Hive-数据仓库
Hive是一个构建在Hadoop上的数据仓库平台,其设计目标是使Hadoop上的数据操作与传统SQL结合,让熟悉SQL编程的开发人员能够轻松向Hadoop平台迁移。Hive可以在HDFS上构建仓库来存储结构化的数据,这些数据是来源于HDFS上的原始数据,Hive提供了类似于SQL查询语言的HiveQL,可以执行查询、变换数据等操作。通过解析,HiveQL语句在底层被变换为相应的MapReduce操作。
Hive组成
Hive的体系结构如图所示。包含shell环境、元数据库、解析器和数据仓库等组件。
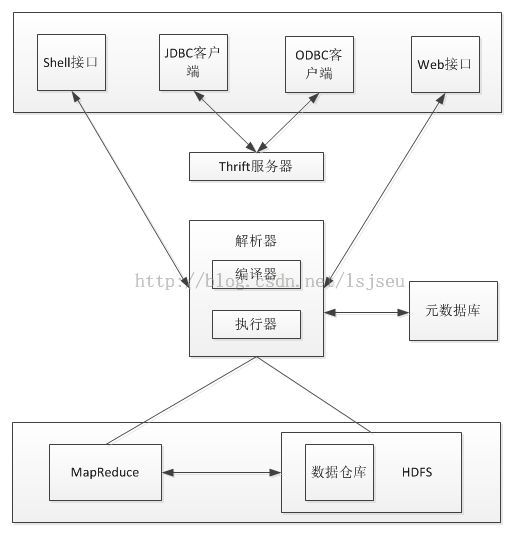
(1)用户接口:包括Hive shell,Thrift客户端,Web管理;
(2)Thrift服务器:当Hive以服务器模式运行时,可以作为Thrift服务器,供客户端连接。
(3)元数据库:通常存储在关系数据库如MySQL、Derby等。 Hive的元数据库中保存了表的属性和服务信息,为查询操作提供依据,默认的元数据库是内嵌的Deby,这种情况下metastore和其他Hive服务运行在一个Java虚拟机里,只允许建立单个会话,要实现多用户多会话支持,需要配置一个独立的元数据库,提供元数据服务。
(4)解析器:包括解释器、编译器、优化器、执行器,通过一系列的处理对HiveQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。查询计划由MapReduce调用执行。
(5)Hadoop:数据仓库和查询计划存储在HDFS上,计算过程由MapReduce执行。
Hive需要的安装软件包:Hive稳定版本,Linux下的MySQL作为元数据库,Hadoop版本。根据metastore的位置可以将Hive的运行模式分为三种:内嵌模式、本地模式和远程模式。安装完成后就可以Hive的shell上执行命令,了解Hive的使用方式和Hive的相关目录。
【注】在用户生成查询的时候,会生成一个MapReduce任务。
HiveQL常用操作
Hive上/user/hive/warehouse目录是Hive的数据仓库目录,每个表对应一个表名命名的目录。目录先存放导入文件、分区目录、桶目录等数据文件。Hive的查询日志默认保存在本地文件系统的/tmp/<user.name>目录下,Hive的MapReduce执行计划保存在本地的/tmp/<user.name>/hive中。这三个目录可以分别通过属性hive.metastore.metadb.dir、hive.querylog.location和hive.exec.scratchdir设置。
MySQL中保存了Hive的元数据信息、包括表的属性、桶信息和分区信息等。以Hive账号登陆MySQL查看元数据信息。在MySQL中这个命名为hive的database是Hive保存元数据的数据库,并不是Hive的数据库。
Hive支持基本类型和复杂类型,基本类型主要有数值型、布尔型和字符型。复杂型有三种:ARRAY、MAP和STRUCT。
(1)创建表
创建表的格式:
Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
Hive中的表可以分为托管表和外部表,托管表的数据移动到仓库目录下,由Hive管理,外部表的数据在指定的位置,不在Hive的数据仓库中,只是在Hive元数据库中注册。下面创建一个托管表,创建一个userinfo表,表中含有两列,列与列以tab键分隔,分别存储用户id(int类型)、用户名字name(string类型)。
create table userinfo (id int, name string)row format delimited fields teminated by '\t';
(2)数据导入
建表后,可以从本地系统或HDFS中导入数据文件。如果数据在HDFS上,则不需要local关键字。托管表导入的数据可以在数据仓库目录user/warehouse/<tablename>中看到。
load data local inpath '/home/dengpeng/1' overwrite into table userinfo;
(3)分区
分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找的数据时就不要扫描整个表,对提高查找速率很有帮助。
create table ptest(userid int) partitioned by(name string)
row format delimited fields terminated by '\t';
load data local inpath 'home/dengpeng/' into table ptest partition (name='jack');
load data local inpath 'home/dengpeng/jack' overwrite into table ptest partition (name='jack');
【注】建立分区以后,会在相应的表目录下建立以分区名命名的目录,目录下是分区的数据。
(4)桶
可以把表或分区组织成桶,桶是按行分开组织成特定字段,每个桶 对应桶redule操作。在建立桶之前设置hive.enforce.bucketing属性为true,使hive识别桶。建立桶之后,要向桶里面插入数据。Hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算方式来选桶,保证每个桶都有数据。
hive.enforce.bucketing = true;
create table btest (id int,name string) clustered by (id) into 3 buckets
row format delimited fields terminated by '\t';
insert overwrite table btest select * from userinfo;
【注】建立桶后,数据仓库下有桶目录,几个桶对应几个目录。
(5)修改表
重命名表名、增加数据列的操作。
alter table userinfo rename to test; alter table userinfo add colunms (grade string);
(6)删除表
对于托管表,drop操作会删除元数据和数据文件,对于外部表,只删除元数据。
drop table test;
(7)连接表
连接是将两个表中在共同数据项上相互匹配的那些行合并起来。HiveQL的连接分为内连接、左向外连接、右向外连接、全外连接和半连接。
(8)子查询
标准的SQL子查询支持嵌套的select子句,HiveQL对子查询的支持很有限,只能在from引导的子句中出现子查询。
(9)创建视图
Hive只支持创建逻辑视图,并不支持物理视图,建立视图后可以在MySQL元数据库中看到创建的视图表,但是在Hive的数据仓库目录下没有相应的视图表目录。
(10)多表插入
多表插入指在同一条语句中,把读取的同一份元数据插入到不同的表中。