看了《深入理解linux内核》的中断与异常,简单总结了下,如果有错误,望指正!
一 什么是中断和异常
异常又叫同步中断,是当指令执行时由cpu控制单元产生的,之所以称之为异常,是因为只有在一条指令结束之后才发出中断(程序执行异常或者系统调用)。
中断又叫异步中断,是由其他硬件设备依照cpu时钟信号随机产生的。
二 高级可编程中断控制器
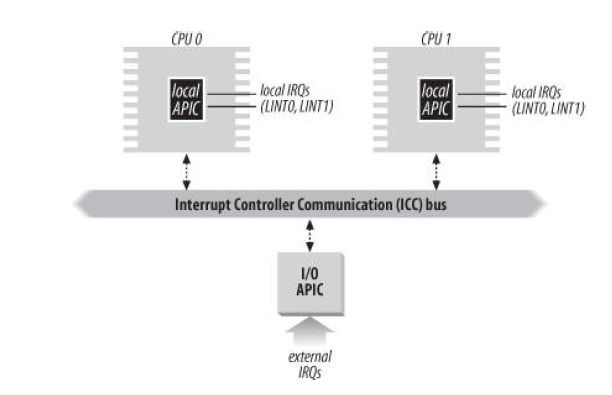
APIC
每个CPU都有一个本地的APIC,通过IIC bus链接到一个I/O APIC,这个I/O APIC负责处理外部IRQS,分发IRQS给本地APIC。
三 中断与异常处理程序嵌套执行
中断处理程序允许被另一个中断处理程序”中断“,从而引起内核控制路径嵌套执行。但是中断处理程序是不允许发生阻塞,即任务切换的。
中断可以抢占异常处理程序,但异常处理程序不会抢占中断。因为中断处理程序必定处于内核态,如果发生异常,那只能是BUG了,也就是说内核控制路径中异常处理程序不会超过一个。
四 Linux中断描述符
Intel把中断描述符分三类:任务门、中断门、陷阱门,而Linux则分成五类:
- 中断门:Intel的中断门,DPL = 0,描述中断处理程序,通过set_intr_gate宏设置
- 系统门:Intel的陷阱门,DPL = 3,用于系统调用,通过set_system_gate宏设置
- 系统中断门:Intel的中断门,DPL = 3,用于向量3的异常处理,通过set_system_intr_gate宏设置
- 陷阱门:Intel陷阱门,DPL = 0,大部分的异常处理,通过set_trap_gate宏设置
- 任务门:Intel任务门,DPL = 0,对”Double fault“异常处理,通过set_task_gate宏设置
五 异常处理
当cpu产生异常时,会自动根据产生的异常编号在IDT中找对应的异常处理程序,异常处理程序保存大多数寄存器的值,调用异常处理的高级C函数处理该异常,然后通过调用ret_from_exception从异常处理程序退出。
六 中断处理
I/O中断处理程序执行的四个基本过程:
- 在内核态堆栈中保存IRQ的值和寄存器的内容
- 给正在为IRQ线服务的PIC发送一个应答,这将允许该PIC进一步发中断
- 执行共享该IRQ的所有设备的中断服务例程(ISR)
七 IRQ数据结构
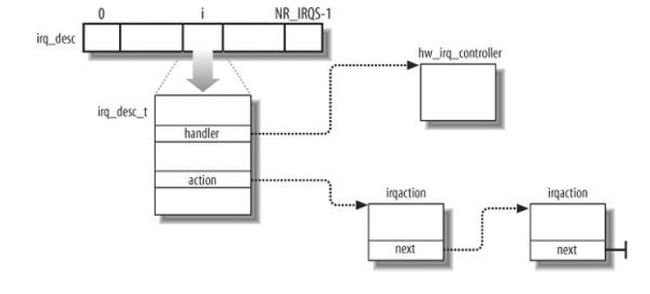
IRQ数据结构
hw_irq_controller是对PIC进程控制的一些函数,包括应答PIC什么的。action指向的是一个irqaction链,每个irqaction描述一个设备的服务例程。irq_desc_t中的state字段保证了同一时刻只有一个设备会拥有该IRQ,正在处理该IRQ的CPU会禁用这条IRQ(本地),其它cpu还是可以接受该IRQ的请求,不过由于此时state的状态为IRQ_INPROGRESS,所以新的IRQ请求会在其它的CPU上应答,但不会处理,也就是该新的IRQ处理会被延迟到处理同一个IRQ的前面一个CPU上执行。能这样做是因为IRQ的数据结构是所有CPU所共享的。
八 多种类型的内核栈
如果编译内核设置内核栈为8k,那么进程的内核栈被用于所有类型的内核控制路径。如果内核栈为4k,则内核使用3种类型的内核栈:异常栈,用于处理异常,每个进程一个;硬中断栈,用于处理中断,每个cpu一个;软中断栈,用于出来延迟函数,每个cpu一个。
九 软中断
1 为什么要引进软中断机制,用前面的中断机制不就可以了吗(老版本的linux就没有软中断机制)?
从前面的中断处理中可以看出,一个中断处理程序的几个中断服务例程(每个设备一个)是串行执行的,如果某个处理例程执行的时间比较长,而后面的例程又很紧急,那么会导致这个紧急的例程汇编延迟比较久的时间。所以如果能把一些服务例程中不是很紧急但又花费比较长的操作延迟到执行完该IRQ上所有中断服务例程之后执行,那么一些紧急的,花费时间短(一般紧急的操作所需的时间都是比较短的)的例程就可以得到快速的响应。还有就是对于某个设备的中断服务例程,如果它的服务例程服务时间过长,cpu在执行该服务例程时是会中断本地cpu对该设备的中断或者整个本地中断,这样会导致很多中断会得不到快速的响应。
2 软中断使用的关键数据结构
softirq_vec数组,每个数组元素类型为softirq_action,该数组总共有32个元素,目前只用了前面六个。softirq_action数据结构包含两个字段:指向软中断处理函数的action指针和指向软中断函数需要的通用数据结构的data指针,这是cpu共享的。
每个进程描述的thread_info字段中的preempt_count字段,该字段被编码来表示三个不同的计数器和一个标志。0-7位表示是否允许抢占内核,8-15表示是否正在处理软中断,16-27表示硬件中断控制路径嵌套数,28为是PREEMPT_ACTIVE标志。每个进程有一个。
另一个是每个cpu都有的32位掩码,存放在irq_cpustat_t数据结构中的__softirq_pending字段,32位,每一位表示softirq_vec数组中的对应的软中断函数是否已激活。irq_cpustat_t存放在irq_stat数组中,每个cpu对于数组中的一个irq_cpustat_t。每个cpu一个。
3 软中断可延迟函数的四个操作
- 初始化,定义一个新的可延迟函数,并加入到softirq_vec数组中,所有cpu共享该softirq_vec。
- 激活,标记一个可延迟函数为”挂起“,通过前面描述的__softirq_pending字段。
- 屏蔽,有选择地屏蔽一个可延迟函数,即使它被激活。它是通过前面的preempt_count字段或者关闭本地中断(延迟函数一般是通过中断处理程序激活的,如果没有中断处理程序执行,自然也就不会有延迟函数的激活)来实现的。
- 执行,执行一个挂起的可延迟函数和同类型的其它挂起的可延迟函数。通过do_softirq实现。
激活和执行可延迟函数必须要在同一个cpu上,从前面激活和执行可以看出这一点。因为__softirq_pending是每个cpu一个,所有在特定cpu激活的延迟函数,只有在该cpu上的__softirq_pending标记激活,而其它cpu是不知道该函数被激活的,也就不会去执行该函数了。
4 linux现有的六种软中断
处理高级优先级的tasklet软中断HI_SOFTIRQ,在softirq_vec数组的下标为0;和时钟中断关联的tasklet软中断TIMER_SOFTIRQ,在softirq_vec数组的下标为1;把数据包传送到网卡软中断NET_TX_SOFTIRQ,在softirq_vec数组的下标为2;从网卡接收数据包的软中断NET_RX_SOFTIRQ,在softirq_vec数组的下标为3;SCSI命令的后天中断处理的软中断SCSI_SOFTIRQ,在softirq_vec数组的下标为4;处理常规tasklet软中断TASKLET_SOFTIRQ,在softirq_vec数组的下标为5;它们的优先级是从高到低的。
5 检查是否有软中断挂起(也叫激活)的时机
- 内核调用local_bh_enable激活本地软中断
- smp_apic_timer_interrupt处理完本地定时中断
- cpu处理CALL_FUNCTION_VECTOR中断处理
- 当一个特殊的ksoftirq/n内核线程被唤醒。
ksoftirq/n内核线程是专门用来处理激活的软中断的,每个cpu有一个。
十 tasklet
tasklet是在软中断的基础上实现的。正如前面说的linux现有的六种软中断,其中HI_SOFTIRQ和TASKLET_SOFTIRQ软中断就是tasklet。
对于每种tasklet(HI_SOFTIRQ和TASKLET_SOFTIRQ),每个cpu都有一个tasklet_head类型来描述这种tasklet。tasklet_head类型指向了一个由tasklet类型组成的链表,而每个tasklet类型描述了该tasklet要执行的函数和函数需要的数据以及tasklet的状态(状态表示同类型的tasklet是否在运行等)。
当do_softirq处理软中断时,如果相应的HI_SOFTIRQ和TASKLET_SOFTIRQ软中断被激活,就会调用对应的软中断函数tasklet_hi_action和tasklet_action。而这两个函数处理的数据正是HI_SOFTIRQ和TASKLET_SOFTIRQ类型tasklet所对应的tasklet_head类型指向的tasklett链表。
为了能够写自己的tasklet函数并加入到对应tasklet类型的tasklet_head指向的链表中,需要调用tasklet_init来初始化新的tasklet和调用tasklet_schedule或tasklet_hi_schedule来把我们自定义的tasklet加入到对应的tasklet_head指向的链表中并激活该tasklet类型所对应的软中断。
所以说tasklet是在软中断的基础上实现的,但不同的是软中断时静态分配的(linux分配了6个软中断),而tasklet是可以动态加入和删除tasklet的。
十一 工作队列
每个工作队列,在每个cpu上都有一个cpu_workqueue_struct结构来描述,即对于同一个工作队列,每个cpu都有该队列的一个拷贝。cpu_workqueue_struct中的worklist成员指向了由work_struct结构组成的链表,这个链表描述的是该工作队列被挂起的函数,等待工作者线程去执行。
通过调用create_workqueue创建工作队列。如果是smp,则每个cpu都会创建一个工作队列和为该工作队列工作的工作者线程。该工作者线程一直阻塞,直到有函数被加入到工作队列中去,工作者线程执行了函数之后就把函数从工作队列中删除。
可以通过queue_work函数把一个函数加入到工作队列中去。
由于仅仅为了一个函数就创建一个工作队列开销太大,所以内核预定义了一个叫events的工作队列,为该队列工作的工作者线程叫events/n,每个cpu一个。还有就是专门为块设备使用的kblocked工作队列。
十二 软中断与工作队列的区别
从上面可以看出,软中断和工作队列十分的相似,都是对服务例程中某些耗时的操延后处理。主要区别在于,软中断的可延迟函数是在中断上下文中执行的,而工作者队列的函数则是在进程上下文中执行的,也就是说软中断的延迟函数执行期间不允许内核被抢占,而工作队列则是可以的。
本文转自:http://www.cnblogs.com/chengxuyuancc/p/3380922.html