行查询,则采用下面的设置。查询优化器自动采用并行查询。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
要查看各查询的时间,在linux下可以用grep命令。在Windows下用find命令。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
下面是各组查询测试结果。(第20个查询在并行查询中无法在可接受的时间内返回结果,测试数据略)
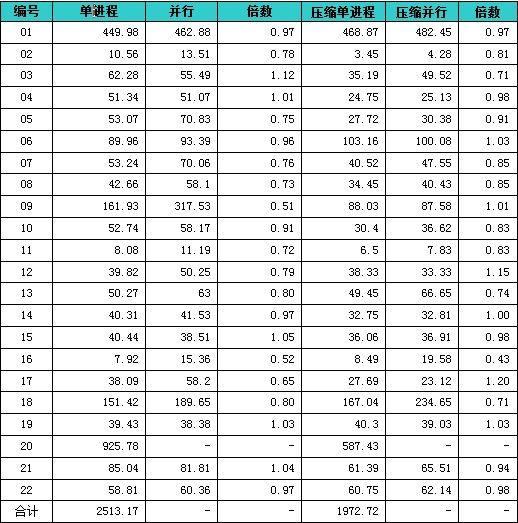
▲表1 TPC-H scale=10未压缩和压缩数据的测试对比,单位:秒
令人惊异的,无论是否压缩,并行查询的速度基本上比单进程都有所降低,有的甚至十余个小时不能查询出结果(第20个查询)。这个结果跟我们的预期相去甚远。用来测试的机器有8个逻辑CPU,基本上发挥不了作用。
从上述数据我们还可以得出单进程和并行分别查询压缩和非压缩数据的差异。
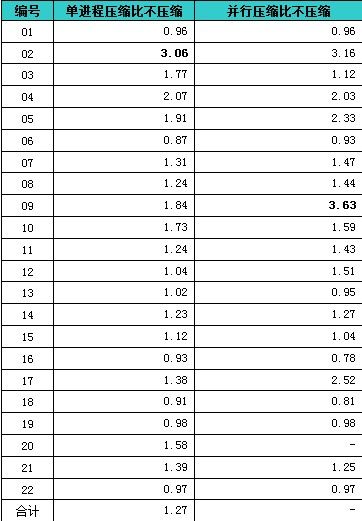
▲表2 TPC-H scale=10压缩前后数据的测试对比,单位:倍
如上表所示,从合计时间看,单进程压缩比不压缩最大提高了2倍,总体大约提高了27%。而并行条件下,最大则有2.6倍的性能提高。从单个查询看,无论是否并行,压缩和不压缩互有胜负,这跟前面我们列出的压缩文件大小有关,如果I/O没有变化或者更大,那么加上解压开销,查询速度下降也是必然的。
6.性能调整和优化
Db2性能调整和优化,涵盖表结构设计、存储方式设计、查询设计、参数调整等方面,前文介绍的压缩和并行都是简单的参数调整手段,如果是实际的查询,而不是基准测试,我们就需要充分利用db2的功能,针对每个查询单独优化。
(1).查询的改写
和Oracle相比,DB2对SQL语句书写的要求比较高一些,这给应用开发人员带来了挑战。比如第20个查询,下面2种逻辑上完全等价的写法,执行效果却是天壤之别,运行时间差不多差了20倍。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
(2). 统计信息收集和管理
正确的统计信息对db2得出较好的执行计划有十分重要的影响,在大量插入或更新数据以后,包括对表进行reorg后,需要重新收集统计信息。
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->
db2也提供了人工添加提示来影响执行计划,这需要相当丰富的db2开发经验。
还有其他的优化手段,比如添加必要的索引,由于时间所限,只测试了给part表添加一个size索引。单表查询的性能提高很大,但在复杂查询中的效果不太明显。有兴趣的读者可以自行检验。
四、小结
经过这次测试,我们对DB2数据库已经有了初步的印象,虽然安装比较复杂,安装包也体积庞大,但功能还是很强大,总体性能也比较好,比如数据文件导入能充分利用硬件资源。其次,数据压缩率对查询性能提高较明显,对某些查询有数倍的提高。另外,测试过程中没有出现数据库意外崩溃的现象。
要说存在的问题,首先,对于TPC-H这种分析型查询,仍然需要利用主外键约束才能产生良好的执行计划,带了额外的时间和空间开销,对SQL书写的要求比较高。其次,一般而言,对具有多个内核的对称多处理器架构(SMP),并行查询会有巨大的优势,但DB2的分区内并行查询还没有见到明显的优势,对硬件的利用率不高。再就是DB2系统的复杂性,安装时系统设定的默认值往往不够用,数百个和性能相关的各种配置参数需要记忆。另外, Unix风格的大量工具,工具有无数的选项,记忆起来也有难度。总体而言,对数据库管理人员的要求还是较高的。
DB2还有很多功能,如分析函数、分区、递归with查询,由于时间所限,没有展开测试。
DB2推出Oracle兼容功能对熟悉Oracle的开发人员是个有吸引力的功能,方便了他们利用已有的知识向db2转移,虽然模仿得不是太完整,基本上完成大部分简单的SQL和PL/SQL开发没有问题,但某些Oracle高级特性还是必须人工改写的。
最后提一下文档和支持,IBM很重视文档的本地化工作,这点很有利于技术人员熟悉他们的产品,在官方技术网站http://www.ibm.com/developerworks/cn/也有大量中文DB2技术文章和入门教材,这些都是很好的学习资源。
总的来说,IBM DB2是一个功能全面,性能均衡,运行稳定的主流商用数据库。而对最终用户来说,本文没有提及的图形化的管理工具也是一个很好的工具,不必手工输入和记忆大量的管理SQL语句,就能监控数据库运行和进行日常维护工作。
- 行式数据库评测:Oracle 11g R2企业版
- 揭秘数据库迁移背后的故事
- 主流NoSQL数据库评测之HandlerSocket
- Win7预载影音本 东芝影音系列搜罗推荐
- 预装Win7更方便 三款Win7超级本大推荐
- Win7操作流畅 戴尔 Dell XPS 14Z大揭秘
- 性能秒杀各类游戏 八款热门游戏本集结
- 1GHz处理器 智能魅族M9现仅售价2039元
- 商务宠儿 三星i809手机现售价3600元