简介数据库日志文件的增长
转自:http://blogs.msdn.com/b/apgcdsd/archive/2011/12/30/10251946.aspx
我的数据库只有10GB,为什么我的日志文件有40GB,而且还在增长?
2. 我无法对数据库进行更改操作了。报错说我的日志空间已满。
3. 我数据库的恢复模式明明是Simple,为什么还有日志,还那么大?
4. 我的数据库一直处于恢复状态,其他应用程序都报连接出错。
归根结底一句话,我数据库的日志的增长远远超过我的预期,而导致我的业务受到影响。数据库事务日志(Transaction Log),或简称日志文件(Log)文件的异常增长有时候对数据库的应用的影响是致命的。
想象一下,在你的业务最繁忙的时候,你的数据库由于日志文件占满整个磁盘空间,而无法使用。有人说,很简单啊!我把日志文件删掉。如果你真的这样做,你会发现数据库日志文件正被SQL Server进程锁定,而无法删除。于是,你停止SQL Server服务,然后很开心的将Transaction Log文件删除了,节省了大概200GB的空间。再于是,你很“伤心”的发现你的数据库无法启动,因为缺少日志文件。如果你在日志文件原有的路径创建一个同名的日志文件,好吧,既然你那么坚决,SQL Server会告诉你日志文件格式已损坏。突然,你发现自己有个很好的习惯,当你删除那个200GB的日志文件的时候,你只是把它扔到了垃圾箱,于是你把它找了回来,重新启动你的SQL Server,很开心的发现,它成功的启动了。于是你松了一口气,泡上一杯咖啡,考虑是不是找你的Disk Vendor申请更多的磁盘空间。突然你的电话铃声大作,好多连接到你的数据库的应用程序的管理人员都向你抱怨他们无法连接到数据库。你打开SSMS,发觉那个数据库一直处于“恢复中”(In Recovery)状态���好像它永远不会终止。好吧,你是不是有想砸机器的冲动了,并且想气势汹汹的告诉全世界,这是微软SQL Server的另一个Bug?
如果,你认真的读完这篇文章,你会发现这只不过是SQL Server的另一个不恰当应用的一个案例。
什么是日志文件(Transaction Log)
简而言之,日志文件通过一个简化的格式记录了所有对数据库的修改操作,包括Insert, Update和Delete等能够帮助你重现对数据库内容修改的操作。日志文件的后缀名为*.LDF。
数据文件 (*.mdf)Vs. 日志文件 (*.ldf)
有人本以为数据文件是存储数据的“核心”文件,但是很诧异的发现,原来日志文件存储了所有的数据修改。有些人会想到,通过日志文件,其实我就可以把我的数据库恢复到某个特定时间点的状态。这句话,在某些限制条件下是对的,将在下文进行讨论。
那么,数据文件和日志文件的关系是什么呢?他们如何工作?

SQL Server是一个很依赖于内存(Memory)使用的系统。任何一个对于数据的读入/修改都是和内存进行交互。当一个修改操作发生时,修改的将是内存中所对应的在内存中的数据页。这个操作将会实时地被写入日志文件。但是,该修改被写入数据文件(*.mdf)的时间,只有在以下三种情况下发生:(1)做Checkpoint 时(2)Lazy write运行时(3)Eager write运行时。Lazy write发生在有内存压力时,而Eager write通常发生在bulk insert和select into操作时的。 这里只谈比较普遍的checkpoint情况。
Checkpoint是SQL Server的一个自动的行为。http://msdn.microsoft.com/en-us/library/ms188748.aspx 所以,你的数据文件和日志文件的数据差异间隔会是两个Checkpoint之间的时间差。Checkpoint本身也会被写入日志文件。如果在某些情况下,Checkpoint并没有如预期那样短时间中发生,数据差异间隔会更长。
日志文件如何影响我数据库的启动?
无论你的SQL Server启动,或者你将某数据库重备份中恢复,或者其他的一些情况,总之在你的数据库能够被正常使用之前,你的数据库都会进入 Recovery的状态。http://msdn.microsoft.com/en-us/library/ms190442.aspx 如果这一个步失败,那么你的数据库就会进入Suspect状态而无法正常使用。在一些特殊情况下,这个Recovery所花费的时间会很长。在数据库进入Online状态之前,我们都不能认为SQL Server可以被正常使用了。
那么在Recovery中做了什么呢?
我们可以在你的SSMS中运行如下语句。在运行之前,你可以先按下Ctrl+T来把结果转化成Plain Text格式。
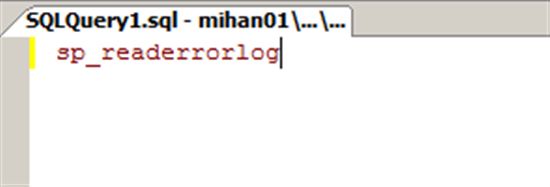
sp_readerrorlog会返回自从最近一次SQL Server服务启动,或者Error Log被回收开始的SQL Server的Error Log信息。这里有两个词汇可能会让你感到疑惑。首先,这里的Log和我们上文所说的日志文件(Transaction Log)中的Log不是一件事情。其次,所谓的Error Log,并不是说这里出现了Error。SQL Server使用这个Error Log记录了很多诊断信息。所以,你可以认为这只是一个普通的记录了很多SQL Server相关信息的日志文件。
![]()
在结果返回中,你可能会找到上面的这些信息。引号中为在你当前数据库实例下的各个数据库名。
![]()
以数据库‘CaseLync’为例。由于Error Log会记录当前SQL Server实例下的所有数据库的相关信息,所以你可能会看到和这个数据库相关的日志被顺序地分布在日志的不同地方。在上图中,第一和第二行提及两个词:rolled forward和rolled back。这两个词和我们本文中所提及的Transaction Log息息相关。
在前文中,我们提到过数据修改的过程:先同步的被写入Transaction Log,然后再Checkpoint发生的时候被同步到Data File里。那么,如果我的事物(Transaction)没有被提交(Commit)或者回滚(Rollback),那么这个数据修改是否也在日志文件(Transaction Log)还是在数据文件里(Data File)?
答案是:都在!
SQL Server在记录数据改变时,并不会区分该语句是否有显示的进行事物操作(Begin Transaction,Commit / Rollback Transaction), 或者该事务是否有完成。SQL Server会忠实地记录所有的修改操作。而Begin Transaction和Commit / Rollback Transaction本身也是日志文件需要记录的操作之一。
由于对于事物日志的修改要先于对于数据文件的修改,所以当你的数据库处于Recovery的状态时,那么Transaction Log就会从最近的一个Checkpoint点开始做如下操作:
1. 如果该操作已在在Transaction Log中,而不在Data File之中,并且如果它使用显式的Transaction操作符而且处于Commit状态,则会发生一次Rolled Forward操作,将该操作同步到Data File之中。
2. 如果该操作已在在Transaction Log中,而不在Data File之中,并且如果它使用显式的Transaction操作符而且处于Rollback Transaction状态,则会发生一次Rolled back操作,将Data File之中的相关数据修改回滚到Transaction发生之前。
3. 如果该操作已在在Transaction Log中,而不在Data File之中,并且如果它使用显式的Transaction在日志文件中即没有Commit操作,也没有Rollback操作,则会发生一次Rolled back操作,将Data File之中的相关数据修改回滚到Transaction发生之前。
4. 如果该操作已在在Transaction Log中,而不在Data File之中,并且如果它没有使用显式的Transaction操作符(Begin Transaction��, 则被认为是一个Rolled Forward操作。
5. 如上步骤都完成后,SQL Server会对该数据库做一个Checkpoint的标识,并写入Transaction Log,表示Data File和Transaction Log已经同步。这表明了数据库的Recovery完成。数据库将进入Online状态,并被正常使用。如果你的数据库在最近的一次Checkpoint到现今的修改操作足够多,在Error Log中也会看到SQL Server用百分比标识Recovery完成的进展。
问题:我的数据库一直处于 In Recovery状态,跑了好几个小时了。
解决方案:好吧,这个说明你的数据库自从上一次的Checkpoint到你现在的这个点对该数据库的修改足够多。这种情况所对应的症状是:
1. 你有个Begin很长时间的Transaction,但是没有Commit/Rollback。
· 如果是这样,慢慢等吧。
2. 你的数据库也许很长时间没有做Checkpoint了。
· 如果是这样,建议你在Performance Monitor检测一下Checkpoint的调用频率。
问题:我已经理解了Recovery的工作模式,但是我真的很急,而且愿意承担Data File和Transaction Log之间的差异。我只是想让我的数据库快点上线。
解决方案:第一件你需要考虑的是三思你是否确实要这样做。虽然也许Data File与Transaction Log之间的差异并非那么多,但是你可能会在你的Data File里留下没有被Commit的数据,从而在逻辑上影响你应用程序的使用。
如果你真的决定那么做,那么遵循以下步骤:
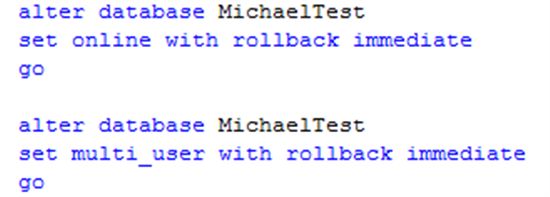
1. 设置单用户,设置紧急状态。

2. 获取Transaction Log的物理名和逻辑名

3. 重建Log
![]()
如何维护事务日志(Transaction Log)
首先我们要理解SQL Server数据库的恢复模式。
SQL Server的数据库恢复模式分为3种http://msdn.microsoft.com/en-us/library/ms189275.aspx :
· Full:完全记录事物日志。可以进行日志备份。
· Bulk-Logged:使用于批量操作的数据库。以更压缩的方式处理日志。可以进行日志备份。
· Simple:无法进行日志备份。意味着你并不在乎日志文件。但是,依然生成数据库日志文件。
虽然,日志文件记录了所有的数据库的更改操作,但是日志文件并非无限增长的,是因为SQL Server会按照一定的规则重用Log Space。
1. 首先,Log是顺序记录的。而来自不同Transaction的对于同一个数据库的Log可能是交错出现。
2. Transaction Log能够申请/释放的空间以Virtual Log File(VLF)为单位。
3. 在同时满足以下条件的前提下,Log Space可以被重用,即被覆盖
a. 最近一次Checkpoint之前。意味着Log File和Data File已经同步。
b. 最早一个Begin而没有Commit/Rollback的Transaction之前的Virtual Log File(VLF)。
c. 满足以上条件的Virtual Log Space被标识为可重用。Full和Bulk-Logged恢复模式的数据库在备份日志时标识。Simple模式的数据库在做Checkpoint时标识可重用。
4. Transaction Log到文件尾以后,如果文件头的Virtual Log File(VLF)可以被重用,则会回溯到文件头。
对于日志文件的重用性,通常会有以下误区:
1. Simple模式下没有日志文件。
· 其实,任何模式下都有日志文件产生。只不过,Simple模式下通过Checkpoint自动地将可以重用的Virtual Log File(VLF)标识为可重用。如果有个很早就Begin Transaction,而忘记被Commit/Rollback,你依然可能看到一个很大的日志文件。
2. 完整备份(Full Backup)会打断日志备份链(Log Backup Chain)。
· 这个问题源自于Log Shipping:在一台做Log Shipping的Primary 机器上,是否可以做Full Backup?答案是可以的。假设你在做初始化的Full Backup1时的LSN是0-100, 其后周期性的Log Backup1, Log Backup2, Log Backup3的LSN分别是101-200, 201-300,301-400。而在做第二个Log Backup时,你在该机器上做了一次Full Backup2的LSN为:0-250。则当你从Full Backup2 开始做Restore过程是这样的:
i. 恢复 Full Backup2:0-250。
ii. 加载/恢复Log Backup2: 201-300. 实际被恢复Log Backup2的LSN:251-300。
iii. 加载/恢复 Log Backup2: 301-400。
· 所以Log Backup2其实包含了完整的日志,但是在上述恢复的例子中,将从251开始恢复。
· Log Backup Chain会在以下情况下被打破。
i. 第一次做Full Backup。
ii. 恢复模式在Full/Bulk Logged和Simple之间进行转换。
3. 如果文件很大(Data File或者Transaction Log File),我通过Shrink来收缩空间。
· 通常,我们并不推荐使用Shrink的方式来进行收缩。因为IO对于SQL Server而言是个非常昂贵的操作。你通过Shrink的方式收缩的磁盘空间,会在下次再次被SQL Server重新申请。而且在很多时候,你使用Shrink能够回收的磁盘空间并不那么理想。所以我们的目标是提高文件的重用性。
所以,对于维护日志来说主要需要注意的是以下几个方面:
1. 对于Full和Bulk-Logged,定期做日志备份。(在此之前最起码有1个完整备份。)两次备份的间隔是你能够容忍数据丢失的时间跨度。
2. Transaction尽可能短而快。避免长时间开启一个Transaction,或者Begin Transaction而忘记Commit/Rollback Transaction的事情发生。
问题:我的日志文件很大,而且收缩不下来。
解决方案:
首先,我们并不赞成通过自动/定期收缩的方式来控制文件的大小。我们建议通过建立良好的维护计划来提高日志文件空间的重用性而达到同样的目的。当然,如果你想把日志文件收缩(Shrink)到一个合理的程度,你可以参考如下步骤。
第一步,你需要查找的是,是否有个开了很长时间的Transaction,但是没有Commit/Rollback?可以通过以下语句查找该数据库下,跑了最长而没有被提交的Transaction。
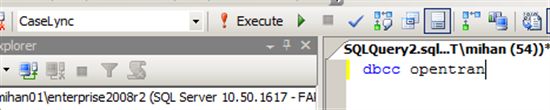
如果有的话,你要么通知那个应用程序的管理人员来Commit/Rollback 这个Transaction。要么在SQL Server这边粗暴的杀死这个Session。下例中,1234为执行这个Transaction的Session ID(SPID)。
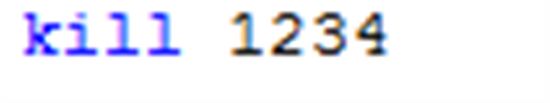
第二步,通过DBCC SQLperf(Logspace)检查Log文件被使用的情况。
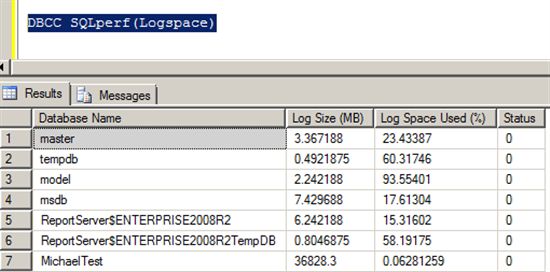
如果数据库的Log Size很大,而Log Space Used(%)相对较小。那么说明有足够可以被收缩的空间。(但是当Log Space Used很大时,也不代表无法收缩足够的空间)
第三步,通过dbcc loginfo检查VLF的使用的情况。

在这里值得关注的是Status列。0 – 可以被Log所使用的VLF。 2- 已被使用,而且无法重用的VLF。通过备份Log的方式,将Status为2的行变成0。此时该空间已可被重用。如果,你真的想要进行日志收缩,可以在这步之后进行。则OS可以回收从最后一个0到最近一个2行的空间。(当前的Status=2的行标识当前的Log记录位置)
总结
其实如果有人问我20GB的Transaction Log大不大。其实这个问题只是个相对概念。理论上只要你有足够的磁盘空间,日志文件可以足够大。如果你有个400GB的数据库,20GB的日志文件也在合理的范畴。如果你的数据库只有5GB,那么你的应用程序对于Transaction的使用和日志的维护一定是有问题了。