python 网络编程
一.DNS 查询IP地址
import sys,socket
result=socket.getaddrinfo(sys.argv[1],None,0,socket.SOCK_STREAM)
counter=0
for item in result:
print "%-2d: %s" % (counter,item[4])
counter+=1

二.IPV6
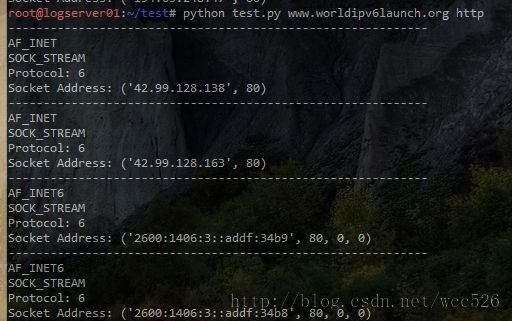
import socket,sys
host,port=sys.argv[1:]
results=socket.getaddrinfo(host,port,0,socket.SOCK_STREAM)
for result in results:
print "-" * 60
if result[0] == socket.AF_INET:
print "AF_INET"
elif result[0] == socket.AF_INET6:
print "AF_INET6"
else:
print result[0]
if result[1] == socket.SOCK_STREAM:
print "SOCK_STREAM"
elif result[1] == socket.SOCK_DGRAM:
print "SOCK_DGRAM"
print "Protocol:" ,result[2]
print "Socket Address:",result[4]
三.Web 访问
urllib2扩展性更好,有更多的内置特性
3.1 获取Web页面
import sys,urllib2
req=urllib2.Request(sys.argv[1])
fd=urllib2.urlopen(req)
while 1:
data=fd.read(1024)
if not len(data):
break
sys.stdout.write(data)
3.2 判断邮箱格式是否正确
def ValidateEmail(email):
if len(email) > 7:
if re.match("^.+\\@(\\[?)[a-zA-Z0-9\\-\\.]+\\.([a-zA-Z]{2,3}|[0-9]{1,3})(\\]?)$", email) != None:
return 1
return 0
四.发送POST消息
#!/usr/bin/python
#coding=utf-8
import urllib
import urllib2,time
def post(url, data):
req = urllib2.Request(url)
data = urllib.urlencode(data)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
return response.read()
def fun(user,pwd):
posturl = "http://www.xxx.com/login.php"
data = {'username':user, 'password':pwd}
ans=post(posturl, data)
print ans
if len(ans)!=17:
print pwd
else:
print len(ans)
if __name__ == '__main__':
fun("myusername","mypassword")
五.调用Google翻译
# -*- coding: utf-8 -*-
import re
import urllib,urllib2
def translate(text):
'''模拟浏览器的行为,向Google Translate的主页发送数据,然后抓取翻译结果 '''
#text 输入要翻译的英文句子
text_1=text
#'langpair':'en'|'zh-CN'从英语到简体中文
values={'hl':'zh-CN','ie':'UTF-8','text':text_1,'langpair':"'en'|'zh-CN'"}
url='http://translate.google.cn/translate_t'
data = urllib.urlencode(values)
req = urllib2.Request(url,data)
#模拟一个浏览器
browser='Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)'
req.add_header('User-Agent',browser)
#向谷歌翻译发送请求
response = urllib2.urlopen(req)
#读取返回页面
html=response.read()
#从返回页面中过滤出翻译后的文本
#使用正则表达式匹配
#翻译后的文本是'TRANSLATED_TEXT='等号后面的内容
#.*? non-greedy or minimal fashion
#(?<=...)Matches if the current position in the string is preceded
#by a match for ... that ends at the current position
p=re.compile(r"(?<=TRANSLATED_TEXT=).*?;")
m=p.search(html)
text_2=m.group(0).strip(';')
return text_2
if __name__ == "__main__":
#text_1 原文
text_1=open('c:\\Users\\nwg\\Desktop\\192.168.210.228.html','r').read()
# print('The input text: %s' % text_1)
text_2=translate(text_1).strip("'")
print('The output text: %s' % text_2)
#保存结果
filename='c:\\Users\\nwg\\Desktop\\my.html'
fp=open(filename,'w')
fp.write(text_2)
fp.close()
report='Master, I have done the work and saved the translation at '+filename+'.'
print('Report: %s' % report)
IMAP访问邮箱
import imaplib
def fun(user,password):
mail=imaplib.IMAP4_SSL('mail.ihep.ac.cn')
try:
mail.login(user,password)
mail.logout()
except imaplib.IMAP4.error,err:
pass