DTMF 编码及解码
首先先说明一下 DTMF 的定义:Dual-Tone Multi-Frequency, 常见的应用就是电话按键的编码及解码. 如电话按键 4 * 4 的矩阵对应表.
由一组低频与一组高频的 SINE 波形相加组成.

我们可以函数来表示:
def sine_sine_wave(f1, f2, length, rate):
s1=sine_wave(f1,length,rate)
s2=sine_wave(f2,length,rate)
ss=s1+s2
sa=numpy.divide(ss, 2.0)
return sa
其中 f1, f2, 分别表示两个频率, length 表示这个 tone 波形的时间, rate 表示采样率(每秒采样的样本点数量)
而 sin_wave 的波形节点可以如下表达:
def sine_wave(frequency, length, rate):
length = int(length * rate)
factor = float(frequency) * (math.pi * 2) / rate
return numpy.sin(numpy.arange(length) * factor)
如 sine_wave(690, 0.2, 44100) 就会得到 8820 个 sine 波形节点.
要生成 tone 的 wave 资料, 建立 digits 对应表 -
dtmf_freqs = {'1': (1209,697), '2': (1336, 697), '3': (1477, 697), 'A': (1633, 697),
'4': (1209,770), '5': (1336, 770), '6': (1477, 770), 'B': (1633, 770),
'7': (1209,852), '8': (1336, 852), '9': (1477, 852), 'C': (1633, 852),
'*': (1209,941), '0': (1336, 941), '#': (1477, 941), 'D': (1633, 941)}
dtmf_digits = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '*', '0', '#', 'A', 'B', 'C', 'D']
以下的函数用于表达一个 tone 集合所产生的波形资料, 每个 tone 产生 0.2 秒, tone与tone 间隔 0.2 秒.
def play_dtmf_tone(stream, digits, length=0.20, rate=44100):
dtmf_freqs = {'1': (1209,697), '2': (1336, 697), '3': (1477, 697), 'A': (1633, 697),
'4': (1209,770), '5': (1336, 770), '6': (1477, 770), 'B': (1633, 770),
'7': (1209,852), '8': (1336, 852), '9': (1477, 852), 'C': (1633, 852),
'*': (1209,941), '0': (1336, 941), '#': (1477, 941), 'D': (1633, 941)}
dtmf_digits = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '*', '0', '#', 'A', 'B', 'C', 'D']
if type(digits) is not type(''):
digits=str(digits)[0]
digits = ''.join ([dd for dd in digits if dd in dtmf_digits])
for digit in digits:
digit=digit.upper()
frames = []
frames.append(sine_sine_wave(dtmf_freqs[digit][0], dtmf_freqs[digit][1],\
length, rate))
chunk = numpy.concatenate(frames) * 0.25
stream.write(chunk.astype(numpy.float32).tostring())
time.sleep(0.2)
为了验证的目的, 以下利用 threading 模块实现即播即录(担心时间上衔接不好, 录长一点, 录10秒)的功能
录音的函数:
def recorder():
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
RECORD_SECONDS = 10
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
return
播放波形声音的函数
def play_tone(digits):
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paFloat32,
channels=1, rate=44100, output=1)
play_dtmf_tone(stream, digits)
stream.close()
p.terminate()
主函数 threading 的应用
if __name__ == '__main__':
threads = []
t = threading.Thread(target=recorder)
threads.append(t)
t.start()
# give some time to bufer
time.sleep(1)
if len(sys.argv) != 2:
digits = "12"
else:
digits = sys.argv[1]
play_tone(digits)
如此即完成 DTMF 编码并生成10秒的 wave 档案.

编码与解码的规则是相应的, 以下用解码的结果来验证编码的算法.
解码:从某些连续段落的波形资料中找到是某两个已定义的高频与低频的组合, 即可对应出 tone digit. 我们使用的是 goertzel 算法,
这个算法的效率比 DFT 或是 FFT 都高. 一组波形资料经过 Goertzel 算法后都会得到该频率的匹配度.
def goertzel_mag(numSamples, target_freq, sample_rate, data):
'''
int k, i
float floatnumSamples
float omega, sine, cosine, coeff, q0, q1, r2, magnitude, real, imag
'''
#floatnumSamples = (float)numSamples
scalingFactor = numSamples / 2.0
k = (int) (0.5 + ((numSamples * target_freq)/sample_rate))
omega = (2.0 * math.pi * k)/numSamples
sine = math.sin(omega)
cosine = math.cos(omega)
coeff = 2.0 * cosine
q0 = 0
q1 = 0
q2 = 0
for i in range(0, (int)(numSamples)):
#print("Hello")
q0 = (coeff * q1) - q2 + data[i]
q2 = q1
q1 = q0
#real = (q1 - (q2 * cosine)) / scalingFactor
#imag = (q2 * sine) / scalingFactor
#magnitude = math.sqrt((real * real) + (imag * imag))
magnitude = (q2*q2) + (q1*q1) - (coeff * q1 * q2)
return magnitude
THRESHOLD = 328 CHUNK = 1024
def IsSilent(samples):
if max(np.absolute(samples)) <= THRESHOLD:
return True
return False
一样是使用编码时所用的 dtmf_freqs, 并定义找到 tone_digit 的函数
dtmf_freqs = {'1': (1209,697), '2': (1336, 697), '3': (1477, 697), 'A': (1633, 697),
'4': (1209,770), '5': (1336, 770), '6': (1477, 770), 'B': (1633, 770),
'7': (1209,852), '8': (1336, 852), '9': (1477, 852), 'C': (1633, 852),
'*': (1209,941), '0': (1336, 941), '#': (1477, 941), 'D': (1633, 941)}
def find_digit(hi, lo):
for key in dtmf_freqs:
if (dtmf_freqs[key][0] == hi) and (dtmf_freqs[key][1] == lo):
return key
回忆一下前面所描述解码的思想 - 连续的段落出现 tone digit, 可以再加上出现的次数即 chunk 数量, 也就是 tone 的波形时间与编码是相互呼应(0.2秒).
于是如下定义 -
NOISE_CHUNK_COUNT = 4 #出现时间太短,需忽略 MAX_CHUNK_COUNT = 16 #满足波形资料0.2秒,若 chunk count 为 30, 代表出现2次
hi_freqs = [1209, 1336, 1477, 1633]
lo_freqs = [697, 770, 852, 941]
if __name__ == '__main__':
sample_rate = 44100
CHUNK_SIZE = 1024
NOISE_CHUNK_COUNT = 4
MAX_CHUNK_COUNT = 16
wav = wave.open('output.wav', 'rb')
n = wav.getnframes()
# n = 440320
# 样本数
print("样本数: %d" % n)
#debug = wav.readframes(1)
c = 0 # 计数
channels = wav.getnchannels()
sample_width = wav.getsampwidth()
chunk_sample_count = (int)(CHUNK_SIZE / channels / sample_width)
digits = [] # 记录digit出现的次数及顺序,每个元素由{digit: count}组成
pre_digit = '' # 记录前一次出现的digit
while(c * CHUNK_SIZE < n * channels * sample_width):
data_chunk_string = wav.readframes(chunk_sample_count)
chunk_data = np.fromstring(data_chunk_string, dtype=np.int16)
if (not IsSilent(chunk_data)):
max_mag_hi_freq = 0
maxvalue_mag_hi_freq = 0
for freq in hi_freqs:
mag = goertzel_mag(chunk_sample_count, freq, sample_rate, chunk_data)
#if c == 277:
# print("(%d)CHUNK %d magnitude with higher frequency (%d) = %f" % \
# (max_mag_hi_freq, c, freq, mag))
if(mag > maxvalue_mag_hi_freq):
maxvalue_mag_hi_freq = mag
max_mag_hi_freq = freq
#if c == 277:
# print("CHUNK %d maximal magnitude located high frequency(%d) " % \
# (c, max_mag_hi_freq))
max_mag_lo_freq = 0
maxvalue_mag_lo_freq = 0
for freq in lo_freqs:
mag = goertzel_mag(chunk_sample_count, freq, sample_rate, chunk_data)
#print("CHUNK %d magnitude with lower frequency (%d) = %f" % \
# (c, freq, mag))
if(mag > maxvalue_mag_lo_freq):
maxvalue_mag_lo_freq = mag
max_mag_lo_freq = freq
#print("CHUNK %d maximal magnitude located (%d, %d) " % \
# (c, max_mag_hi_freq, max_mag_lo_freq))
digit = find_digit(max_mag_hi_freq, max_mag_lo_freq)
# 判断 digit 是否前一次出现过,若是则相对应次数加一, 否则新增元素
digits_element = dict()
if(pre_digit != digit):
digits_element[digit] = 1
else:
digits_element = digits.pop()
digits_element[digit] += 1
digits.append(digits_element)
pre_digit = digit
#print("CHUNK %d: %c" % (c, digit))
c = c+1
wav.close()
for i in range(0, len(digits)):
for k in digits[i]:
if digits[i][k] > NOISE_CHUNK_COUNT:
t = 0
while(t < digits[i][k]):
t += MAX_CHUNK_COUNT
print(k)
测试解码结果:
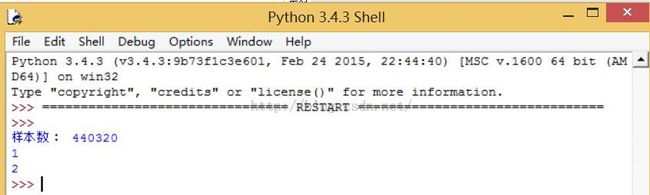
可以看见前面编码的 tone digits. Done. ^_^.