Spatial Pyramid Matching for Recognizing Natural Scene Categorie(阅读)
这篇文章要弄清楚需要先对sift,k-means,libsvm有很好了解,才能够很快的理清这篇论文,主要部分:
一、Spatial Pyramid Matching
1. Pyramid Match Kernels
1)假设存在两个特征集合X、Y,其中每个特征x的维度为d。将特征空间划分为不同的尺度![]() ,在尺度
,在尺度![]() 下把特征空间的每一维划出
下把特征空间的每一维划出![]() 个bins,那么d维的特征空间就能划出
个bins,那么d维的特征空间就能划出![]() 个bins(论文中这么描述,但是在实际中是用K-means或BOW进行聚类,得到的每个类中心就是一个bin)。
个bins(论文中这么描述,但是在实际中是用K-means或BOW进行聚类,得到的每个类中心就是一个bin)。
2) 在level(i)中,如果点x,y落入同一bin中就称x,y点Match,每个bin中匹配的点的个数为min(Xi, Yi),其中Xi, Yi代表相应level下的第i个bin。
3)![]() 表示X、Y在level
表示X、Y在level ![]() 下的直方图特征,
下的直方图特征,![]() 表示level
表示level ![]() 中X、Y落入第i个bin的特征点的个数,那么在level
中X、Y落入第i个bin的特征点的个数,那么在level ![]() 下匹配的点的总数为:
下匹配的点的总数为:

在后面![]() 简写为
简写为![]()
4)统计各个尺度下match的总数![]() (就等于直方图相交)。由于细粒度的bin被大粒度的bin所包含,为了不重复计算,每个尺度的有效Match定义为match的增量
(就等于直方图相交)。由于细粒度的bin被大粒度的bin所包含,为了不重复计算,每个尺度的有效Match定义为match的增量![]() ;
;
5)不同的尺度下的match应赋予不同权重,显然大尺度的权重小,而小尺度的权重大,因此定义权重为![]()
6)两个点集X、Y的匹配程度pyramid match kernel为:

2. Spatial Matching Scheme
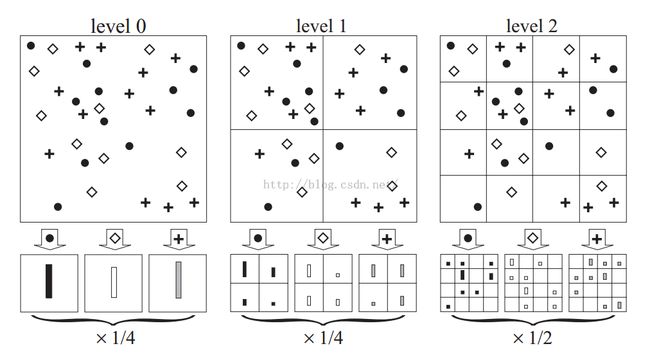
====================================================================
具体实验思路:
Step1 用均匀网格划分图像。
程序中采用8*8像素,即gridwidth=8。比如32*40的图像可画出(32/8)*(40/8)=20个grid。
Step 2 计算特征向量(sift)。
程序中采用16*16的patch(相当于sift中的滑动窗口16*16)计算一个sift描述子特征向量,这样一个patch包括4个grid。一个grid划分为4个bin(相当于4个关键点),每个bin为4个pixel(相当于4个种子),每个种子8个方向,这样一个patch共16*8=128维。然后步长为8的滑动窗进行扫描,这样共有((32-16)/8+1)*((40-16)/8+1)=12个patch。每个patch对应一个128维的描述子,最终这幅图像可以用12个128维的向量表示(12*128)。
Step 3 计算词典。
采用k-means方法构造单词表,即用每幅图像的描述子进行cluster运算,代码中计算的词典vocabulary=200,每个单词为128维向量。
Step 4 计算每幅图像的直方图(VQ)。
每幅图像的描述子(即特征向量)用词典量化,这样一幅图像就可以用12个词来表示,即12*1的矩阵。
Step 5 计算金字塔。
论文中的三层金字塔计算如下。由计算公式![]() (等比数列)算出每幅图像可用4200维的向量表示。式中M为词汇数(200),L为金字塔的层数(2)。
(等比数列)算出每幅图像可用4200维的向量表示。式中M为词汇数(200),L为金字塔的层数(2)。
Step 6 金字塔匹配(SPM)。
主要参考下面这个公式: ,
,

Xm,Ym分别为两幅图像中第m个channel的描述子(descriptor)集合,都是二维的(分别是描述子的横坐标和纵坐标)。一个channel即一种type(码字),对每一个channel做金字塔匹配,最后求和。这幅图片是<The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features> 这个slides里面的。
=====================================================================SPM代码下载:http://www.cs.illinois.edu/homes/slazebni/
参考文献:
1)Lazebnik S, Schmid C, Ponce J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories