DJango views用法
URLconf技巧
因为urls.py也是一个python文件,所以你可以在这个文件中使用python允许的任何语法。
先看之前介绍的例子:
from django.conf.urls
import patterns, include, url
from books.views import hello, search_form, search, contact, thanks
urlpatterns = patterns( '',
url(r '^hello/$', hello),
url(r '^search/$', search),
url(r '^contact/$', contact),
url(r '^contact/thanks/$', thanks),
)
每一个路径匹配需要导入相应的模块,所以当app的规范越来越大的时候,第二行的import语句
from books.views import hello, search_form, search, contact, thanks
urlpatterns = patterns( '',
url(r '^hello/$', hello),
url(r '^search/$', search),
url(r '^contact/$', contact),
url(r '^contact/thanks/$', thanks),
)
就越长。。。所以可以采用以下几种方法来必定:
1. 只import到模块就可以了,不用写出函数
from django.conf.urls
import patterns, include, url
from books import views
urlpatterns = patterns( '',
url(r '^hello/$', views.hello),
url(r '^search/$', views. search),
url(r '^contact/$', views.contact),
url(r '^contact/thanks/$', views.thanks),
)
2. 使用字符串来代表需要执行的views函数,这里就需要写全路径
from books import views
urlpatterns = patterns( '',
url(r '^hello/$', views.hello),
url(r '^search/$', views. search),
url(r '^contact/$', views.contact),
url(r '^contact/thanks/$', views.thanks),
)
from django.conf.urls
import patterns, include, url
urlpatterns = patterns( '',
url(r '^hello/$', 'books.views.hello'),
url(r '^search/$', 'books.views.search'),
url(r '^contact/$', 'books.views.contact'),
url(r '^contact/thanks/$', 'books.views.thanks'),
)
3. 更简单的字符串写法,需要使用到patterns()的第一个参数
urlpatterns = patterns( '',
url(r '^hello/$', 'books.views.hello'),
url(r '^search/$', 'books.views.search'),
url(r '^contact/$', 'books.views.contact'),
url(r '^contact/thanks/$', 'books.views.thanks'),
)
from django.conf.urls
import patterns, include, url
urlpatterns = patterns( 'books.views',
url(r '^hello/$', 'hello'),
url(r '^search/$', 'search'),
url(r '^contact/$', 'contact'),
url(r '^contact/thanks/$', ' thanks'),
)
以上的方法都是合法的,具体看你选择了。
urlpatterns = patterns( 'books.views',
url(r '^hello/$', 'hello'),
url(r '^search/$', 'search'),
url(r '^contact/$', 'contact'),
url(r '^contact/thanks/$', ' thanks'),
)
因为patterns()返回的对象可以进行加法,当遇到多个views模块的路径前缀时,可以使用如下方式
来统一管理你的路径匹配:
from django.conf.urls
import patterns, include, url
urlpatterns = patterns( 'books.views',
url(r '^hello/$', 'hello'),
url(r '^search/$', 'search'),
url(r '^contact/$', 'contact'),
url(r '^contact/thanks/$', ' thanks'),
)
urlpatterns += patterns( 'weblogs.views',
url(r '^hello/$', 'world'),
)
urlpatterns = patterns( 'books.views',
url(r '^hello/$', 'hello'),
url(r '^search/$', 'search'),
url(r '^contact/$', 'contact'),
url(r '^contact/thanks/$', ' thanks'),
)
urlpatterns += patterns( 'weblogs.views',
url(r '^hello/$', 'world'),
)
使用正规表达式的组操作来向views传递参数
正则表达式可以使用()来表示匹配成功的组,同时可以使用后向引用\1,\2...\n来表示不同的组,
在表达式中代表重复的匹配字串。

不用groups的话,返回的一个match对象。
在python中还可以为组命名,使用(?P<year>\d{4}),意思是这个组的名字为year,匹配的是4个数字
正因为有命名组和不命名组的这两种使用,正好可以以两种方式给view函数传递参数:
1. 不命名组以顺序的方式传值
# views.py
def count( self, a, b) :
....
#urls.py
(r '^num/(\d{4})/(\d{2})/$', count),
#结果
#对于请求/num/1234/78,产生的调用为count(1234, 78)
def count( self, a, b) :
....
#urls.py
(r '^num/(\d{4})/(\d{2})/$', count),
#结果
#对于请求/num/1234/78,产生的调用为count(1234, 78)
2. 命名组以字典的方式传值
#urls.py
(r '^num/(?P<b>\d{4})/(?P<a>\d{2})/$', count),
#结果
#对于请求/num/1234/78,产生的调用为count(b=1234, a=78)
(r '^num/(?P<b>\d{4})/(?P<a>\d{2})/$', count),
#结果
#对于请求/num/1234/78,产生的调用为count(b=1234, a=78)
通过比较,使用命名组有更大的优势,可以让代码一目了然,也不用担心参数的顺序搞错。
还是最好不用混用命名组和非命名组,虽然Django不会报错,但不太好,你懂的。
下面了解一下url匹配的过程:
1. 如果含有命名组,优先采用字典参数
2. 其余的非命名组将会以顺序的方式传递到剩余的参数中
3. url中其它的选项,将会以字典的方式传递
#urls.py
urlpatterns = patterns( '',
#第三个选项值可用来传递一些附加信息,同时可以让请求路径简洁一点
#否则有时候请求链接带太多参数也不太好
(r '^foo/(?P<a>\d{2})$', count, { 'b' : 43}),
)
#结果
#对于请求/num/12,产生的调用为count(12, b=43)
urlpatterns = patterns( '',
#第三个选项值可用来传递一些附加信息,同时可以让请求路径简洁一点
#否则有时候请求链接带太多参数也不太好
(r '^foo/(?P<a>\d{2})$', count, { 'b' : 43}),
)
#结果
#对于请求/num/12,产生的调用为count(12, b=43)
当然,view的函数可以使用默认值,这样,如果请求路径中没有匹配到值的话,会调用默认的值。
注意,一般来说默认值应该设置为字符串,这样是和请求路径匹配过来的值的类型保持一致。因为
它们都是字符串。
即使你匹配的是数学,传入的还是数字的字符串,需要使用int()函数进行转化成
真正的整数。
在这里复习一下,django到底会匹配请求路径的哪一部分?
1. 给定请求路径www.example.com/myapp/foo
只会匹配myapp/foo这个部分
2. 给定请求路径www.example.com/myapp/foo?name=david
只会匹配myapp/foo这个部分
3. 给定请求路径www.example.com/myapp/foo#name=david
只会匹配myapp/foo这个部分
请求路径中也不会包含请求GET还是POST,任何匹配成功的请求,都会运行同一个函数,
但这样做不太好,最好还是对GET和POST采用不同的处理,这里就要用到request对象,
之前也介绍过,它包含了丰富的信息。
def foo(request)
:
if request.method == 'POST' :
#handle post ...
#need to redirect
return HttpResponseRedirect( '/someurl/')
elif request.method == 'GET' :
#handle get
#just return response
return render_to_response( 'page.html')
if request.method == 'POST' :
#handle post ...
#need to redirect
return HttpResponseRedirect( '/someurl/')
elif request.method == 'GET' :
#handle get
#just return response
return render_to_response( 'page.html')
通过路径匹配动态构造view中的函数
上代码:
#views.py
def say_hello( self, person_name) :
print 'Hello, %s' % person_name
def say_goodbye( self, person_name) :
print 'Goodbye, %s' % person_name
#urls.py
urlpatterns = patterns( '',
(r '^say_hello/(\w+)$', say_hello),
(r '^say_goodbye/(\w+)/$', say_goodbye),
)
上面两个函数基本是做同一件事,传入一个人的名字,然后问候一句。
def say_hello( self, person_name) :
print 'Hello, %s' % person_name
def say_goodbye( self, person_name) :
print 'Goodbye, %s' % person_name
#urls.py
urlpatterns = patterns( '',
(r '^say_hello/(\w+)$', say_hello),
(r '^say_goodbye/(\w+)/$', say_goodbye),
)
所以稍微改动一下匹配规则,创建一个动态处理这两件事的一个函数。
#views.py
def greet( self, person_name, greeting) :
print '%s, %s' % person_name
#urls.py
urlpatterns = patterns( '',
(r '^say_hello/(\w+)$', greet, { 'greeting' : 'Hello'}),
(r '^say_goodbye/(\w+)/$', greet, { 'greeing' : 'Goodbye'}),
)
def greet( self, person_name, greeting) :
print '%s, %s' % person_name
#urls.py
urlpatterns = patterns( '',
(r '^say_hello/(\w+)$', greet, { 'greeting' : 'Hello'}),
(r '^say_goodbye/(\w+)/$', greet, { 'greeing' : 'Goodbye'}),
)
可以看到url中的第三个选项值可以传入额外的信息,保持请求路径的简洁。
同时,这个选项值还可以传入model类,使用委托的方式,让你的view函数功能更加动态。
还可以传入模块名称,让你不用把模块名写死在render_to_response函数中。
还有一点需要注意,当命名组的名字和第三个选项值的名字相同时,Django会使用第三个选项值,
因为它的优先级更高。
使用闭包和可变长度参数来重构views函数
这里要用的概念有:
1. 函数对象也可以当参数进行传递
2. 闭包,可以简单的理解为是函数中定义函数
3. 参数中*args代表可变长度元组参数,也叫非关键字参数,**args代表可变长度字典类参数,也叫关键字参数
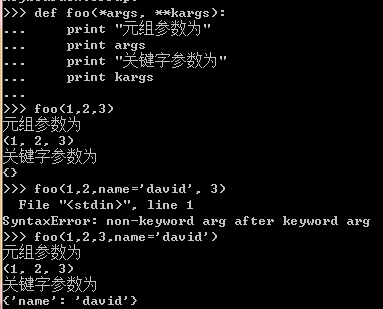
注意报错内容,关键字参数一定要放在最右边
重构例子:
def my_view1(request)
:
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template1.html')
def my_view2(request) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template2.html')
def my_view3(request) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template3.html')
#这上面三个方法,一开始都要进行验证,这有点重复
#下面添加一个新的方法
def requires_login(view) :
def new_view(request, *args, **kwargs) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
return view(request, *args, **kwargs)
return new_view
#使用闭包,定义相同的验证的部分,并返回相应的函数对象,这样就可以
#在上面三个函数中实现自己不同的代码了。可以把验证的部分统统去掉。
#另外urls.py可以改成
from django.conf.urls.defaults import *
from mysite.views import requires_login, my_view1, my_view2, my_view3
urlpatterns = patterns( '',
(r '^view1/$', requires_login(my_view1)),
(r '^view2/$', requires_login(my_view2)),
(r '^view3/$', requires_login(my_view3)),
)
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template1.html')
def my_view2(request) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template2.html')
def my_view3(request) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
# ...
return render_to_response( 'template3.html')
#这上面三个方法,一开始都要进行验证,这有点重复
#下面添加一个新的方法
def requires_login(view) :
def new_view(request, *args, **kwargs) :
if not request.user.is_authenticated() :
return HttpResponseRedirect( '/accounts/login/')
return view(request, *args, **kwargs)
return new_view
#使用闭包,定义相同的验证的部分,并返回相应的函数对象,这样就可以
#在上面三个函数中实现自己不同的代码了。可以把验证的部分统统去掉。
#另外urls.py可以改成
from django.conf.urls.defaults import *
from mysite.views import requires_login, my_view1, my_view2, my_view3
urlpatterns = patterns( '',
(r '^view1/$', requires_login(my_view1)),
(r '^view2/$', requires_login(my_view2)),
(r '^view3/$', requires_login(my_view3)),
)
使用include()引用其它路径配置文件
from django.conf.urls.defaults
import
*
urlpatterns = patterns( '',
(r '^weblog/', include( 'mysite.blog.urls')),
(r '^photos/', include( 'mysite.photos.urls')),
(r '^about/$', 'mysite.views.about'),
)
urlpatterns = patterns( '',
(r '^weblog/', include( 'mysite.blog.urls')),
(r '^photos/', include( 'mysite.photos.urls')),
(r '^about/$', 'mysite.views.about'),
)
一个project有一个总的urls.py,各个app也可以自己建立自己的urls.py,不过都需要使用include()
函数在project的urls.py文件进行注册。这样利用你的项目管理。
可以注意到使用了include的路径的匹配表达式没有加上'$',这是因为Django的机制是
把当前匹配的请求路径的部分去除,剩下的部分传到include所指定的路径配置中进行匹配。
比如一个请求路径/weblog/7000/过来,匹配部分是weblog/7000/,又因为weblog/匹配成功,
就把剩余的部分7000/传入到mysit.blog.urls文件中进行下一步的匹配。
当使用include()的路径匹配中含有正则组的时候,这个匹配的参数会传入对include中所指定的urlconf中
所有的函数里,不管函数是接受这个参数,显然很容易报错,所以这种做法不太好。
同理,如果你在include的路径匹配中使用了第三个选项参数,也会强制传入指定的urlconf中的所有函数中。
也不太好。