关于大端小端字节序
http://www.cppblog.com/tx7do/archive/2009/01/06/71276.html
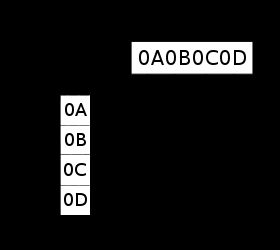
大端Big-Endian
低地址存放最高有效位(MSB),既高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最高有效位(MSB)存放在最低端的地址上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
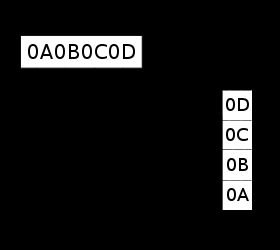
小端Little-Endian
低地址存放最低有效位(LSB),既低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
中端 Middle-Endian
除了big-endian和little-endian之外的多字节存储顺序就是middle-endian,比如以4个字节为例:象以3-4-1-2或者2-1-4-3这样的顺序存储的就是middle-endian。这种存储顺序偶尔会在一些小型机体系中的十进制数的压缩格式中出现。
网络字节序 Network Order
TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
主机序 Host Orader
它遵循Little-Endian规则。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序(Little-Endian)和网络序(Big-Endian)的转换。
C++怎样判别大端小端
使用宏的方法:
方法二:
这里看看网宿的一道笔试题目:
| //假设硬件平台是intel x86(little endian) char *inet_ntoa(uint32_t in) int main() |
对于0x12345678分成4个字节,就是从高位字节到低位字节:12,34,56,78,那么这里该怎么放?如下:
————>>>>>>内存增大
78 56 34 12
因为这个是小端,那么小内存对应低位字节,就是上面的结构。
接下来的问题又有点迷糊了,就是p怎么指向,是不是指向0x12345678的开头——12处?不是!12是我们所谓的开头,但是不是内存
的开始处,我们看看内存的分布,我们如果了解p[0]到p[1]的操作是&p[0]+1,就知道了,p[1]地址比p[0]地址大,也就是说p的地址
也是随内存递增的!
12 ^ p[3]
|
34 | p[2]
|
56 | p[1]
|
78 | p[0]
内存随着箭头增大!同时小端存储也是低位到高位在内存中的增加!
这样我们知道了内存怎么分布了
那么:
sprintf(str,"%d.%d.%d.%d", p[0], p[1], p[2], p[3]);
str就是这个结果了:
120.86.52.18
那么反过来呢? 0x87654321?
依旧是小端,8位是一个字节那么就是这样的啦:
87 ^ p[3]
|
65 | p[2]
|
43 | p[1]
|
21 | p[0]
结果是:
33.67.101.-121
为什么是负的?因为系统默认的char是有符号的,本来是0x87也就是135,大于127因此就减去256得到-121
那么要正的该怎么的弄?
如下就是了:
| int main(int argc, char* argv[]) { int a = 0x87654321; unsigned char *p = (unsigned char *)&a; char str[20]; sprintf(str,"%d.%d.%d.%d", p[0], p[1], p[2], p[3]); printf(str); return 0; } |
用无符号的!
结果:
33.67.101.135